 在分布式系统中希望能够生成一个随时间增长的唯一 ID,这时可以用 Snow Flake(雪花算法)实现。
在分布式系统中希望能够生成一个随时间增长的唯一 ID,这时可以用 Snow Flake(雪花算法)实现。
原理
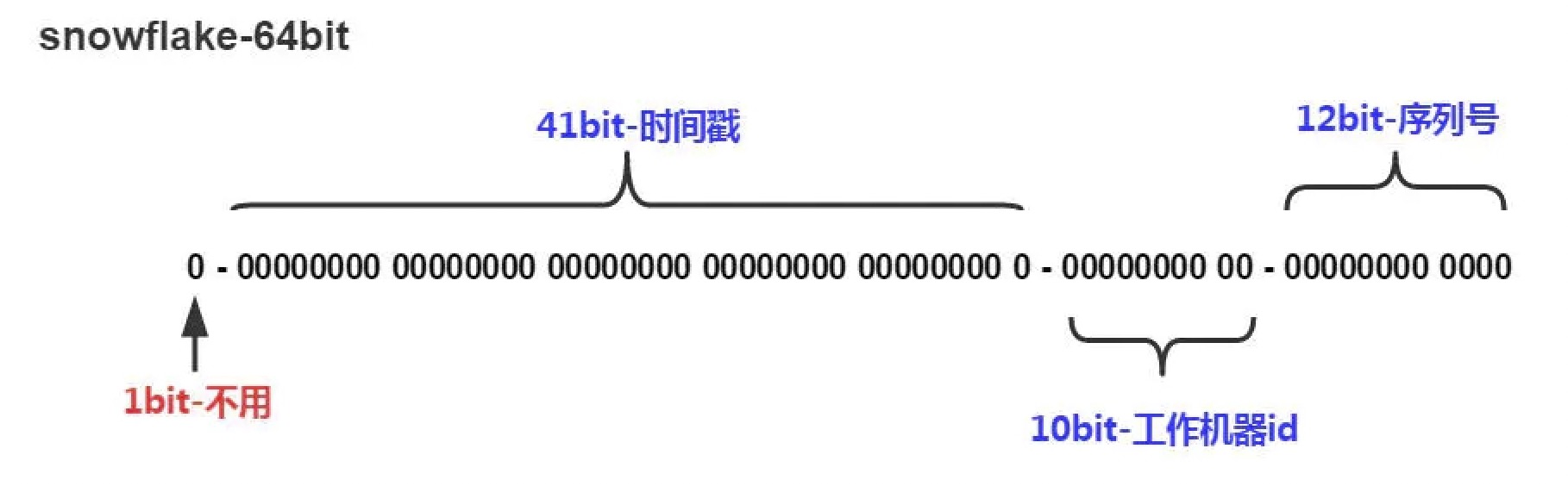
- 41 位毫秒时间戳,可以使用 49 年
- 10 位主机 ID,可以用于 1024 台主机
- 12 位同一毫秒内序列号,可以生成 4096 个 ID
- 最前面的 1 位忽略,因为第一位表示负数所以直接取 0
优点
- 随时间增长
- 不同主机不会重复,支持分布式部署
- 生成简单,只需要取时间戳和位运算
缺点
-
严重依赖服务器时钟,一旦时钟回拨则会导致 ID 重复
-
注意如果客户端生成 ID,一定要在客户端启动时从服务端获取当前时间然后计算时间差, 在生成 ID 时通过客户端当前时间和时间差推算服务端时间取得 ID。 因为客户端当前时间往往不准确,但是时间差是可以保持正确的。
解决回拨的方案
各种解决方案普遍会根据情况调整时间戳、workerID、序列号的高低位置和位数
UidGenerator(java)
UidGenerator 是百度开源的唯一 ID 生成器,它有两个具体实现,分别以不同方式处理时间回拨。
-
首先在数据库插入 worker 信息时,以自增主键做 workerID,这样保证主机 ID 唯一
-
解决时间回拨:
- DefaultUidGenerator 缩短时间戳位数,只保持秒级时间,这样减少由于时间修正引起的回拨问题。 一旦发生回拨,直接抛出异常
- CachedUidGenerator
不依赖系统的
System.currentTimeMillis()来获取时间,直接利用AtomicLong.incrementAndGet()方法获取下一个时间。 这样的好处是时间不会回拨,缺点是对 ID 解析出的时间和实际时间对不上。
Butterfly 开源框架(java)
Butterfly 方案对分布式 ID 生成的三个问题都有较好解决:时间回拨问题、机器 id 的分配和回收问题、机器 id 的上限问题
- 解决时间回拨:
- 使用”历史时间”而不直接使用系统时间。 当系统启动时,记录最新系统时间戳并延迟 10ms 后开始运行。 运行时持续使用自己维护的时间戳,每当序列号满时,时间戳增 1,也就是 1ms。 在生成 ID 时,要求当前的时间戳不能超过系统的时间戳,只能使用”历史时间”,这样与系统时间脱钩,能满足通常场景。
- 在极端并发情况下,序号快速用完,导致历史时间戳快速追上真实时间,这种情况下就要等待一会儿,会阻塞响应。
- 如果发生系统时间回拨,而导致系统时间小于历史时间,这种情况也要等待,会阻塞响应。
- 通过上面方案,可以较好的解决回拨、并发问题。缺点和 CachedUidGenerator 一样,时间戳部分可能和实际时间对不上。
- 解决机器 id 分配及回收:
- 业内普遍有两种方案:用 ZK 顺序临时结点,解决了回收问题,但是临时结点不可靠;用 DB 自增主键解决了分配问题,但没有解决回收。
- Butterfly 两种方案:
- ZK 方案
- 在 ZK 用 hash 的方式添加永久结点,同时结点保存超时时间
- 机器结点要定时更新超时时间以保持结点有效
- 可以通过 hash+超时时间 判断结点是否有效
- 默认有 16 个结点(4 个二进制位表示),如果容量不足,则类似 map 的处理方式翻倍扩容
- DB 方案
- 在表中除了主键增加一个超时时间字段,同样通过心跳维护超时时间
- 判断结点状态时可以利用查询语句进行过滤
- ZK 方案
- 解决机器 id 上限:
- 单机形式无法解决,可以用服务器集群提供 workerID
思考
- 如果不需要随时间增加,用 UUID 就可以