Inversed Index(倒排索引)是搜索引擎的最基本数据结构,比如在 ElasticSearch 中用到,这里记录相关基本概念。
基本概念
- 全文搜索引擎 对非结构化文本进行解析、搜索的技术。非结构化文本的处理关键在于分词和倒排索引
- 格式化文本 例如 xml/json 可以按照某种规则进行解析的文本
- 非结构化文本 日常使用的文章等内容,没有固定格式
- 分词 将一段文本中有用的词汇提取出来的过程
- 倒排索引 通过词搜索到相关网页或文本块的索引
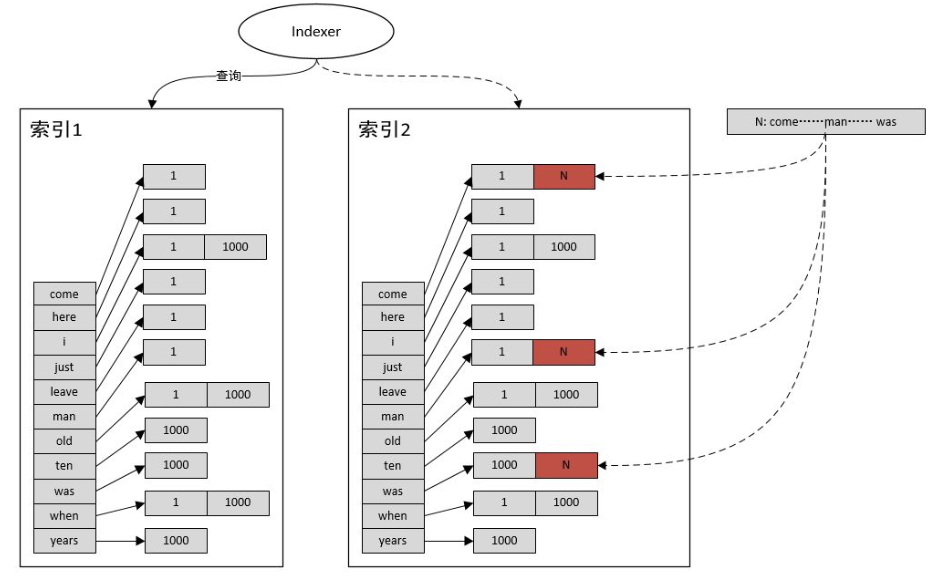
建立、使用倒排索引
-
分词
- 中文的分词一直是分词领域的难点
- 例如:中华人民共和国
- 按语义可分词为:中华 华人 人民 共和 共和国
-
常见中文分词方法:
- Ngram 穷举。如 n=2 时: 中华 华人 人民 民共 共和 和国
- 其中的无效词”民共/合国”再通过词汇表过滤掉
- 语法分析+字典:按中文动名词分析推测外加分词字典维护
- 通常企业内网用这种方式,因为词汇量有限,可以手动维护词典
- 爬虫+大数据 AI 分析:根据语义分析(NLP)、词频、上下文推测筛选(马尔科夫链)
- Ngram 穷举。如 n=2 时: 中华 华人 人民 民共 共和 和国
-
建立索引流程
- 收集相关大量网页,给网页设置 pageID
- 对网页的文本内容进行分词,对每个新词设置 wordID
- 建立一个表,建立 wordID->pageID 的映射关系,同时记录该关系中 page 出现 word 的数量
-
查询流程
- 用户同时输入多个词
- 根据某种搜索算法,例如相似度算法(TF-IDF/BM25)查找词频统计最多的 page,生成一个文章列表
其他
-
pageID 和 wordID 的数量决定了正排索引和倒排索引哪个效率高。
- 例如文字内容比较固定,文章数量比较大,即 wordID count > pageID count 的情况,用正向索引反而快
- 对于 log 搜索场景,pageID count > wordID count(重复词出现多),用倒排索引效率高
-
真正的搜索引擎往往会用到 page rank 算法,随着用户搜索、引用数量增加而提高页面的匹配分数