 记录 K8S 常用概念。
记录 K8S 常用概念。
基础请参考Kubernetes 基础概念
Overview
-
Control Plane The container orchestration layer that exposes the API and interfaces to define, deploy, and manage the lifecycle of containers. You can use finalizers to control garbage collection of resources. The control plane’s components make global decisions about the cluster (for example, scheduling), as well as detecting and responding to cluster events (for example, starting up a new pod when a deployment’s replicas field is unsatisfied).
-
kube-apiserver The API server is a component of the Kubernetes control plane that exposes the Kubernetes API. The API server is the front end for the Kubernetes control plane.
-
etcd Consistent and highly-available key value store used as Kubernetes’ backing store for all cluster data.
-
kube-scheduler Control plane component that watches for newly created Pods with no assigned node, and selects a node for them to run on. Factors taken into account for scheduling decisions include:
- individual and collective resource requirements
- hardware/software/policy constraints
- affinity and anti-affinity specifications
- data locality
- inter-workload interference
- deadlines
-
Controllers In Kubernetes, controllers are control loops that watch the state of your cluster, then make or request changes where needed. Each controller tries to move the current cluster state closer to the desired state.
- When pod state is unexpected, the controller will do Reconcile to the desired state.
-
kube-controller-manager Control plane component that runs controller processes. Some types of these controllers are:
- Node controller: Responsible for noticing and responding when nodes go down.
- Job controller: Watches for Job objects that represent one-off tasks, then creates Pods to run those tasks to completion.
- Endpoints controller: Populates the Endpoints object (that is, joins Services & Pods).
- Service Account & Token controllers: Create default accounts and API access tokens for new namespaces.
-
cloud-controller-manager The following controllers can have cloud provider dependencies:
- Node controller: For checking the cloud provider to determine if a node has been deleted in the cloud after it stops responding
- Route controller: For setting up routes in the underlying cloud infrastructure
- Service controller: For creating, updating and deleting cloud provider load balancers
-
Container runtime The container runtime is the software that is responsible for running containers. like Docker.
-
Kubernetes API The core of Kubernetes’ control plane is the API server. The Kubernetes API lets you query and manipulate the state of API objects in Kubernetes (for example: Pods, Namespaces, ConfigMaps, and Events). Most operations can be performed through the kubectl command-line interface or other command-line tools, such as kubeadm, which in turn use the API. However, you can also access the API directly using REST calls.
-
API groups and versioning To make it easier to eliminate fields or restructure resource representations, Kubernetes supports multiple API versions, each at a different API path, such as
/api/v1or/apis/rbac.authorization.k8s.io/v1alpha1. API groups make it easier to extend the Kubernetes API. The API group is specified in a REST path and in the apiVersion field of a serialized object. You can config API groups by setting flag to API server, like--runtime-config=batch/v1=false -
Kubernetes objects Kubernetes objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of your cluster. A Kubernetes object is a “record of intent”–once you create the object, the Kubernetes system will constantly work to ensure that object exists.
- Deployment an object that can represent an application running on your cluster.
-
Object Spec Describe what state you desire for the object. The precise format of the object spec is different for every Kubernetes object
-
Object Management
- Imperative commands operates directly on live objects in a cluster.
- Imperative object configuration The file specified must contain a full definition of the object in YAML or JSON format.
- Declarative object configuration user operates on object configuration files stored locally, however the user does not define the operations to be taken on the files. Create, update, and delete operations are automatically detected per-object by kubectl.
-
Object Names and IDs Each object in your cluster has a Name that is unique for that type of resource. Every Kubernetes object also has a UID that is unique(UUID) across your whole cluster(history).
- name character count limit 53.
as statefulset pods add a label “controller-revision-hash” which is
10 hash chars + 53 sts name chars, and label character count limit is 63 - must begin and end with an alphanumeric character ( [a-z0-9A-Z] ), could contain dashes ( - ), underscores ( _ ), dots ( . ), and alphanumerics between.
- name character count limit 53.
as statefulset pods add a label “controller-revision-hash” which is
-
Namespaces Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces.
- The Kubernetes control plane sets an immutable label
NamespaceDefaultLabelName, The value of the label is the namespace name.
- The Kubernetes control plane sets an immutable label
-
Labels Labels are key/value pairs that are attached to objects, such as pods. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users, but do not directly imply semantics to the core system. Labels can be used to organize and to select subsets of objects. Labels enable users to map their own organizational structures onto system objects in a loosely coupled fashion, without requiring clients to store these mappings.
- label value character count limit 63(0~63)
- unless empty, must begin and end with an alphanumeric character ( [a-z0-9A-Z] ), could contain dashes ( - ), underscores ( _ ), dots ( . ), and alphanumerics between.
- keys can refer to Annotations
-
Label selectors Unlike names and UIDs, labels do not provide uniqueness. In general, we expect many objects to carry the same label(s).
- two types of selectors:
- equality-based
=,==,!= - set-based
in,notin,exists
- equality-based
- Similarly the comma separator acts as an AND operator.
Set-based requirements can be mixed with equality-based requirements.
For example:
partition in (customerA, customerB),environment!=qa.
- two types of selectors:
-
Set references in API objects Some Kubernetes objects, such as services and replicationcontrollers, also use label selectors to specify sets of other resources, such as pods.
-
Annotations You can use Kubernetes annotations to attach arbitrary non-identifying metadata to objects. Clients such as tools and libraries can retrieve this metadata. You can use either labels or annotations to attach metadata to Kubernetes objects. abels can be used to select objects and to find collections of objects that satisfy certain conditions. In contrast, annotations are not used to identify and select objects. The metadata in an annotation can be small or large, structured or unstructured, and can include characters not permitted by labels. Annotations, like labels, are key/value maps.
- Valid annotation keys have two segments: an optional prefix and name, separated by a slash ( / ). The name segment is required and must be 63 characters or less, beginning and ending with an alphanumeric character ( [a-z0-9A-Z] ) with dashes ( - ), underscores ( _ ), dots ( . ), and alphanumerics between
- The prefix is optional and must be a valid DNS subdomain (such as “company.com”)
- annotation values can be any character
-
Field Selectors Field selectors let you select Kubernetes resources based on the value of one or more resource fields.
=,==,!= -
??? Finalizers Finalizers are namespaced keys that tell Kubernetes to wait until specific conditions are met before it fully deletes resources marked for deletion. Finalizers alert controllers to clean up resources the deleted object owned. You can use finalizers to control garbage collection of resources.
-
Owner references The Job controller also adds owner references to those Pods, pointing at the Job that created the Pods. If you delete the Job while these Pods are running, Kubernetes uses the owner references (not labels) to determine which Pods in the cluster need cleanup. Dependent objects have a metadata.ownerReferences field that references their owner object. Kubernetes sets the value of this field automatically for objects that are dependents of other objects like ReplicaSets, DaemonSets, Deployments, Jobs and CronJobs, and ReplicationControllers.
Workloads
A workload is an application running on Kubernetes. Whether your workload is a single component or several that work together, on Kubernetes you run it inside a set of pods. In Kubernetes, a Pod represents a set of running containers on your cluster.
-
Kubernetes provides several built-in workload resources:
- Deployment and ReplicaSet Deployment is a good fit for managing a stateless application workload on your cluster.
- StatefulSet StatefulSet lets you run one or more related Pods that do track state somehow. For example, if your workload records data persistently, you can run a StatefulSet that matches each Pod with a PersistentVolume.
- DaemonSet DaemonSet defines Pods that provide node-local facilities. Every time you add a node to your cluster that matches the specification in a DaemonSet, the control plane schedules a Pod for that DaemonSet onto the new node.
- Job and CronJob define tasks that run to completion and then stop. Jobs represent one-off tasks, whereas CronJobs recur according to a schedule.
-
Custom Resources Definition(CRD) You can define your own resource based on basic resources.
-
Operators Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop. Kubernetes’ operator pattern concept lets you extend the cluster’s behaviour without modifying the code of Kubernetes itself by linking controllers to one or more custom resources. Operators are clients of the Kubernetes API that act as controllers for a Custom Resource.
Services, Load Balancing, and Networking
-
Kubernetes networking addresses four concerns:
- Containers within a Pod use networking to communicate via loopback.
- Cluster networking provides communication between different Pods.
- The Service resource lets you expose an application running in Pods to be reachable from outside your cluster.
- You can also use Services to publish services only for consumption inside your cluster.
-
Services An abstract way to expose an application running on a set of Pods as a network service.These Pods are exposed through endpoints. Kubernetes gives Pods their own IP addresses and a single DNS name for a set of Pods, and can load-balance across them.
- Supported protocols:TCP UDP SCTP HTTP PROXY
- Discovering services:”environment variables” and “DNS”
-
Topology-aware traffic routing The label matching between the source and destination lets you, as a cluster operator, designate sets of Nodes that are “closer” and “farther” from one another.
-
DNS Kubernetes creates DNS records for services and pods. You can contact services with consistent DNS names instead of IP addresses.
-
Exposing the Service Kubernetes supports two ways of doing this:
- NodePorts
- LoadBalancers
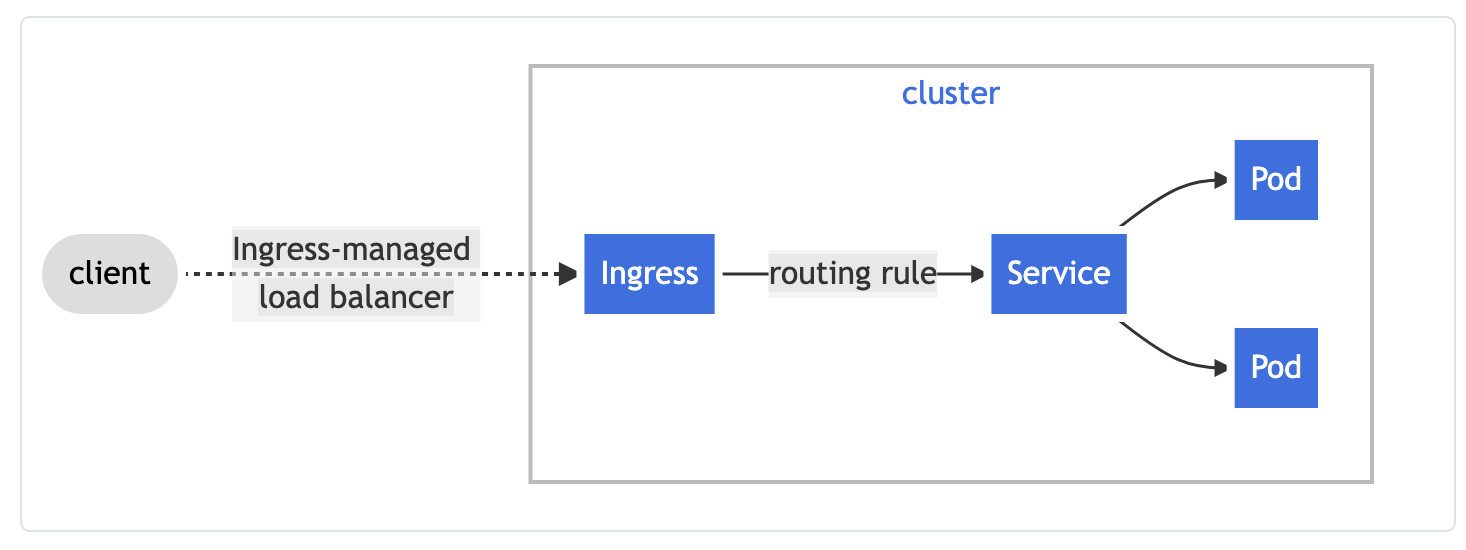
-
Ingress An API object that manages external access to the services in a cluster, typically HTTP. Ingress may provide load balancing, SSL termination and name-based virtual hosting.
-
Ingress Controllers In order for the Ingress resource to work, the cluster must have an ingress controller running.
-
EndpointSlices EndpointSlices provide a simple way to track network endpoints within a Kubernetes cluster. They offer a more scalable and extensible alternative to Endpoints. The control plane automatically creates EndpointSlices for any Kubernetes Service that has a selector specified.
-
Service Internal Traffic Policy Service Internal Traffic Policy enables internal traffic restrictions to only route internal traffic to endpoints within the node the traffic originated from. The “internal” traffic here refers to traffic originated from Pods in the current cluster. This can help to reduce costs and improve performance.
Storage
-
Volume At its core, a volume is a directory, possibly with some data in it, which is accessible to the containers in a pod. Volumes can not mount onto other volumes or have hard links to other volumes. Each Container in the Pod’s configuration must independently specify where to mount each volume.
-
PersistentVolume(PV) It is a resource in the cluster level just like a node is a cluster resource. PVs are volume plugins like Volumes, but have a lifecycle independent of any individual Pod that uses the PV.
-
PersistentVolumeClaim(PVC) PVC is a request for storage by a user. It is similar to a Pod. Pods consume node resources and PVCs consume PV resources.
Task
- Horizontal Pod Autoscaler The Horizontal Pod Autoscaler automatically scales the number of Pods in a replication controller, deployment, replica set or stateful set based on observed CPU utilization (or, with custom metrics support, on some other application-provided metrics). Note that Horizontal Pod Autoscaling does not apply to objects that can’t be scaled, for example, DaemonSets.
API
-
GV GVK GVR
- GV Api Group & Version
- GVK Group Version Kind
- GVR Group Version Resource
-
Role and ClusterRole An RBAC Role or ClusterRole contains rules that represent a set of permissions. Permissions are purely additive (there are no “deny” rules).
- A Role always sets permissions within a particular namespace; when you create a Role, you have to specify the namespace it belongs in.
- ClusterRole, by contrast, is a non-namespaced resource. The resources have different names (Role and ClusterRole) because a Kubernetes object always has to be either namespaced or not namespaced; it can’t be both.
Others
-
The Metrics API Through the Metrics API, you can get the amount of resource currently used by a given node or a given pod.
-
ConfigMap A ConfigMap is an API object used to store non-confidential data in key-value pairs. Pods can consume ConfigMaps as environment variables, command-line arguments, or as configuration files in a volume. (The data stored in a ConfigMap cannot exceed 1 MiB.)
-
Secrets A Secret is an object that contains a small amount of sensitive data such as a password, a token, or a key. Such information might otherwise be put in a Pod specification or in a container image.
-
Requests and limits
- Requests Set the minimum request resources for pod. If no enough resources, pod can not run.
- Limits set the limits of the pod. If exceed the limit memory, OOM will happen.
-
Garbage Collection Garbage collection is a collective term for the various mechanisms Kubernetes uses to clean up cluster resources. This allows the clean up of resources like the following:
- Failed pods
- Completed Jobs
- Objects without owner references
- Unused containers and container images
- Dynamically provisioned PersistentVolumes with a StorageClass reclaim policy of Delete
- Stale or expired CertificateSigningRequests (CSRs)
- Nodes deleted in the following scenarios:
- On a cloud when the cluster uses a cloud controller manager
- On-premises when the cluster uses an addon similar to a cloud controller manager
- Node Lease objects
-
cordon Marking a node as unschedulable prevents the scheduler from placing new pods onto that Node but does not affect existing Pods on the Node. This is useful as a preparatory step before a node reboot or other maintenance.
kubectl cordon $NODENAME -
drain You can use kubectl drain to safely(graceful termination) evict all of your pods from a node before you perform maintenance on the node.
kubectl drain <node name>Once it returns (without giving an error), you can power down the node. If you leave the node in the cluster during the maintenance operation, you need to runkubectl uncordon <node name>resume scheduling new pods onto the node. -
event Event 本身是 Kubernetes 中的一种标准资源,和 Pod、Deployment 一样可以被监听,用于实时获取集群中发生的各类事件(如 Pod 调度失败、镜像拉取成功、节点资源不足等)。
- 核心字段:
- type:事件类型(Normal 表示正常操作,Warning 表示警告 / 错误)。
- reason:事件原因(如 Pulling 表示正在拉取镜像,FailedScheduling 表示调度失败)。
- message:事件的详细描述信息。
- involvedObject:事件关联的资源(如某个 Pod、Node 等)。
- 核心字段: