map
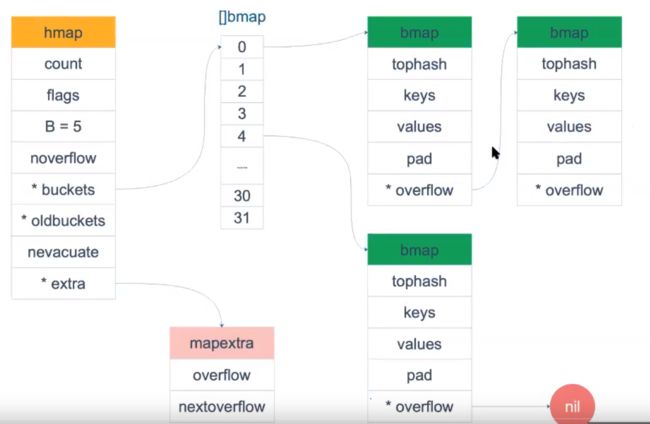
hmap 结构体
type hmap struct {
count int // 当前保存元素个数
B uint8 // 创建桶的个数为 2 的 B 次方
flags // 并发操作标志
hash0 // hash 因子,用于生成 hash 值
buckets unsafe.Pointer // bucket数组指针,数组的大小为2^B
}
bmap 结构体
type bmap struct {
tophash [8]uint8 // 存储哈希值的高8位
data byte[1] // key value数据:key/key/key/.../value/value/value...
overflow *bmap // 溢出 bucket 地址(拉链法)
}
-
基本结构:
- hmap 就是我们操作的 map 对象
- hmap.buckets 指向 bmap 数组,其中的元素是bucket,每个 bucket 可以存放 8 个元素
- hmap.buckets 指向的是标准桶,而 bmap.overflow 可以形成溢出桶链,当标准桶内放不下时,会新建溢出桶并将元素存放到溢出桶
- 利用 hmap.B 可以判断总的桶数
- 利用 bmap.tophash 可以快速判断某元素是否存在、在 data 中的偏移量在哪
-
写入流程:
- 将输入的 key 结合 hashmap.hash0 生成 hash 值
- 根据 hash 值低 B 位判断 key 应归属的桶下标(
hash值 & B) - 桶中的元素是顺序存放的,放满一个再放下一个,如果都满了,则创建溢出桶存放
- 把 hash 值的高 8 位,存储在 tophash;把 key、value 按照顺序的偏移量放在 data 中
- hmap.count++
-
查找流程:
- 将输入的 key 生成 hash 值
- 根据 hash 值的低 B 位计算 key 归属的桶下标
- 在桶中通过 tophash 快速判断是否存在
- 如果本桶不存在则查找溢出桶
- 如果 tophash 相同,则比较 key 值,找到目标元素;如果都没找到,则元素不存在
-
倍增扩容
- 负载因子 6.5,当
count/(2^B) > 6.5则翻倍扩容 - 倍增扩容时,遍历旧桶元素,重新分配到新桶的低或高位,使用
B+1位区分 - 迁移过程,Golang map 的扩容不是一次完成的,而是扩容之后再逐步迁移数据 分别记录旧桶、新桶、当前扩容桶序号,然后在每次 map 操作时检查当前是否为扩容中,如果在扩容中,则每次处理一个旧桶,直到扩容结束。 扩容过程新值写入新桶中
- 负载因子 6.5,当
-
等量扩容
- 如果
B<15 && 溢出桶数量>常规桶数量或B>=15 && 溢出桶数量 > 2^15则触发等量扩容 - 往往等量扩容时没有达到负载因子而溢出桶数量很大,这种情况是因为溢出桶中被删除了很多元素导致排列不紧密。 重新等量扩容,在迁移时会重新排列元素、删除多余溢出桶,有助于将桶内元素重新紧凑排列。
- 如果
-
线程安全:
var counter = struct{
sync.RWMutex
m map[string]int
}{m: make(map[string]int)}
sync.Map
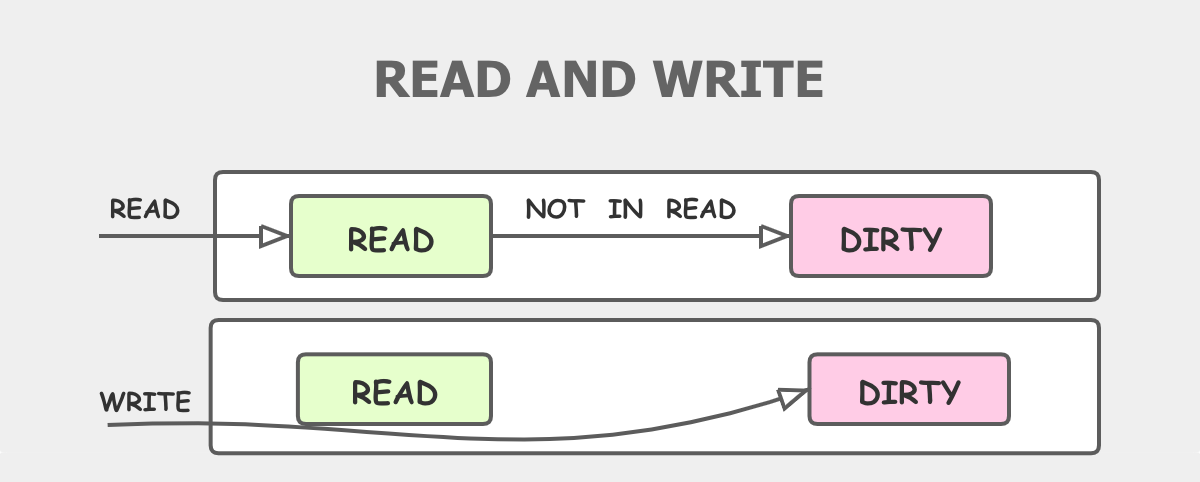
- 空间换时间。通过冗余的两个数据结构(read、dirty),减少加锁对性能的影响。
- 使用只读数据(read),避免读写冲突。
- 动态调整,miss 次数多了之后,将 dirty 数据提升为 read。
- double-checking,先在 read 上没读到,再到 dirty 查找一次。
- 延迟删除。删除一个键值只是打标记,只有在提升 dirty 的时候才清理删除的数据。
- 优先从 read 读取、更新、删除,因为对 read 的读取不需要锁。
- 适合读多写少的场景