Log Structured-Merge(LSM) Tree 和 B+ 树相对应,适用于写多读少的 OLTP 数据库,本文介绍其基本数据结构。
应用场景
在 OLTP(Online Transaction Process) 中,MySQL 采用 B+ 树,其特点是可以快速读取数据、支持事务,但其写入性能较差。 而某些 OLAP(Online Analyse Process) 场景中,写入性能要求很高,而读取/修改性能相对要求低,这时可以考虑用 LSM-Tree, 它非常适合保存 Key-Value 类型的数据,因此几乎是 NoSQL 的必选方案 ,事实上 Hbase、Cassandra、Leveldb、RocksDB 在底层都应用了这种数据结构。
基本结构
为什么 LSM-Tree 写入可以这么快?因为它充分利用了”磁盘顺序写入性能高”的特性。
-
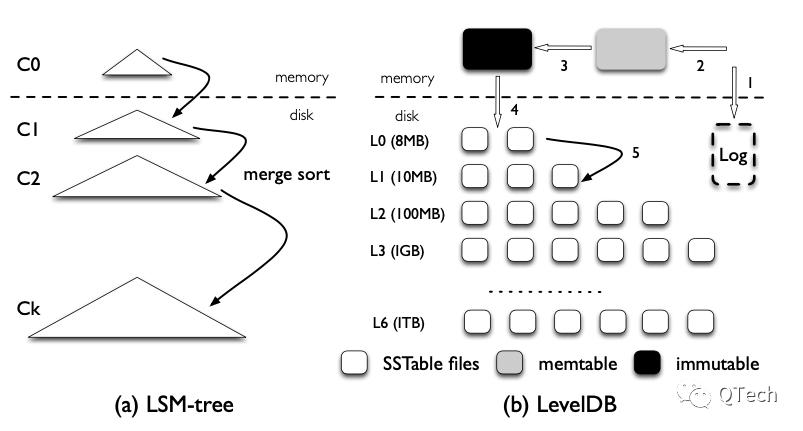
LSM-Tree 基本结构
- 分层
- 最上层是 0 层,完全放在内存中,可以以某种 OrderedMap 形式保存。磁盘上存储 0 1 2 … k 层,以顺序有序的形式保存,其中 0 是直接由内存刷盘得来的。
- 0 层在内存中一般会有两个区域:可变区和只读区,新数据可写入可变区。当需要写入磁盘时,将可变区变为只读区,然后刷盘,同时新建空的可变区继续接收新数据。 当发生 0 层读取时,要先读查可变区再查只读区。
- 磁盘上,同一层可以有多个文件保存,但是 Key 在文件中是有序的。
- 当某层数据量满了时,就要向下一层 Merge,Merge 时会利用元素的有序性,进行 Merge,只要
O(n)的时间和空间复杂度
- 最上层是 0 层,完全放在内存中,可以以某种 OrderedMap 形式保存。磁盘上存储 0 1 2 … k 层,以顺序有序的形式保存,其中 0 是直接由内存刷盘得来的。
- 有序压缩
- 数据在各层存储始终是有序的,这样就方便进行 Merge,无需重新排序
- 同时这种有序的结构,也方便进行二分查找、范围查找,快速查找元素
- 顺序写入
- 在每个变更请求到来时,会先以 WAL(Write Ahead Log)的形式快速写入磁盘,这样避免数据丢失,不影响性能
- 在 Merge 时,由于数据是有序的,可以直接整块的顺序写入硬盘,效率极高
- 由于分层结构,数据可能同时存在于高层和低层,最新数据是在较高层的,所以读取时也要从高到低查找
- 分层
-
辅助结构
- WAL(Write Ahead Log) 预写 Log 是磁盘顺序写入的,比如 MySQL 的 Binlog 等,可以在主机掉电后用于恢复数据。
- 后台 Merge Merge 动作是后台执行的,不影响新数据写入,所以性能不受影响。
- BloomFilter 提高查询效率 由于数据分为多层保存,所以读取数据需要访问多层,效率较低。可以在每层建立一个 BloomFilter 以便快速判断元素是否存在, 虽然存在小概率碰撞问题,但总体效率大大提高了。
相关问题
-
读写放大问题
- 每读 1KB 的数据,需要从磁盘读 10KB 的数据,我们就说放大系数是 10。 由于 LSM 存在多级的情况,所以一次查询就可能访问多层、索引、布隆过滤器,要考虑放大问题。
- 在写数据时,如果引发了 Merge,则同样存在写放大问题。如果下一层容量是上一层的 r 倍,那么单次合并就放大 r 倍。
-
数据删除 数据删除时不会将所有层级全部删除,而是通过 Merge 逐步向下层传递”删除”信息。这样随着最后 Merge 到最后的 k 层时,数据最终被删除了。 中间过程中,被删除的 Key 只会被标记状态为”删除”。