基本概念
根据CAP Theorem(CAP 定理),分布式系统不能同时满足三点:Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性)
- CP MongoDB、HBase、Redis(MasterSlave 模式)、Zookeeper(ZAB)、Etcd(Raft)
- AP CouchDB、Cassandra、DynamoDB、Riak、Consul(Gossip)、Redis(Cluster 模式, Gossip)
-
CA RDBMS
-
什么是一致性?分为两种:
- 弱一致性
- 最终一致性
- DNS(Doman Name System)
- Gossip (P2P 基础协议,Cassandra 的通信协议)
- 最终一致性
- 强一致性
- 同步
- Paxos
- Raft(multi-paxos)
- ZAB(multi-paxos)
- 弱一致性
-
最终一致性示例: DNS 修改后,不能立即读到,但是经过一系列结点间同步后,最终可以读到正确的值。
- 分布式系统的fault tolorence的一般解决方案是state machine replication(状态机复制), 通过记录带序列号的状态变更 log 的方式同步各个结点的数据。
- Paxos/Raft/ZAB 是目前业内公认的 state machine replication 解决方案的consensus(共识算法)
- 共识算法并不能保证“最终一致性“,还需要 client 行为配合才能实现
分布式强一致性协议的目的
-
可以实现CP
- 如果 Client 读写都在 Leader,则可以保证C。实际上处理也是转发到 Leader 执行的
- 如果发生了各种网络问题(宕机/分区/脑裂),则经过一段时间(主机恢复/重新选举/网络恢复),可以保证P
- 本质上 Follwer 都是 Leader 的备份
-
缺点:
- 由于强一致性中 Leader 是核心结点,所以吞吐存在瓶颈,只适合保存最核心的数据。如 K8S 用 Etcd 存储集群的元数据。
- 如果 Leader 发生问题(断网/宕机),那么在选举期间,整个系统无法对外提供服务。
强一致性共识算法的演化
主从同步
- 结构:
- 一主多从
- 主接收写请求
- 主把变动复制到从
- 主阻塞等待所有从确认后才继续
- 缺点:
- 任意一个从结点失败会导致主被阻塞,虽然保证了一致性,可用性却大大降低。
Quorum(多数派)
- 基本思想:
- 每次写入保证
>N/2个结点写成功 - 每次读取保证从
>N/2个结点读出
- 每次写入保证
- 缺点:
- 在并发情况下,由于任意结点都可写入,可能发生不同结点保存的数据乱序
Basic Paxos
Paxos 算法的发明者是 Lesile Lamport(他也是 Latex 的发明者)。
他同时提出了Basic Paxos、Multi Paxos、Fast Paxos三种方案,
同时用一个虚拟的名叫 Paxos 的希腊城邦的议会民主制度作为示例。
-
角色介绍:
- Client 系统外部角色,请求发起者。比如”民众”。
- Prosper 接受 Client 请求,向集群提出提议(propose)。在冲突发生时,起到调节冲突的作用。像”议员”,替民众提出提案。
- Acceptor(Voter) 提议接收者,负责投票。只有在投票人数达到 Quorum(半数以上)时,提议才会最终被接受。像”国会投票人员”
- Learner 提议接受者,负责 backup,对集群一致性有影响。像”记录员”
-
Basic Paxos 两阶段、四步骤:
- Phase 1a: Prepare Prosper 提出一个提案,编号为 N,N 大于这个 Prosper 之前提出的提案编号。请求 Acceptors 的 Quorum 接受。 此时只是一个提案编号,没有内容。
- Phase 1b: Promise 如果 N 大于此 Acceptor 之前接受的任何提案编号,则接受,否则拒绝。
- Phase 2a: Accept 如果 Prosper 得知达到了多数派,会发出 accept 请求,此请求包含提案编号 N 以及提案内容。
- Phase 2b: Accepted 如果此 Acceptor 在此期间没有收到任何编号大于 N 的提案,则接受此提案内容,否则忽略。
-
通常场景:
- 按照上面执行完毕后,Prosper 会向 Leaner 发送记录请求,Leaner 记录后返回 response。
-
少数 Accepter 失败场景:
- 由于仍然可以达到 Quorum,不影响整个流程。
-
Proposer 失败场景:
- 假设在 Proposer 发起 Prepare 后崩溃,那么编号 N 将不会发出 accept 请求,所以编号 N 不会最终接受。
- 然后另一个 Proposer 可以受理 Client 的请求,重新发起编号为 N+1 的提案,然后正常执行
- 潜在问题:活锁(liveness/dueling) 如果有两个 Proposer,在对方提交新的编号后,自己就提出更大的编号, 导致整个过程始终卡在 Phase1,就形成了活锁
-
解决方案: 如果 Prosper 意识到了活锁,则分别执行 random timeout,其中某方会先发出新的编号,执行完毕后另一方才提新的编号即可。
- Basic Paxos 的问题:
- 实现困难
- 效率低(2 轮通信确认)
- 活锁
Multi Paxos
所谓Multi是指一个角色可以”身兼数职”。
- Multi Paxos 结构变更:
- 增加Leader角色,他是唯一的 Prosper,所有写请求都需经过此 Leader。 在 Leader”任期”内,发出的提案序号是唯一且自增的
- 减少步骤,将
Prepare+Promise过程合并为竞选 Leader的过程,一般只需一次; 然后有数据需写入时,只需要执行Accept+Accepted过程,无需再竞选 - 角色合并,系统内角色只有Server(系统外部是 Client),
Server 可以身兼数职,在
Prosper/Acceptor/Leaner角色间切换
Raft
Raft 是简化版的 Multi Paxos,是业内普遍采用的协议之一,比如 Etcd 就是基于 Raft 协议。
-
参考资料:
-
Raft 将分布式共识算法划分成三个子问题:
- Leader Election
- Log Replication
- Safety(数据一致无错误)
-
Raft 定义的角色:
- Leader
- Follower
- Candidate(临时角色)
// Raft 结点的字段示例
type RaftNode struct {
Toltal uint32 // 结点总数,必须为奇数
NodeID uint32 // 当前结点 ID
Role int // 角色:0-Follower; 1-Leader; 2-Candidate
Term uint64 // 当前所处任期序号,只增不减
CurSeq uint64 // 当前处理的提案序号,在当前任期内只增不减
CurState int // 当前提案状态
VoteCount uint32 // 投票计数,如果是自己发起的,则初始值为 1,过 Quorum 则算成功
}
各种场景测试
-
通常场景:
- 所有角色都是 Follower,各自随机等待一段时间(基础时间+随机时间),然后竞选 Leader
- 如果竞选 Leader 发生冲突Split Vote,则各结点随机休眠然后再选,直到选中唯一的 Leader,开启一个”任期” Term
- 所有 Client 的写请求由 Leader 处理,Leader 发起提案(包含编号和内容),过 Quorum 响应 OK 后,则算写入成功
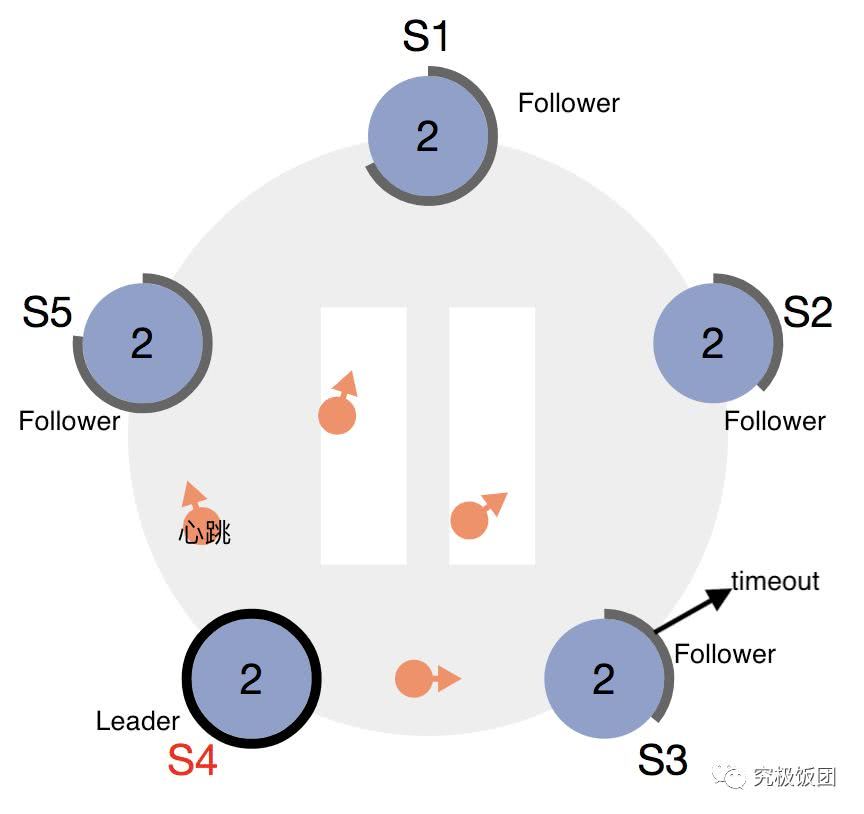
- Leader 持续向 Follower 发送心跳,重置 Follower 的”Term 超时计时器”,以保证维持自己的 Leader 地位。 同时,心跳本身也可以夹带提案和内容。
-
有部分 Follower 失败:
- Leader 发出新提案、少量 Follower 没有响应,由于达到 Quorum 所以写入成功
- 少量 Follower 恢复连接后,发现自己 Term 相同但 CurSeq 落后,则自动更新数据
-
Leader 挂掉:
- Leader 挂掉,不再发送心跳
- 其他 Follower 触发”Term 超时定时器”,将自己角色置为 Candidate,开始选举
- 选定新 Leader,Term++,然后由新 Leader 正常执行新提案
- 旧 Leader 后来恢复连接,发现自己 Term 落后,自动转换角色为 Follower 并更新数据
-
分区 1,Leader 在 Quorum 分区:
- 假设有 5 个结点,其中两个被分区出去
- 剩下的 3 个结点由于 Leader 提案可以达到 Quorum,所以正常运行
- 两个被分区的结点由于没有收到心跳,转换角色为 Candidate 并选举,由于无法达到 Quorum 无法选举成功
- 两个被分区的结点恢复与原网络连接后,发现 Term 相同而 CurSeq 落后,自动转换角色为 Follower 并更新数据
-
分区 2,Leader 在非 Quorum 分区(脑裂):
- 脑裂是指整个网络被划分为两个区域,而这两个区域各自有有一个 Leader
- 假设有 5 个结点,其中两个被分区出去,其中包含 Leader
- Leader 正要处理新提案,所以发出提案 Accept 请求,由于 VoteCount 最多为 2,无法达到 3/5(Quorum),所以循环重试该提案
- 处于另外分区的 3 个结点,由于没有 Leader 心跳,转换角色为 Candidate 并选举
- 由于达到了 Quorum,所以选定新 Leader,Term++,然后执行新提案
- 旧 Leader 所处分区网络恢复后,发现 Term 落后,自动转换角色为 Follower 并更新数据
- 脑裂是指整个网络被划分为两个区域,而这两个区域各自有有一个 Leader
关于”Client 配合实现最终一致性”
- 对于 Client 请求,有三种返回结果:
- OK,写入成功
- Error,系统出错或逻辑错误导致写入失败
- Unknown,请求超时返回、结果未知、需要之后再确认
最开始提到:”最终一致性无法由分布式系统本身实现,在极端情况下,需要客户端配合才可以”,看下面时序:
- 发生 Unknown 的时序:
- 假设有 5 个结点,Client 向 Leader 发出写请求,此时三个 Follower 挂掉了
- Leader 尝试多次提案,无法达到 Quorum,向客户端返回了Unknown
- Leader 继续尝试,这时之前三个挂掉的 Follower 恢复了,达到 Quorum,写入成功
- 过一会儿 Client 来查询,确认自己的请求已经正确完成。(具体客户端的行为需要设计,不一定是”过会儿再查询”)
ZAB
ZAB 是 Zookeeper 使用的协议,基本与 Raft 相同。
-
ZAB 与 Raft 的区别:
- 名称区别: ZAB 将 Leader 的一个周期称为 epoch(纪元),而 Raft 称之为 Term(任期)
- 心跳方向:Raft 的 Leader 向 Follower 发送心跳以保持 Term,而 ZAB 则相反
-
ZK 集群配置要为一个实例设置 4 个端口个:
- client 访问
- leader 和 follwer 间通信
- 选举用端口
- 其他监听
其他
- 关于结点数量
- 结点数量至少是 3 个,这样一个 Leader、两个 Follwer
- 结点过多 Leader 的同步压力过大,会造成系统整体性能瓶颈