![]()
概念
事务是符合 ACID 特定的一系列操作,分布式事务是在分布式环境下各结点逻辑实现最终一致。 当单机数据库无法满足性能要求时,我们需要拆库并实现跨库事务,这就是分布式事务。
-
难点:
- 数据分布在不同的独立主机上的数据库(如用户、账户、交易三个独立的主机),但是需要实现事务操作,而网络、主机都可能出问题
- 所以需要一个独立的协调者进行事务管理操作,协调各个参与者
-
分布式事务和分布式一致性协议的不同
- 分布式强一致性协议(如 Raft)中 Follower 只是 Leader 的备份,各个 Follower 存储的数据是相同的。 而分布式事务中各个参与者存储的数据是不同的,需要配合完成一个事务。
- 分布式一致性协议要求只要达到 quorumNumber 就算确认完成,而分布式事务必须所有参与者都返回 Commit OK 才可以。
- 在分布式事务中,参与者可以返回中止,即可以影响事务的执行过程;而 Raft 中,Follower 只是投票和记录,不参与流程决策。
-
分布式事务满足 BASE 理论,存在中间的软状态然后实现最终一致,也叫柔性事务
-
分布式事务不可能 100%解决,只能尽量提高成功概率,一般只在特别核心的(比如交易)场景下使用
2PC(2 Phase Commit 两阶段提交)方案
-
在单个主机的数据库可以实现事务,但是如果数据库分布在多台独立主机,那就需要下面流程:
-
基本流程:(假设三台主机分别负责用户、账户、交易)
- 客户端发起一个事务请求
- 事务协调者向三台主机同时发出 Prepare
- 第一阶段(Prepare)的目的是:
- 预留/锁定资源
- 预先校验数据库、缓存中间件
- 第一阶段(Prepare)的目的是:
- 三台主机收到 Prepare 后,各自在数据库开启事务并准备好操作(redo log),然后向协调者返回 OK
- 事务协调者收到三台主机的 Prepare OK 后,发出 Commit
- 三台主机收到 Commit 后,向协调者返回 OK
- 事务协调者收到三台主机的 Commit OK 后,向客户端确认完成本次事务
-
Prepare 出错流程:
- 在 Prepare 阶段,一台主机返回 Error,或者超时没有返回
- 事务协调者向三台主机发出 Rollback
- 两台主机收到 Rollback 后回复 Rollback OK
- 事务协调者收到 Rollback OK 后向客户端确认本次事务失败
-
Commit 阶段重试:
- 在 Commit 阶段,一台主机没有响应
- 事务协调者收到另外两台的 Commit OK,不断重试 Commit
- 直到成功后,事务协调者向客户端确认本次事务成功
-
2PC(XA) 的缺点:
- 数据不一致,Commit 阶段,如果其中一个参与者没能收到 Commit 消息,则系统会出现(Commit 后、Commit 重试 OK 前)数据不一致
- 数据不一致这个问题是不可接受的,破坏了程序的基本逻辑
- 参与者的本地事务在 Prepare 阶段锁定资源,如果有其他事务要修改相同资源,会造成同步阻塞、性能下降
- 比如一个插入动作,会有一个临键锁,将整个表锁住。这种情况在大并发场景下是不可接受的。
- 协调者单点故障,一旦协调者出问题则系统失效
- 协调者一般是调用者的一个组件,并不是独立的服务。但是同样会锁住所有表
- 数据不一致,Commit 阶段,如果其中一个参与者没能收到 Commit 消息,则系统会出现(Commit 后、Commit 重试 OK 前)数据不一致
-
2PC 补偿机制:
- 如果重试仍然不成功,那么需要记录有效日志,由系统定时重试,或者人工介入(比如手动执行脚本回滚)。
-
以前有很多公司用
atomikos开源框架,实现 2PC
3PC
为了解决 2PC 的缺点,引入了三阶段提交
- 将 2PC 的 Prepare 拆分成 canCommit 和 preCommit 两个阶段
- canCommit 与 2PC 的 Prepare 类似
- preCommit 阶段,参与者记录 redolog 后立即返回 OK,但是并没有执行,而是开启一个定时任务
- 协调者发送 Commit 请求,各参与者收到后执行 Commit
-
如果协调者发送的 Commit 有参与者未收到,则根据定时任务,超时后自动执行 Commit
-
3PC 的改进点:
- 如果进入第三阶段 Commit,不论协调者发生故障还是网络异常,参与者都能执行 Commit,避免数据不一致
-
3PC 的缺点:
- 数据不一致如果协调者第三阶段发出 Rollback 请求,而有参与者没有收到,超时后执行了 Commit,则仍然会有数据不一致
- 3PC 增加了一次网络通信,增加了网络延迟代价
- 根据业务进行数据补偿/修正,可以弥补 2/3PC 的缺点
- MQ 事务 利用消息中间件来异步完成事务的后一半更新,实现系统的最终一致性。这个方式避免了像 XA 协议那样的性能问题。
- TCC 事务 TCC 事务是 Try、Commit、Cancel 三种指令的缩写,其逻辑模式类似于 XA 两阶段提交,但是实现方式是在代码层面来人为实现。
XA 协议
XA 协议按照 3PC 方案实现,是由 X/Open 组织提出的分布式事务处理规范,主要定义了事务管理器(TM)和局部资源管理器(RM)之间的接口。 目前主要的数据库,比如 Oricle、DB2、MySQL5.0InnoDB 都支持 XA 协议。
XA 语法
-
按步骤:
XA {START|BEGIN} xid [JOIN|RESUME]三阶段的第一阶段:开启 xa 事务,这里 xid 为全局事务 idXA END xid [SUSPEND [FOR MIGRATE]]结束事务
XA PREPARE xid三阶段的第二阶段,即 PrepareXA COMMIT xid [ONE PHASE]XA ROLLBACK xid三阶段的第三阶段,即 Commit/RollbackXA RECOVER XA RECOVER [CONVERT xid]查看处于 Prepare 阶段的所有事务
- XA 的优点是非侵入式,参与者只是数据库,无需知道具体业务逻辑。
- 对应的缺点是可能造成数据不一致,引起严重逻辑问题
- 由于非侵入式锁粒度较大(锁定整个表的新数据或某条数据),并发性能差
- 所以不适合亿级高并发场景
TCC(Try Commit Cancel)协议
-
TCC 协议按照 2PC 实现,在业务逻辑上增加了中间状态,所以需要各个参与者实现维护这种中间状态的三个 API:Try Commit Cancel 由于其一致性较好,不会发生严重一致性问题,所以广泛用于大厂的亿级微服务架构项目
-
基本流程:
- 协调者发起一个事务,将事务的状态置为”处理中”
- 协调者调用各个参与者的 API(Http/RPC),执行 Try 命令,将资源转移到预留表中,状态置为”处理中”,然后返回 Try OK
- 协调者收到所有 Try OK 后,调用各个参与者的 API,执行 Commit 命令,将资源累加到结果、删除预留内容、状态置为”完成”,然后返回 Commit OK
- 协调者收到所有 Commit OK,就设置事务状态为”完成”
- 如果 Try 阶段有未响应或返回 Fail,则执行 Cancel
-
优点:
- 由于增加了资源预留逻辑,所以事务处理比较独立,无需专门的协调者,可以由微服务实例自己负责,所以比较适合微服务架构
- 逻辑严密,不会发生严重的一致性问题,中间状态可以由补偿机制解决
- 2PC,其中 Try 的过程本身可以检查链路是否可用,所以无需专门用 canCommit 检查,执行效率较高
-
缺点:
- 侵入业务逻辑,需要每个参与者针对一个资源实现三个 API,业务耦合性较大
-
TCC 可以用多种开源框架实现
- tcc-transaction
- ByteTcc
- Seata
-
TCC 和 XA 的 2PC 对比
- TCC 的 Try 操作时,在参与者数据库实际上已经执行了预留逻辑的(数据库)Commit 操作;XA 在 Prepare 阶段是没有 Commit 的,只是锁定,但未数据库 Commit
- TCC 是预留资源,不阻塞数据库;XA 是锁定资源,会造成阻塞。
- TCC 逻辑完整,预留部分不影响整体一致性;XA 在极端情况下,在一段时间内可能会有数据不一致性。
- TCC 故障时,影响范围小,只是自己的事务暂停了;XA 单点故障时会锁定所有表。
补偿机制
分布式事务不可能 100%解决,只能尽量提高成功概率,所以需要补偿机制以完成 100% 的最终一致性。 这里主要以 TCC 协议,描述补偿机制设计点。
-
幂等 首先要保证每个事务的处理是幂等的,重复执行不会引发问题。比如事务要有唯一 ID,这样之后就可以根据这个 ID 判断当前状态决定是否操作。 例如 TCC 中重试 Commit 时,如果是幂等的,则网络延迟引发的重复 Commit 不会引发一致性问题。
-
一般步骤:
- MQ 补偿 发生问题后,如果暂时连不上服务,可以把 Commit/Rollback 放入 MQ,然后自动重试,直到完成或超时
- LOG 补偿 发生问题后,或者MQ 处理超时后,可以将问题输出到 LOG,然后发出报警转人工
- 往往最后有小概率的问题需要人工介入,通过脚本进行操作,完成最终一致性。但是这种概率已经很低了,并不会影响系统整体效率
关于 Seata
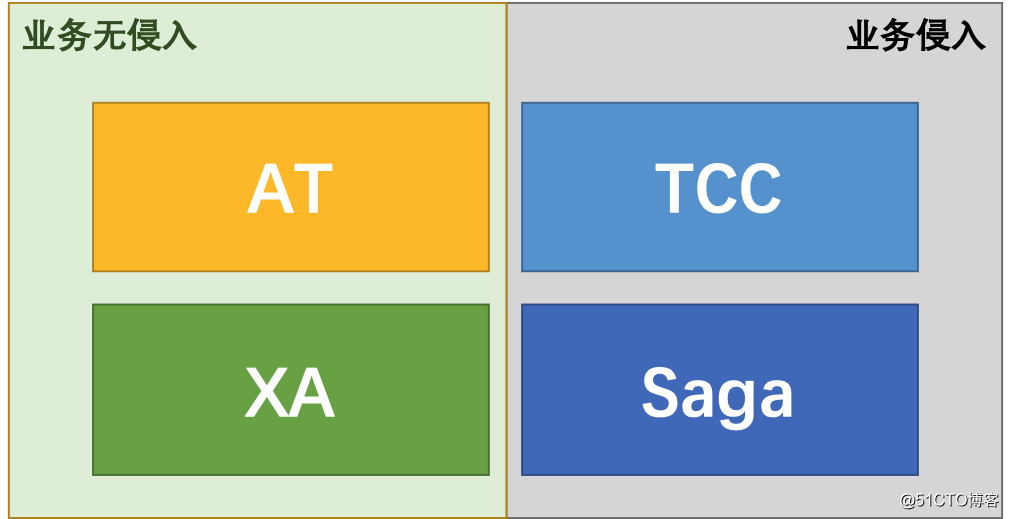 Seata 是阿里推出的一款开源分布式事务解决方案,目前有 AT、TCC、SAGA、XA 四种模式。
Seata 是阿里推出的一款开源分布式事务解决方案,目前有 AT、TCC、SAGA、XA 四种模式。