 记录 LeetCode 题型分类及解题思路
记录 LeetCode 题型分类及解题思路
“5. Longest Palindromic Substring”
- 解法 1: 双指针, 中心扩散
- 思路:
- 遍历每一个位置 i
- 以 i 为中心向两边扩展指针 l r 检测每个元素是否对称,记录
r-l+1最大值和当时的 l 值 - 注意 i 位置本身可以作为中心,也可以以 i 作为 l,即字符串是偶数的对称情况
- 思路:
“6. Zigzag Conversion”
- 解法 1:模拟法
- 利用边界条件让方向切换
- 如果行数为 1 则不切换方向(方向值为 0),所以方向初始值
1%numRows
- 如果行数为 1 则不切换方向(方向值为 0),所以方向初始值
- 利用边界条件让方向切换
“7. Reverse Integer”
- 解法:math
- 基本方法是通过
%、/10循环取得结果 - 难点是如果超出 Int32 范围需返回 0,并且要求不允许使用 int64 类型,这样无法对最终结果做范围判断
- 可以利用
ret*10处理前对math.MinInt32/10和math.MaxInt32/10做判断,预判最终结果
- 基本方法是通过
“8. String to Integer (atoi)”
- 解法:遍历字符,按状态进行切换
- 可以利用状态模式,更好理解
“9. Palindrome Number”
- 解法:
- 最简单思路是转为字符串,然后字符串判断是否对称
- 可以参考”7. Reverse Integer”转为反转数字,同时剪短原数字,然后比较
- 注意可能出现两种对称(12321, 1221),所以比较时每步要比较两种情况
- 可以只转换一半,这样可以避免转换后溢出的情况
“11. Container With Most Water”
-
解法 1(推荐):
- 高度、距离都是影响水量的值,其中高度的权重更大,所以在循环缩小距离时保持较高的高度让高度较小的一方遍历。
-
解法 2:
- 利用动态规划法,分别计算当前位置左边最大高度、右边最大高度,算法较易理解,但是需要占用额外空间。
“12. Integer to Roman”
- 解法 1:DC
- 思路 1:
- 根据当前 10 进制尾数选择字符
- 根据不同情况拼接字符
- 思路 1:
- 解法 2:math
- 利用阿拉伯数字和罗马数字的兑换规律,把罗马数字组合成可能对应的阿拉伯数字列表,按从大到小的顺序把传入的阿拉伯数字减小,同时拼装结果
- 利用 stings.Builder 可以提高字符串拼装效率
- 由于 Go 里没有 OrderedMap,所以用结构体数字代替,在其它语言可以直接用 OrderedMap 更简单
“12. Integer to Roman” DivideAndConquer Golang
“13. Roman to Integer”
- 解法: map
- 顺序遍历每个字符,记录前一个字符以备减去操作
- 记录下罗马字符和数字映射关系、罗马数字前缀是否减去字符的映射关系(如 V 前的 I 会导致减去)
- 如果需要减去则先减去两倍,然后再正常加上当前数值。如:当前 V 前一个是 I,则当前值
ret += 5 - 2*1
“15. 3Sum”
- 解法:TwoPointers
- 思路:
- 首先对数组排序,以便可以规则的取结果,并且跳过重复元素
- 设定三个下标 l m r,全程保证
l < m < r - 最外层循环 l、中层循环 m、内层循环 r,由于
m < r,所以第二层循环是O(n) - 确定 l m 后,r 从右向左逼近,找到
nums[l] + nums[m] + nums[r] == 0则记录答案 - 要点是 l、m、r 对新元素的第二轮循环开始就要避免重复数据,这样确保
[0,0,0,0]这种只输出一个[0,0,0]
- 思路:
“16. 3Sum Closest”
- 解法:TwoPointers
- 思路:
- 思路和”15. 3Sum”是一致的,两层循环,O(n^2)
- 由于无法精确找到结果,所以 r 的缩小逻辑有所不同,每次 r 变更后都要检测一次结果,不能一直缩小
- 思路:
“17. Letter Combinations of a Phone Number”
- 解法: Backtraking
“18. 4Sum”
- 解法:TwoPointers
- 参照”15. 3Sum”,两层外层循环,然后双指针一层循环,O(n^3)
- 每层循环要考虑进行过一次后要自动跳过重复项
“19. Remove Nth Node From End of List”
- 解法:快慢指针法
- 快指针先向前 n 步,然后慢指针和快指针一起向后,直到快指针为 nil
- 注意慢指针始终指向要删除节点的前一个,以便后续操作
“20. Valid Parentheses”
- 解法:栈
“25. Reverse Nodes in k-Group”
- 解法 1 :
- 思路:
- 需要实现一个函数
reverse(head, tail) (newHead, newTail) - 在遍历过程中,统计跳过的结点数量,达到数量后,则用子函数旋转并调整指针,然后继续遍历
- 需要实现一个函数
- 扩展(不可取):
- 可以在遍历过程中就对结点进行反转,然后按组直接调整指针
- 最后一组未满,需要再反转回去
- 用扩展方法可以降低时间复杂度,但是逻辑复杂度大大增加
- 思路:
“31. Next Permutation”
- 原理: 顺序排列的数组没有更小的值,倒序排列的数组没有更大的值。
- 解法:
- 从右向左查找第一个发生递减的位置。
- 从此位置向右查找最右边比当前值高一点的位置。
- 交换这两个位置。
- 将发生递减位置右边所有位置反转,呈现正序排列。
“32. Longest Valid Parentheses”
- 思路 1:stack 背影法 在 stack 中保存有效和无效位置,默认填-1。如果中间持续是有效位置,那么到有效匹配后,就可以看一下之前的背影最远到哪里,记录这个最大值。
“32. Longest Valid Parentheses” Stack
- 思路 2: 双向遍历
- 第一遍从左向右,用 left、right 分别记录左右括号数量,如果
left == right则记录最大值 - 为了方式忽略
((),从右向左再遍历一遍,取两次遍历最大值为最终结果
- 第一遍从左向右,用 left、right 分别记录左右括号数量,如果
- 关键点:
- 遍历过程中,如果应该后出现的符号过多(比如从左到右时
)过多),则要重置计数
- 遍历过程中,如果应该后出现的符号过多(比如从左到右时
“32. Longest Valid Parentheses” Brute Force
“33. Search in Rotated Sorted Array”
- 思路: 这道题是在二分查找的基础上,增加一层排除法逻辑,使得每次都能缩小一半查找范围。
- 步骤:
- 最外层 for 循环,条件是
l<r - for 内第一层 if 如果左右其中一部分是有序的,则认为另一部分无序,根据有序的继续判断
- 第二层 if 如果 targe 在范围内,则继续缩小范围,否则丢弃当前范围
- 最外层 for 循环,条件是
- 要点:
- 二分查找时,要根据判断条件的
=情况,缩小范围。如果匹配=则原有边界要保持,如if tar<=nums[mid] {r = mid}
- 二分查找时,要根据判断条件的
“33. Search in Rotated Sorted Array” Binary Search
“34. Find First and Last Position of Element in Sorted Array”
- 思路:lowerbound
这道题是在二分查找的基础上,进一步利用算法细节特性:”二分查找的结果是重复元素第一次出现的下标”。
所以只需要再查询
按排序下一个元素出现的位置-1就可以得到末尾位置
“34. Find First and Last Position of Element in Sorted Array” Golang
“35. Search Insert Position”
- 解法:LowerBound
“36. Valid Sudoku”
- 解法:矩阵遍历 + bit 压缩
- 思路:
- 按照题目,只要保证行、列、格三格方向无重复数字即可,可以分别用三个数组记录
- 难点之一是求某一格在格数组的下标,
gridIdx := (i/3)*3 + (j/3) - 为了节省空间,可以利用一个 9 个元素的 int 数组保存结果,int 中每个位可以记录一个数字是否出现过,三个维度需要 27 个位
- 思路:
“39. Combination Sum”
- 解法 1:DFS
- 思路:
- 初看想用 Backtraking 实现,用 preSlice 保存已选项,逐步搜索。但是实现代码复杂度太高
- 可以利用逻辑特性:”只有最后面一项有效,前面的项才有效”,每次 DFS 下一层返回值有效时,才组装结果
- 每个元素进行尝试,然后下一层递归的 target 减去本层选定的元素
- 注意:
- 向下层传递数组时,范围是
[i:],这样本元素还可能被选中,但前面的元素就不能被重复使用了,避免结果重复 target == v时将结果累加到ret中,不要直接返回,否则会丢失部分结果
- 向下层传递数组时,范围是
- 时间复杂度:
O(n^n)
- 思路:
- 解法 2: Backtracking
- 思路:
- 需要两个全局变量:pre 保存前面已添加到数组的元素、ret 用于保存结果
- 如果满足
tar == 0,则将前面的数组保存,注意保存时候要复制一个数组,避免原数组被篡改 - 对于每个位置、可以取也可以不取
- 思路:
“39. Combination Sum” Backtraking
“40. Combination Sum II”
- 解法:Backtracking
- 思路:
- 尝试用”39. Combination Sum”的解法+memory 会超时,需要通过遍历技巧避免 map 去重
- 本题的关键是存在重复元素,并且结果不能重复,也就是
1,1,1这种情况下,只能是1/11/111, 首先需要对原数组排序,只有当每个元素第一次被递归到的时候才能选取一次,否则直接跳过 - 处理当前递归时,要遍历每个元素,跳过重复元素
- 维护一个 preSlice,每次尝试将当前元素加入,然后递归,递归结束删除当前元素
- 技巧:
- 由于数组是递增的,只要当前元素>target,那么可以提前打断本层递归内的循环
- 思路:
“40. Combination Sum II” Backtraking
“42. Trapping Rain Water”
-
思路 1:两遍遍历 假设每一个下标对应一个水柱,则水柱的高度由此位置最左和最右 bar 的高度综合决定。
- 从左向右遍历一遍,记录每个下标对应的左边最高的 bar 高度
- 从右向左遍历一遍,一边遍历一边计算累加当前位置的水柱高度,
水柱高度 = min(left, right) * height
- 时间复杂度 O(n),空间复杂度 O(n)
-
思路 2:双指针 按思路 1 计算每个水柱时,高度取决于较低的那个边。所以可以单独对高度较低的边进行遍历,这样只需要遍历一遍,并且无需额外空间
“42. Trapping Rain Water” TwoPointers Golang
“48. Rotate Image”
- 解法:Inplace + 模拟
- 思路:
- 本题相当于取 matrix 左上角的象限内容进行 90 度旋转,可以手动模拟,然后相互替换四个位置的元素
- 要点:
- 需要仔细模拟第一象限的坐标变动过程,分别推导其他象限的坐标关联关系
- 由于每个元素的变动会影响四个元素(包括自己),所以遍历起始坐标实际上只覆盖 1/4 就可以,
再加上遍历 4 个元素的坐标相互影响,不应产生后效性,即元素
(0,0)影响到的四个元素未来都不能再动了, 第一行的元素变动会影响到第一列的元素,所以第二行第一列就不能再动了, 最终的第二层循环是这样的:for y := x; y < n-x-1; y++, 最后的变动会形成一个倒三角形 - 如果边长 n 是奇数,那中间的元素要跳过,所以第一重循环的范围是
for x := 0; x < n>>1; x++
- 思路:
“49. Group Anagrams”
- 思路: 利用 Anagram(异位词)特性,统计每个词的字母出现次数,生成一个”指纹”,然后通过 HashMap 收集相同指纹的词
“49. Group Anagrams” HashTable
“50. Pow(x, n)”
- 解法:Math
- 思路:
- 直观的想法是对 x 进行 n 次乘积,再根据 n 的符号决定最后返回的结果是否取倒数。但是这种方案会超时
pow(0.00001, 2147483647) - 正确的解法是快速幂算法
- 直观的想法是对 x 进行 n 次乘积,再根据 n 的符号决定最后返回的结果是否取倒数。但是这种方案会超时
- 时间复杂度:
O(logn) - 空间复杂度:
O(logn) - 改进:
- 可以将 dfs 改为 dp,这样空间复杂度将为
O(1)
- 可以将 dfs 改为 dp,这样空间复杂度将为
- 思路:
“61. Rotate List”
- 难点:
- 题目最后列出限制条件
0 <= k <= 2 * 10^9,所以要先遍历一遍计算总结点数 n,然后用用总节点数取模计算出跳转数
- 题目最后列出限制条件
“64. Minimum Path Sum”
- 思路:这道题有较好的 DP 解决方案,所以用 DFS 时性能相比较差就会超时。解决思路:从右下角开始动态规划,计算每个下一个位置可能的最小值。利用原空间就可以完整 DP 过程。
“65. Valid Number”
- 解法:FSM 有限状态自动机
- 思路:
- 本题不需要计算结果,只需要求出最后是否有效,所以简化了思路
- 可以采用正则表达式,也可以利用二级 map 实现有限状态自动机
- 思路:
“65. Valid Number” StructDesign
“69. Sqrt(x)”
-
二分查找法:
- 在 1~x 之间进行二分查找,条件为
m > x/m,注意这里没有用m * m > x因为可能溢出, - 使用
/会比乘法慢一些,但是二分查找的时间复杂度是 O(logn)所以问题不大。 - 使用二分查找法效率比牛顿迭代法稍高。
- 在 1~x 之间进行二分查找,条件为
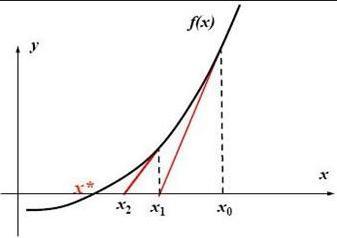
- 牛顿迭代法:
- 设函数 f(x)=x^2- t,初始随意取一点 x0 = t,则与函数有一个焦点,对这点求导,得到切线与 x 轴得新的 x1 = (x0/2)+t/(2*x0)。
- 不断重复上述步骤,当 f(xn) = xn^2-t = 0 时,xn 就是答案。
“72. Edit Distance”
- 编辑距离在机器翻译、语音识别等数据科学领域经常用到。
- 动态规划解法:
- 用 dp[i][j]代表 word1[i]到 word2[j]的编辑距离,从空字符串开始演化,所以二维矩阵的范围要大 1。
- 初始化第 0 行和第 0 列,然后遍历计算 dp[i][j]。转移公式是:dp[i][j] = min(dp[i-1][j]+1, min(dp[i][j-1]+1, dp[i-1][j-1] + (word1[i] == word2[j]? 0, 1)))。
- 最后返回 dp[m][n]。
“73. Set Matrix Zeroes”
- 考点:
- “in place”思想
- 二进制压缩,用单独标记记录第一行和第一列
- 利用逆序处理,利用第一行的标记作用
“73. Set Matrix Zeroes” Array C++
“74. Search a 2D Matrix”
- 解法 1: 逐步贴近法
- 利用横纵分别有序的特性,以某个角(如左下)开始遍历,先向上遍历找到刚好小于等于目标值的位置, 然后向右遍历找到目标
-
时间复杂度: O(m+n)
- 解法 2: 两次二分查找
- 先纵向二分查找,先找到刚好小于等于目标值的位置
- 再横向二分查找,找到目标
-
时间复杂度:O(logm+logn)
- 解法 3: 拼接二维数组为一维,一次二分查找
- 由于每行一定大于上一行,可以将每行首位拼接,组成一个有序数组
- 利用一个一维坐标进行二分查找
- 时间复杂度:O(log(m+n))
“74. Search a 2D Matrix” Array Golang
“76. Minimum Window Substring”
- 解法:SlidingWindow
- 思路:
- 用 map 统计 target 字符串所需各个字符数量
- 向右滑动窗口 right 边,累加字符数量,直到满足目标条件
- 向右滑动窗口 left 边,去掉逐个去掉左边元素,每次执行条件检查函数,同时记录最小窗口和起始位置
- 优化:
- 每次都检查所有字母数量是否匹配比较耗时,可以利用变动时的边界条件,记录满足条件的字符数量是否有变化。 这样可以用数组记录、每次变化无需轮询检查所有字母
- 思路:
“78. Subsets”
- 迭代法:
可以将迭代过程看做:
[[]] -> [[],[1]] -> [[],[1],[2],[1,2]] -> [[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]每次将前面的内容复制到结尾,并将新的数字加入进去。
- 回朔法: 设置一个集合切片,每一个元素可以选取或不选取
“81. Search in Rotated Sorted Array II”
- 解法:二分查找
- 思路:
这道题和
33. Search in Rotated Sorted Array思路一致,只是会有重复元素导致无法判断哪一边。 可以在nums[l]==nums[mid]==nums[r]的时候,两边同时缩小范围l++;r--解决
- 思路:
这道题和
“82. Remove Duplicates from Sorted List II”
- 思路:
- 先创建一个 dummyHead,Val 值为
-101 - preTail 指向前面的最后一个元素
- 一旦判断当前元素存在重复,则 for 循环跳过所有相同值元素
- 先创建一个 dummyHead,Val 值为
“82. Remove Duplicates from Sorted List II” Golang
“84. Largest Rectangle in Histogram”
- 解法:Monotone Stack
- 思路:
- 这道题的Monotone Stack(单调栈)解题思路(时间复杂度 O(n))很重要,在很多其他题中都会用到。
- 从左向右遍历,并不断将高度值的下标 push 入 stack。
- 当某一位置 height 值缩小时,那么之后就很难计算前面的面积了,所以就要把前面比当前值高的 stack 出栈,并计算前面的面积。
- 注意,计算面积时,宽度要当前下标和前面的”背影”相减,所以栈底是-1。
- 注意,计算面积时,当前的 i 是不取的,所以要 -1。
- 这道题的Monotone Stack(单调栈)解题思路(时间复杂度 O(n))很重要,在很多其他题中都会用到。
- 时间复杂度:
O(n)
- 思路:
“84. Largest Rectangle in Histogram” Stack Golang
“85. Maximal Rectangle”
- 解法:DP + Monotone Stack
- 思路:
- 本题基于”84. Largest Rectangle in Histogram”
- 可以逐步对每列进行 DP 累加统计,统计左边到目前列的连续 1 的个数
- 然后这个 DP 数组就可以作为
largestRectangleArea的参数进行统计了
- 时间复杂度:
由于
largestRectangleArea的时间复杂度为O(n),所以本题目时间复杂度为O(mn)
- 思路:
“88. Merge Sorted Array”
- 思路:归并排序
- 利用原有数组容量和顺序特性,从大到小进行归并排序
- 时间复杂度 O(n),空间复杂度 O(1)
“90. Subsets II”
-
解法 1: backtracking + memory
- 思路:
- 利用 backtraking 对每个元素执行”取/不取”操作
- 将所有元素拼接成字符串作为唯一标识,用
map[string]struct{}进行重复判别 - 由于乱序下元素顺序不同可能影响集合一致性判别,所以要先进行一次排序
- 缺点: 由于大量字符串拼接操作,时间、空间复杂度都存在较大浪费
- 思路:
-
解法 2: bit mask
- 思路:
- 由于是任意子集,所以原始元素顺序不重要,先对元素做排序以便后续操作
- 对于长度为 n 的 nums 中所有元素可以”选”和”不选”,可以看作是 n 位二进制数的每一位进行选取或不选操作。
可以设一个 n 位的 mask 二进制数,则 0/1 序列对应的二进制数量正好为
[0,(2^n)-1](题目的 n 较小,也使得 mask 方案成为可能) - 考虑
[1,2,2]这种情况,取下标”0 1”和”1 2”的结果是一样的,都是[1,2]。 可以推导出如果元素 x 与前面的元素 y 相同,如果 y 没有取而取了 x,则包含 x 的子集必然会出现在包含 y 的所有子集中, 所以可以跳过这种情况,继续下一个 mask 处理
- 优点: 利用二进制操作性能较高
- 思路:
“90. Subsets II” Golang bit mask
- 解法 3: backtracking
- 思路:
- 以 backtracking 为基本思路,结合上面
[1,2,2]模式的识别跳过不必要的处理 - 注意 Go 中 append 时为了避免各递归函数相互影响,要构造新的 slice
- 以 backtracking 为基本思路,结合上面
- 思路:
“91. Decode Ways”
- 解法 1: DFS + Memory
- 思路:
- 每个位置可以取自己,也可以取自己和后面一个字符,用 DFS 即可
- 每次如果可以取,那一定符合
0< x <= 26的条件,把条件字符串放入 set 可以快速判断 - 递归函数返回其对应的结果数,由调用者负责将两种情况相加
- 如果没有 Memory 会超时,所以需要加上
- 思路:
- 解法 2: DP
- 思路:
- 从前到后逐步解码,只有前面解码成功后面的解码才成功
- 设
dp[i]表示第 i 个元素,有两种情况: 如果当前值有效s[i] != '0',则继续累加前面数字; 如果当前前面有效且和前面可拼接为 26 以内的数,则继续累加更前面数字;
- 要点:
dp[0]==1,空字符串可以编码为空,也是一种编码结果- 由于
dp[0]要占一个位置,所以 i 要顺延一位,对应 i(从 1 遍历) 的字符为s[i-1] - 实现后发现只需要关注三个 dp 值即可,所以可以优化为 O(1)空间复杂度
- 思路:
“95. Unique Binary Search Trees II”
- 解法:Backtracking + Recur
- 思路:
- 题目可以理解为给定一个数组,这个数组是顺序的,利用这个数组构造树,将根结点,放入结果数组
- 可以用 Recur 的思考方式,当前元素取
[1,n]的某个元素,其 left 正好为左边子数组构造的树、右孩子同理 - 取当前结点可以利用 Backtraking 的思路遍历执行,然后将自结点数组排列拼装为当前树
- 要点:
- 注意边界条件
start > end时,要返回一个有一个元素的数组,数组唯一元素是个null值,这样上层才好排列组合
- 注意边界条件
- 优点:
- 这样生成代码简洁,而且同一子树在不同父树中重复利用,节省空间
- 思路:
“95. Unique Binary Search Trees II” Backtraking
“97. Interleaving String”
- 解法:二维 DP
- 类似”edit distance”,进行二维 DP
- 设
dp[i][j]表示 s1 前 i 个字符和 s2 前 j 个字符是否可以匹配 s3 前 i+j 个字符 - 有转移方程
dp[i][j] = dp[i][j] || dp[i-1][j] && s1[i-1] == s3[i+j-1]
“97. Interleaving String” DynamicPlanning
“99. Recover Binary Search Tree”
- 解法:双向中序遍历
- 思路:
- 手动用中序遍历写一下出错的两个树,
3 2 1、1 3 2 4可以找到规律: 本应从左到右(左边补 -∞、右边补 +∞)递增,只有两个元素不匹配 - 先从左向右遍历一次,找到第一个错乱元素;再从右向左遍历一次,找到第一个错乱元素
- 将上面两个元素值交换即可
- 不用输出到数组,只要分别用两个方向的中序遍历查找到结点指针即可。
- 手动用中序遍历写一下出错的两个树,
- 注意:
- 递归函数要有返回值,以便上层判断是否需要继续遍历
- 思路:
“103. Binary Tree Zigzag Level Order Traversal”
- 解法:中序 dfs 遍历 + 按层保存 + 偶数层反转
“105. Construct Binary Tree from Preorder and Inorder Traversal”
- 解法:dfs
- 思路:
- 通过某两种顺序的遍历结果创建 Tree 是比较常见的问题,思路也类似, 利用前/后序的特性:当前结点一定是第一个(或最后一个)元素; 然后通过当前结点将中序遍历数组分成左、右子树两段,再递归求的结点
- 要点:
- 必须要包含中序遍历,才能区分左右子树所需中序遍历数组
- 利用前/后序数组时,需要一个全局的下标指示当前处理的根元素,然后利用创建子树的顺序控制这个下标的移动
- 思路:
“106. Construct Binary Tree from Inorder and Postorder Traversal”
- 参考”105. Construct Binary Tree from Preorder and Inorder Traversal”
“107. Binary Tree Level Order Traversal II”
- 解法:dfs + 数组反转
- 思路:
- 先用 dfs 先序遍历 把每层的结果记录
- 然后对整体结果反转,得到最终答案
- 思路:
“109. Convert Sorted List to Binary Search Tree”
- 解法:快慢指针 + 递归 + DivideAndConquer + BST
- 思路:
- 解法基于”108. Convert Sorted Array to Binary Search Tree”,利用快慢指针实现查找中点
- 思路:
“109. Convert Sorted List to Binary Search Tree” Tree
“101. Symmetric Tree”
- 解法:recur
- 思路:
- 首先想到 dfs 分别输出左右两棵树的元素,然后对比
- 还可以利用 recur 传两个参数的方式实现,子树正好也是镜像关系
- 思路:
“114. Flatten Binary Tree to Linked List”
- 解法:recur
- 思路:
- 利用递归函数,已知头结点,返回尾结点
- 然后根据左右子树是否有效的条件,进行前后拼接
- 思路:
“114. Flatten Binary Tree to Linked List” Tree
“116. Populating Next Right Pointers in Each Node”
- 解法:pre-order
- 思路:
- 利用先序遍历+层级 pre 结点实现
- 思路:
“120. Triangle”
- 解法:DP
- 思路:
- 利用原有二维数组,从下到上进行 DP 演化
- 状态转移方程:
triangle[i][j] += min(triangle[i+1][j], triangle[i+1][j+1]) - 最后返回
triangle[0][0]
- 思路:
“122. Best Time to Buy and Sell Stock II”
- 解法:Greedy
- 思路:
- 分析规律可知,只要是上升区间,每一段都可以累积结果,
ret += max(0, prices[i+1]-prices[i])
- 分析规律可知,只要是上升区间,每一段都可以累积结果,
- 思路:
“123. Best Time to Buy and Sell Stock III”
- 考点:
- DP
- 临界条件逻辑
- 思路:
- 对于任意一个结束日 i,有 5 个利润状态值需要从 i-1 的状态推导,这五个状态值及其动态转移方程为:
- 假设前一日的结果标记为
',买卖产生的利润为price[i]-price'- 无操作利润,始终为 0,无需状态迁移
- buy1 当日第一次买入,max(buy1’, -price[i])
- sell1 当日第一次卖出,max(sell1’, buy1’ + price[i])
- buy2 当日第二次买入,max(buy2’, sell1’ - price[i])
- sell2 当日第二次卖出,max(sell2’, buy2’ + price[i])
- 假设前一日的结果标记为
- 如果新一日价格更低,则
-price[i] > -price',所以上面 buy1 的公式符合逻辑 - 对于临界条件,如果同一天做完上述四个动作,则 sell1、sell2 的利润都为 0。我们可以直接利用当天的数据作为迭代初始数据而不会影响结果
- 又根据上面推导,如果只进行一次交易,sell2 的值和 sell1 一致,所以我们最后直接返回 sell2 就可以
- 只要根据第一天数据设置初始值,后面继续迭代就能推导出最后结果
- 对于任意一个结束日 i,有 5 个利润状态值需要从 i-1 的状态推导,这五个状态值及其动态转移方程为:
“123. Best Time to Buy and Sell Stock III” Golang
“124. Binary Tree Maximum Path Sum”
- 解法:DFS
- 思路:
- dfs 处理每一个节点,分情况取得两个关键 max 值:当前 dfs 的返回值、最终结果最大值
- 思路:
“124. Binary Tree Maximum Path Sum” Tree
“125. Valid Palindrome”
- 解法:ASCII 码
- 思路:
- 在 ASCII 码中,顺序是这样的:”大写字母” < “符号” < “小写字母”
- 要自己实现
isAlNum函数return ('A' <= x && x <= 'Z') || ('a' <= x && x <= 'z') || ('0' <= x && x <= '9') - 由于大小写字母之间差不是 26(中间有符号),所以应计算出字母距离
dist := byte('a'-'A') - 为了避免
0P这种数字和字符间隔正好 32(‘a’-‘A’)的情况被识别为 true,需要专门逻辑,或在最初就调用strings.ToLower
- 思路:
“127. Word Ladder”
-
解法 1: BFS + HashTable
- 思路:
- 将字典保存至 hashTable 以便后续查找
- 利用 queue 做 BFS,queue 的元素是”(当前字符串,步数)”
- 尝试对每个单词的每个位置进行替换,如果在字典中找到则入队,同时将该单词从字典删除
- 如果当前要处理的单词和目标一致,则返回”step+1”
- 注意:
- 在替换单个字符后,要记得替换回去
- 改进:
- 可以用新旧两个队列处理,这样就无需保存 step 了
- 思路:
-
解法 2: BFS + HashTable
- 思路:
- 上面的 BFS 每轮会将大量无关单词加入 queue,和 step 呈指数关系,所以考虑降低检索的 step 数
- 可以从两个方向分别进行检索,即形成三个 set:dict beginSet endSet
- 一旦发现下一个单词在对方的 set 中,就能找到答案
- 思路:
“128. Longest Consecutive Sequence”
- 解法:HashTable
- 思路:
- 只要排序就能解决,但题目要求时间复杂度
O(n),可以考虑 DSU 或 HashTable,DSU 逻辑稍复杂,用 HashTable 更容易一些 - 先把元素都保存到 HashTable,然后遍历每个元素
- 遍历时,检查当前元素左边一个元素是否存在,如果不存在则当前元素可以作为起点进行循环检索,查找最长长度
- 只要排序就能解决,但题目要求时间复杂度
- 思路:
“128. Longest Consecutive Sequence” HashTable
“130. Surrounded Regions”
- 解法:In-place + DFS + DivideAndConquer
- 思路:
- 题目要求是”只要能延伸到边缘的 O 的区域都保持为 O”
- 首先对边缘进行扫描,并用 DFS 检索,把 O 改写为 A
- 由于 m n 小于 3 时 O 都是在边缘的,所以无需处理,直接返回原样
- 再对所有元素遍历一遍,遇到 O 说明是无法触达边缘的,置为 X;遇到 A 说明是之前改变的,还原为 O
- 思路:
“131. Palindrome Partitioning”
- 解法:backtracking + dp
- 设 dp[i][j] 为 “i~j 是否为回文子串”,先用 dp 的方法预处理,求出所有连续字串是否为回文字串
- 用回溯的方法尝试从 i~j 进行分割,然后 dfs 剩下的字符串
- 思路:
- dp 的初始状态是所有值均为 true,然后逐步计算出结果,
dp[i][j] = s[i]==s[j] && dp[i+1][j-1] - dp 的 i、j 两层循环方向很重要,为了符合
i<j的语义,要控制好遍历方向 - backtracking 时要注意做好数组的复制,避免回溯删除动作影响了最终结果
- dp 的初始状态是所有值均为 true,然后逐步计算出结果,
“131. Palindrome Partitioning” Golang
“132. Palindrome Partitioning II”
- 解法:两次 dp
- 参照
131可以生成一个辅助 dp1,可以快速求得 dp1[i][j]是否符合回文 - dp2[j] 表示到 j 为止最少的分割次数,设 i 为一个分割点(0 <= i <= j)使得 i+1~j 是回文,即
dp1[i+1][j] == true,dp2[j] = min(dp2[j], dp2[i]+1)
- 参照
“132. Palindrome Partitioning II” Golang
“133. Clone Graph”
- 解法:DFS + HashTable
“135. Candy”
- 解法:两遍遍历
- 思路:
- 分析题目的规律,如果从左向右遍历,则遇到增长情况糖数++;反之从右向左遍历也是。最终取较大值
- 思路:
“136. Single Number”
- 解法:按位状态机
- 题目要求
O(1)空间复杂度,所以需要利用异或运算按位统计出结果
- 题目要求
“136. Single Number” BinaryOperation Go
“137. Single Number II”
- 解法:按位状态机
- 基于”136”的解法,利用数字电路(与、或、非、异或)推导,利用两个变量保存运算过程值
“137. Single Number II” BinaryOperation Go
“138. Copy List with Random Pointer”
- 解法:dfs+memo
- 思路:
- 对于一般的结点复制,可以利用 dfs 过程,遍历每个旧结点创建新结点
- 为了确保 random 新结点在被引用前创建,要先处理 next 再处理 random
- 用
map[*Node]*Node保存旧、新结点关系,Pointer 类型可以作为有效的 key
- 时间复杂度:
O(n) - 空间复杂度:
O(n)
- 思路:
“138. Copy List with Random Pointer” LinkedList
- 解法:利用相邻关系保存新结点
- 思路:
- 将新结点创建在每个旧结点的后面,这样可以快速定位旧 Random 指针对应的新结点
- 思路:
“138. Copy List with Random Pointer” LinkedList
“139. Word Break”
- 思路:dp
- 这是一个完全背包问题
- dp[i]表示 i 长度的字符串能否用字典表示,0 < i <= stringLength
- dp[i]演化过程中,只需要判别末尾是否能匹配一个单词
“141. Linked List Cycle”
- 解法:快慢指针法
- 从起始出发出两个指针,一个”快指针”和一个”慢指针”
- 快指针每次跳两个位置、慢指针每次跳一个位置
- 如果不存在回环(loop),则快指针会先到 null 节点
- 如果存在回环,则快慢指针必然在某点会相遇
- 此解法时间复杂度为 O(n)、空间复杂度为 O(1)
“142. Linked List Cycle II”
- 解法:”Floyd’s Tortoise and Hare”算法
- 通过快慢指针判断是否存在回环,并且记录快慢指针相交位置。
- 从链表头部和之前的快慢指针相交位置同时发起一个慢指针循环继续向前
- 当两指针重叠时,就找到了回环进入点
“142. Linked List Cycle II” Golang
“143. Reorder List”
- 解法:快慢指针 + 链表反转 + 链表归并排序
“146. LRU Cache”
- 设计:
- 用 LinkedList 记录元素被更新的时间顺序,被用到时就放在链表最后,链表元素要记录 Key-Value 值
- 用 HashMap 记录元素是否存在,其 Value 保存
*ListElement,用于 O(1)快速定位元素 - 在 size 发生变化时,如果 size 超过容量,则删除 list 头元素
“148. Sort List”
-
解法 1:DFS + MergeSort
- 思路:
- 利用快慢指针快速找到本段链表的中点,DFS 对两段子链表排序,然后在对两段子链表执行 merge
- 注意:
- 递归函数声明为
func sort(head, tail *ListNode) *ListNode,传入一段链表,返回排好序的 head - 在递归末端但单元素时,要设置
if head == tail { head.Next = nil },这样把无用的指针打断,避免影响 merge - 在设置快指针时,要分两步设置 fast,以让 slow 尽量向后
- merge 时,要创建一个辅助头结点
- 递归函数声明为
- 时间复杂度:
O(nlogn) - 空间复杂度:
O(logn)
- 思路:
- 解法 2(推荐): DP + MergeSort
- 思路:
- 解法 1 是”自顶向下”的思路,由于函数递归调用产生
O(logn)的栈空间复杂度。 - 可以用”自底向上”的思路,类似 DP 过程,先将短链表(最短为 1)两两结合 merge,再逐步扩大长度
- 首先计算出链表总长度
- 循环,设定链表长度为 1,每次循环长度翻倍(«1),直到达到总长度
- 第二层循环是逐步处理所有相邻的链表,执行 merge 操作
- 循环内分两步分别找到链表 1 和链表 2 的 head,然后执行 merge
- 每轮外层循环,会遍历一遍结点,循环次数为
logn
- 解法 1 是”自顶向下”的思路,由于函数递归调用产生
- 注意:
- 每次当前结点走到末端时,要打断上一段链表,设置最后一个结点的
xxx.Next = nil - 寻找 head2 时有可能直接是 nil,所以要多个判断,否则会 panic
- 每次当前结点走到末端时,要打断上一段链表,设置最后一个结点的
- 时间复杂度:
O(nlogn) - 空间复杂度:
O(1)
- 思路:
“149. Max Points on a Line”
- 解法:Geometry + float 特性 + HashMap + Math(gcd)
- 思路:
- 两点可以确定一条直线,
y = ax + b,只要确定了两个系数就可以确定一条直线 - 可以遍历所有两个点,求其参数 a b,如果参数相同则说明点共线,而 a 就是其斜率,需要用浮点数表达
- 但是计算机的浮点计算不够精确,无法精确匹配,所以只能用整数处理
- 考虑用两点的 x y 坐标之差作为斜率衡量标准
- 可以通过只计算斜率避免计算系数 b,简化计算过程
- 对每个点循环其他所有点,只要斜率相同,说明共线,用 HashMap 记录斜率
- 保存斜率信息前,先要除以GCD,以避免
1/2 != 2/4的情况
- 两点可以确定一条直线,
- 优化点:
- 第二层循环只需要遍历后面的结点,因为前面结点的共线信息已经记录在 HashMap 里了
- 由于 x y 的范围较小,最大范围为
10^4,可以用一个 int 同时保存 x y,y + x*XBase - 点数 <=2 的情况下,可以直接返回点数
- 如果统计某点所在直线的共线点数已经
> n/2,那么已经找到了结果 - 当找第 i 个结点时,共线点数最多为
n-i个,如果已经找到的数已经大于这个数,则无需继续查找,因为后面的点都不可能找到更大的共线数了
- 思路:
“149. Max Points on a Line” Geometry
“152. Maximum Product Subarray”
- 思路: 由于存在负数元素,之前计算的最大值可能会一下反转为最小值;相反,之前计算的最小负值可能一下变成最大值。 所以在采用动态规划法时,要保留最大、最小两个值,然后向后演进。
“153. Find Minimum in Rotated Sorted Array”
- 解法:BinarySearch
- 思路:
Rotated Sorted Array的特点是,如果取 mid 位置,则一边是升序而另一边是降序,假设为[2,3,1]- 通过不断排除
升序子区域的右边和降序子区域的左边就可以找到最小值
- 要点:
- 由于存在”最大值突变最小值”的转换点,所以丢弃左边区域时要
l = mid+1,这样最终 l 就是结果了
- 由于存在”最大值突变最小值”的转换点,所以丢弃左边区域时要
- 思路:
“154. Find Minimum in Rotated Sorted Array II”
- 解法:BinarySearch
- 思路: 类似”81. Search in Rotated Sorted Array II”,在无法判断哪边有序时,左右范围都缩小一下
“155. Min Stack”
- 思路: stack 的特性是”旧数据保持不变”
- 设计: 增加一个”辅助 stack”,用于保存到目前为止的最小值
“160. Intersection of Two Linked Lists”
- 解法:
- 分别从 A、B 两个链表的起点开始一个跳转指针
- 当指针到达末尾后,切换两个指针的位置为 B、A,继续跳转
- 如果两个指针指向同一位置,则该位置就是链表交汇点
- 如果任意指针走到了尾部仍然没有交汇,则没有交汇点
- 思路:
这种问题先简化思路,假设有两个链表,分别为:
A->C->D和B->C->D,则 C 是交汇点。 如果按照上面方法使跳转路径相交叠,则两个指针交汇前走的距离分别是:AC+CD+BC和BC+CD+AB,可以看到,这两个距离是完全相等的 - 这个解法的优点是空间复杂度为 O(1)
“160. Intersection of Two Linked Lists” LinkedList
“162. Find Peak Element”
-
解法:BinarySearch
-
思路:
- 题目规定了所有元素都不相同,所以只需要按基本逻辑想就可以
- 如果一个区域左边界趋势是向右增大、同时右边界趋势是向左增大,那么一定能在中间(包括左右边界)找到 peak 下标
- 由于题目规定
下标 -1 n 时值为 -♾,所以整个区域就符合上面假设,一定能找到答案 - 利用二分查找,每轮的 m 下标处,判断一下 m 的左右趋势,分几种情况:
- 如果 m 左边是向右增大、同时 m 右边是向左增大,那么 m 就是一个 peak
- 如果 m 左边是向左增大、同时 m 右边是向右增大,那么任意取一边继续查找就可以
- 如果 m 左边是向左增大、同时 m 右边是向左增大,那么应该继续在左边找;反之在右边找
- 元素范围
-2^31 ~ (2^31)-1,如果想在两边加入-♾的辅助元素比较麻烦,必须用int64类型,占用较大容量。 可以写一个辅助函数,判别左右趋势或取出左右的值(int64 类型)。这里选用前者方案 - 注意:由于存在
l+1 == r这种”锁死”的情况,循环条件应该是l + 1 < r,然后在循环后再判断一次
-
“162. Find Peak Element” BinarySearch
“164. Maximum Gap”
- 解法:Radix Sort
- 思路:
- 最简单的思路是先快排,然后遍历找到最大间隔,但是时间复杂度是 O(nlogn),未达到题目要求 O(n)
- 可以用 Radix Sort,在 O(n)内实现
- 要点:
- 准备一个与原始数组相同容量的 buf 数组,用于保存本次结果,每次遍历后写回
- 统计完 count 数组后,将 count 数组遍历升级为 prefix sum 数组,便于记录 buf 位置
- 放入 buf 时,要逆序遍历 nums 数组,这样刚好利用 count prefix sum 数组
- 思路:
“164. Maximum Gap” Sort RadixSort
- 解法:Bucket Sort
- 思路:
- 通过计算数组最值 maxVal、minVal,数组长度为 n,可以得出
最小间隔 d = (maxVal-minVal)/(n-1) - 可以利用 Bucket Sort,每个 Bucket 的宽度设为 d,则 bucket 内的元素一定不会成为最大间隔,最大间隔一定发生在 bucket 间
- 每个 Bucket 记录桶内的最大最小值,用于最后一次遍历时统计最大间隔
- 通过计算数组最值 maxVal、minVal,数组长度为 n,可以得出
- 要点:
- 最小 Bucket 宽度为 1
- 思路:
“164. Maximum Gap” Sort BucketSort
“165. Compare Version Numbers”
- 解法:atoi
- 思路:
- 抽象出迭代函数,可以不断抽取每一段字符串为数字
- 然后比较每次迭代抽取的结果
- 注意
1.0.0 == 1.0的情况,需要通过标识位判断是否全部迭代结束
- 思路:
“169. Majority Element”
- 思路: 这类求Majority(众数)的问题,可以用Boyer-Moore(摩尔投票法)解决,基本思路就是”小弟够多不怕对砍”。
- 步骤:
- 对某个数进行计数并记录该数,如果遇到这个数则计数加一;
- 如果不是这个数则计数减一,如果为零则重新计数。
- 最后如果计数大于 1,则遍历数组对找到的数计数,如果总数超过了 1/2,则找到了目标。
“174. Dungeon Game”
- 解法:DP
- 错误思路:
- 乍一看,就是一个普通的迷宫题,用 DP 查找”最大血量”的路径,但是有些 Case 不满足
- 进一步分析,题目要求是初始最小血量,所以在 DP 过程中应同时关注”造成的最低血量”
- 实现后,发现上述两个逻辑需要同时满足,而且这两个参数无法区分优先级,会发生逻辑冲突,无法实现 DP
- 正确思路:
- 从右下角向左上角”反向”DP,这样只需要关注最小血量即可,最后返回
dp[0][0] - 状态转移方程:
dp[i][j]=max(min(dp[i+1][j],dp[i][j+1])−dungeon(i,j),1) - DP 二维数组的初始值要设为
math.MaxInt32表示无效值 - DP 二维数组需要额外的初始层,并且设定
dp[n−1][m]和dp[n][m-1]的初始值为 1
- 从右下角向左上角”反向”DP,这样只需要关注最小血量即可,最后返回
- 错误思路:
“174. Dungeon Game” DynamicPlanning
“179. Largest Number”
- 思路:
- 可以对 nums 中的元素进行排序,排序方法两两前后组合一下,判断顺序,此顺序具有传递性,所以只需要快排就可以
- 一般可以利用语言中的快排算法直接实现,在 Go 中可以利用
sort.Slice(interface{}, func (a, b int) bool); 字符串转换同样利用现有函数,在 Go 中可以用strconv.Itoa(int) - 比较的关键是设计两个系数,比如把
a置于前面时对应的数值是factorA * a + b,factorA 起始值为 10 并循环增大到超过b; b 的系数取法类比 a 由于题目条件0 <= nums[i] <= 10^9,所以数值可能超过 int32,因此要利用 int64 为比较值 - 排序完毕要检查
nums[0],如果0说明整个数字以 0 开头,则结果无需字符串拼接,直接返回”0” - 最后返回结果要拼接字符串,注意避免字符串连续
+导致内存频繁申请;在 Go 中可以利用string([]byte{})
“187. Repeated DNA Sequences”
- 解法:HashTable + SlidingWindow + BitOperation
“198. House Robber”
- 解法:DP
- 思路:
- 推演前 4 个房间的过程就可以推出 DP 转移方程
- 设 dp[i] 为到第 i 个房间为止可抢的最大数额
- dp[0] 第一间房,数额只能是 nums[0]
- dp[1] 第二间房,有两种情况:如果抢前面不抢当前,是
dp[0] <=> nums[0]; 如果抢当前不抢前面,是dp[-1]+nums[1]这里dp[-1]表示更往前的结果是不存在的所以==0。 两种情况综合dp[1] = max(nums[0], nums[1]) - dp[2] 第三间房,同样两种情况:如果抢前面不抢当前,是
max(dp[0], dp[1]); 如果抢当前不抢前面,是dp[0]+nums[2]; 可推导出转移方程:dp[i] = max(max(dp[i-1],dp[i-2]), dp[i-2]+nums[i]) - 由于只需要历史的两步,所以可以进一步缩减为固定变量演进
- 思路:
“199. Binary Tree Right Side View”
- 解法:Tree + DFS
- 思路:
- 用中->右->左的顺序遍历结点,直接将结果记录到全局 slice
- 只有当前层级和结果数组长度匹配时才记录,避免重复记录同层元素
- 注意:
- 一定要全部遍历,这样可以找全
- 思路:
“200. Number of Islands”
- 解法:DFS
- 思路:
- 外层对 x y 两个坐标循环,检查每个坐标,一旦坐标为 1 则累加结果,并执行 dfs
- 在 dfs 内不断对周围四个方向 dfs 探索,并将数值置为 0,避免被重复探索
- 思路:
“207. Course Schedule”
- 解法:Topological Order
- 思路:
- 先将输入的 edge 整理成
map[from][]to,同时整理出每个结点的入度 - 将所有入度为 0 的结点放入 q 中
- 用拓扑排序不断遍历处理 q 中元素,删除边、如果入度减为 0 则入 q
- 在遍历过程中记录下入度达到 0 的元素数量,最后返回
zeroCount == numCourses
- 先将输入的 edge 整理成
- 思路:
“208. Implement Trie (Prefix Tree)”
- 解法:基本的 TrieTree 实现
“208. Implement Trie (Prefix Tree)” TrieTree Golang
“210. Course Schedule II”
- 解法:Topological Order
- 思路:
- 和”207. Course Schedule”算法相同,只是要求返回拓扑排序结果
- 思路:
“212. Word Search II”
- 解法:TrieTree + Backtracking
- 思路:
- 因为单词数量很大
3*10^4,所以如果都用 DFS 去尝试肯定会超时 - 可以利用 TrieTree,先把所有单词记录为 TrieTree 字典
- 然后再利用 Backtracking 在 board 中进行检索
- 因为单词数量很大
- 技巧:
- 整个过程的关键是 TrieTree 的结点,所以无需封装,直接暴露操作就可以
- 由于 TrieTree 的结点一般只标记是否找到,不便于本题记录结果,所以可以增加一个
word string记录完整字符串,以便存入结果 - 由于函数可能被调用多次,所以 TrieTree 的根结点要在进入函数后再创建,避免多次测试时混乱
- 由于同一节点可能被多次找到为最终结果(不同路径组成相同单词),可以在找到一次后设置
isWord = false,这样可以避免重复,也无需使用 map 去重
- 思路:
“212. Word Search II” TrieTree
“213. House Robber II”
- 解法:DP + 环状 array 技巧
- 思路:
- 基本 DP 思想是基于”198. House Robber”,一定要先搞懂
- 由于本题环状结构的特殊性,处理边界条件非常麻烦…
- 干脆将数组分为两部分:”不包含第一个房间”、”不包含最后一个房间”,然后分别计算再取结果的最大值即可
- 改进:
- 储存时只保存下标节省更多容量
- 在删除 heap 元素时需要 O(n)的遍历,效率较低, 可以在 heap 中保存 end 时间,以便 O(logn)删除 heap 元素 (每次先将当前 end 之前失效的元素删除)
- 思路:
“213. House Robber II” DP Golang
“214. Shortest Palindrome”
- 解法:RollingHash + 回文简化分析
- 思路:
- 本题的关键约数是字符串长度规模
5 * 10^4,使得通常的回文识别方式无法满足性能要求(DP 和双向遍历都是O(n^2)) - 分析题目,可以想象出,最终的结果有三部分组成:s1 + s2 + s3,其中 s1 表示前面新增的字符串,
s == s2+s3后面两个就是输入的参数, s2 具有回文特性,这样新增的 s1 只要满足 s3 的镜像关系就可以了 - 所以题目简化为:寻找输入的字符串 s 的最长回文前缀子串(然后只需拼接就可得到答案)
- 可以利用 RollingHash 进行规模较大的回文识别,可以利用回文字符串的镜像特性,只需要某字符串从左向右(left)和从右向左(right)生成的 hash 值一致即可。
- 有左右两边 RollingHash 公式:
left = left*Base + s[i]、right = right + s[i]*factor, 这里 factor 是乘积系数,伴随字符串增长,factor = factor * Base - 求出最长回文长度后,只要把 s3 镜像,就可以作为 s1 拼接到结果中
- 本题的关键约数是字符串长度规模
- 要点:
- 由于字符是小写字母,Base 可以取 26,同时每个元素可以取
s[i]-'a' - 由于累加值可能很大,计算过程需要取模
int(1e9+7)
- 由于字符是小写字母,Base 可以取 26,同时每个元素可以取
- 思路:
“214. Shortest Palindrome” SlidingWindow RollingHash
“215. Kth Largest Element in an Array”
-
解法 1: Sort
- 思路:
- 利用标准库的 sort 排序,然后直接返回目标
- 时间复杂度:
O(nlogn)
- 思路:
-
解法 2:KthLarget(nth_element)
- 思路:
- 参考
nth_element算法
- 参考
- 时间复杂度:
O(n) - 其他:
- 虽然时间复杂度更低了,但是由于规模较小,耗时可能更长
- 思路:
“215. Kth Largest Element in an Array” Sort
“216. Combination Sum III”
- 解法:Backtracking
- 思路:
- 这道题是”39. Combination Sum”和”40. Combination Sum II”的加强版,有几点变更:
- 备选元素数组需要自己根据入参范围创建
- 有元素数量的限制:必须达到数量才计入答案、超过数量不在搜索
- 每次递归中当前元素只取一次
- 由于备选元素是自己制备的,是有序的,可以在
v > tar时提前退出循环
- 这道题是”39. Combination Sum”和”40. Combination Sum II”的加强版,有几点变更:
- 思路:
“216. Combination Sum III” Backtraking
“218. The Skyline Problem”
- 解法:LineSweep
- 思路:
- 将一栋楼的坐标点拆解为 start 和 end,然后顺序遍历处理,遍历过程中维护一个 Heap,用于计算当前轮廓点
- 遍历过程中维护一个 maxHeight,如果当前是 start,则入堆;如果当前是 end,则删除一个同高度;
- 在遍历过程中,记录会造成轮廓变化的点
- 要点:
- 为了便于 start 和 end 排序,将 start 按负数处理,这样 start 会排到前面
- 对于同一坐标下最高的 start 会加入到最终结果数组,所以同一坐标下高度越高的 start 点应排在前面,按负数处理正好符合这个情况
- 遍历处理 end 点时,要从 Heap 中找到一个相同高度元素删除,这时要用到 heap.Remove 接口
- 思路:
“218. The Skyline Problem” LineSweep Golang
“220. Contains Duplicate III”
- 解法 1: SlidingWindow + OrderedMap
- 这种解法难度对于 C++属于”normal”,可以直接利用
set<int>的高性能红黑树;对于 Golang 属于”hard”,需要手动实现 Treap 或 Skiplist - 思路:
- 以 SlidingWindows 保持对下标范围的控制,始终保持窗口内元素下标合法
- 以 OrderedMap 作为 value 的存储,可以快速判断顺序前后两个元素是否符合条件
- 时间复杂度:O(nlog(min(n,k)));空间复杂度:O(min(n,k))
- 这种解法难度对于 C++属于”normal”,可以直接利用
“220. Contains Duplicate III” OrderedMap RedBlackTree C++ “220. Contains Duplicate III” OrderedMap Treap Golang
- 解法 2(推荐): SlidingWindow + Bucket + HashMap
- 由于比较综合,这个解法属于”hard”
- 思路:
- 已知 k 为有效下标范围、t 为有效值范围
- 设 x 为当前遍历元素、y 为下标有效范围内另一元素,如果 y 在范围
[x-t, x+t]则认为命中 - 我们设每个桶容量为
t+1这样保证桶内元素一定命中 - 如果没有直接命中,也要检查一下旁边的两个桶,判断是否可能命中,这样范围仍然是常数的
- 要点:
- 由于本题范围较大,需要用 Hash 存储桶,所以设定一个函数
getID(x, w int) int, 传入x值和桶容量w,通过x/w计算得出桶的下标。 getID函数的负数处理比较特殊,为了避免+0和-0被重复计算,需要在负值时返回(x+1)/w - 1
- 由于本题范围较大,需要用 Hash 存储桶,所以设定一个函数
“220. Contains Duplicate III” Bucket Golang
“221. Maximal Square”
- 解法:DP
- 思路:
- 首先想到暴力解法:第一重循环每个元素遍历,然后二重遍历扩展检测边是否有效。但是这种方法时间复杂度过高
- DP 思路:设
dp[x][y]是以matrix[x][y]中以(x,y)为右下角坐标的一个正方形的边长。则这个边长的计算有下面三种情况:- 如果
matix[x][y]为 1,则有三个正方形可能扩展:上方、左边、左上方,当前最大变长由其中最短边长决定,有转移方程:dp[x][y] = min(dp[x-1][y], dp[x][y-1], dp[x-1][y-1]) + 1 - 如果
matix[x][y]是 0,则直接为 0 - 如果 x y 任意为 0,则最多为 1
- 如果
- 在 DP 遍历中统计最大边长,最后返回面积
- 思路:
“221. Maximal Square” DynamicPalnning
“223. Rectangle Area”
- 解法:Geometry
- 思路:
- 基本思路:求出各自面积相加,减去相交面积即可
- 画两个相交的矩形进行分析,通过 max min 函数屏蔽数值关系的不确定性
- 最后通过
max(width, 0) * max(height, 0)排除不相交的情况
- 思路:
“223. Rectangle Area” Geometry
“229. Majority Element II”
- 思路: 众数问题用摩尔投票法
- 不同点:
- 统计的数成了两个
- 最后统计时,最终结果元素要超过统计结果的 1/3
- 要点:
- 遍历统计时,只要其中一个元素可以累加/初始化(count 0->1),则 continue
- 如果无法累加/初始化,则两个元素计数都要减
“229. Majority Element II” Array Golang
“238. Product of Array Except Self”
- 题目要求:
- 不允许用除法。
- 空间复杂度为 O(1),(输出数组不算在内)。
- 解决方案:
- 创建输出数组,遍历原数组,将左边的乘积记录入输出数组。
- 从右向左遍历原数组,累积将右边的乘积计算到输出数组。
“239. Sliding Window Maximum”
- 解法:
这道题要用到 DQ(Double Queue),在 Window 逐步移动过程中,通过 DQ 维护一个最大值队列的下标
- 检查 DQ 末尾,如果对应的值比当前值更小,则弹出,最终把当前值插入。其本质是利用后端的栈结构维护一个最有效的下标值队列
- 检查 DQ 头部,如果对应的下标值已经超出了有效范围,则弹出。这样及时清除无效值
- 在遍历过程中逐步将结果记录
“239. Sliding Window Maximum” Golang
“240. Search a 2D Matrix II”
- 解法: “搜索空间缩减法 Search Space Reduction” 利用双向有序的特性,操纵一个指针的两个位置,其中一个位置的起始位置偏大,另一个起始位置偏小,比如左下角(横向偏小,纵向偏大)。然后向上、向右移动指针,直到找到答案或超出边界。整个过程都保证了未来可探索到结果,但可探索空间在不断缩小。
“250. Count Univalue Subtrees”
- 解法,自创”探针法”
- 思路: 递归调用、后根遍历,每个节点向孩子传递一个整型引用(探针),孩子值与父值不同或者孩子值与子孙不同,探针引用都要增 1, 注意左右孩子分别建立探针,不要相互影响。
“253. Meeting Rooms II”
- 解法:LineSweep
- 思路:
- 将开始、结束时间拆解成两个时间点及类型,然后按时间、类型排序,结束排在前面
- 用一个数做统计,遇到结束则-1、遇到开始则+1,过程中记录最大值
- 优化:
- 可以直接一个 int 即保存时间又保存类型,
value = time<<1 + (type == start ? 1 : 0),这样按 int 排序时 end 会自动排到前面
- 可以直接一个 int 即保存时间又保存类型,
- 思路:
“253. Meeting Rooms II” LineSweep
“254. Factor Combinations”
- 解法:Math + Backtracking
- 思路:
- 本题类似”39. Combination Sum”,不同点是之前要维护一个剩余数量,这里要维护一个乘积(product)
- 直接对所有
[1,n^(-2)]的元素进行尝试,会超时,因为数据规模为10^7 - 可以先用数学方法(取余+相除)求得数 n 的因子列表,然后再用 Backtracking 解决
- 思路:
“264. Ugly Number II”
- 解法:Math+DP
- 思路:
- 可以把未来所有可能数字放在堆,然后逐步取出,但是这种方法太浪费空间
- 对于任意有效丑数 x,$x=(k_{x}2)(k_{y}3)(k_{z}*5)$,其中$k_{x}$表示正数系数
- 设 dp[i]为第 i 个丑数,每次都要尽量找到最接近的下一个有效值,有
i > kx && i > ky && i > kz, 每次演化的值可以从 dp 历史值取得$dp[i]=min(dp[k_{x}]×2,dp[k_{y}]×3,dp[k_{z}]×5)$ - 所以只需要逐步提高最小的系数,就可以推演出最终结果
- 思路:
“264. Ugly Number II” Math Golang
“268. Missing Number”
-
解法 1: 排序
- 时间复杂度:O(nlogn)
-
解法 2: HashMap
- 空间复杂度:O(n)
-
解法 3: XOR
- 思路:
- 利用”异或两次可消除”的特性,先对数组遍历求一个 xor 值
- 再对
[0,n]进行一次遍历叠加 xor 值 - 最后的 xor 值即为缺少的元素
- 思路:
“268. Missing Number” BinaryOperation Golang
- 解法 4: Math
- 思路:
- 按照等差数列求和公式
total = n(n+1)/2可以求得[0,n]元素完整时的总和 - 然后再求得数组元素和
sum - 最终缺失的元素就是
total - sum
- 按照等差数列求和公式
- 思路:
“268. Missing Number” Math Golang
“269. Alien Dictionary”
- 解法:拓扑排序
- 思路:
- 分析题目,我们的目的是通过已知字典的字母顺序关系推导出字典字母顺序,可以用拓扑排序实现
- 步骤:
- 用二级 map 记录先序字母和后续字母的关系,用另一个 map 记录每个字母的”入度”
- 遍历所有单词、字符,创建所需 map、初始化入度
- 从下标 1 开始遍历 words,比较
words[i]和words[i-1]的每个字母,如果从某个字母开始不同,则可记录一个先序后序关系 - 将所有入度为 0 的元素放入 queue
- 用拓扑排序处理元素、同时记录答案
- 最后确定答案和入度元素数量一只,说明有有效答案
- 注意:
["abc","ab"]这种情况是非法的,相同前缀下字符较多的应该放在后面,要及时返回""- 最后要检查一下结果元素数量与 indegree 元素数量是否一致,如果不一致则返回
""
- 思路:
“274. H-Index”
- 解法 1:Sort + BruteForce
- 思路:
- 被引用的次数越多的文章,越容易实现要求
- 先按引用次数排序,然后倒序遍历,遇到不符合的就退出循环
- 由于引用次数这个数值本身较大容易满足,所以把文件个数作为最后返回的结果
- 错误思路:
- 由于排序后的数组对于
H-Index满足具有二分查找特性,所以可能会想到用二分查找。 但是排序本身时间复杂度是O(nlogn),所以总的时间复杂度是O(nlogn + logn) == O(nlogn), 总效率没有优化,而且增加了算法复杂度
- 由于排序后的数组对于
- 思路:
- 解法 2: CountSort + BruteForce
- 思路:
- 由于引用次数往往较大,而符合条件的文件数较小,结果为两者取其小
- 先确定最大数量为输入数组长度,利用 CountSort 统计某引用数量出现次数
- 遍历统计已满足的数量,找到最大数量
- 时间复杂度
O(n),空间复杂度O(n)
- 思路:
“275. H-Index II”
- 解法: LowerBound
- 思路:
- 基于”274. H-Index”的计数逻辑,已经有序后可以利用二分查找算法实现
- 而本题目刚好符合 LowerBound 算法
- 思路:
“275. H-Index II” BinarySearch
“279. Perfect Squares”
-
解法 1:DP
- 思路:
- 可以看称”完全背包”问题,目标数字
n就是背包容量,x^2可以看作是物品,物品数量数量不限 - 附加条件:用最少的物品个数,刚好填满背包
- 可以先把备选数字筛出来,放入数组作为物品,数字平方的最大值不超过
n - 第一层循环物品,第二层循环状态,记录可到达目标的最小个数
- 可以看称”完全背包”问题,目标数字
- 思路:
-
解法 2: DP
- 思路:
- 某个数字 n 对应的最小值可以由前面某个位置推算过来,所以可以对 n 做个 DP 演化
- 演化时,无需把物品提前计算出来放到数组,可以直接利用
x^2;x++遍历”物品”
- 思路:
“279. Perfect Squares” DynamicPlanning
“295. Find Median from Data Stream”
-
解法 1: Heap
- 思路:
- 用上下两个堆维护所有元素,中间可以取值作为查询结果,看起来像两个尖端相对的三角形的
- 上面一个最小堆,下面一个最大堆,始终保持上面放最大的数据、下面放最小的数据,然后由两个堆顶决定结果
- 如果总数为偶数,则取两个堆顶的平均值;如果为奇数,则让上面最小堆多一个元素,取最小堆的堆顶
- 注意:
- 为了保证最小堆元素始终大于最大堆,每次新元素到来要先加入最大堆,再从最大堆 pop 一个到最小堆
- 思路:
“295. Find Median from Data Stream” StructDesign
-
解法 2: OrderedMap + TwoPointers
- 思路:
- 类似 Heap,但是用 OrderedMap 保存元素,用两个指针分别表示堆顶位置,实际上一个指针也可以
- 根据新加入元素的大小和元素总数的奇偶性对指针进行移动
- 优点:
- 题目要求的扩展”99% 的整数都在 0 到 100 范围内”,可以结合计数排序,超出范围的用 OrderedMap 保存
- 思路:
-
解法 3: CountSort + TwoPointers
- 思路:
- 题目扩展”所有整数在 0 ~ 100”,可以利用 Bucket+TwoPointers 实现
- 思路:
“297. Serialize and Deserialize Binary Tree”
- 解法:DFS + parse
- 思路:
- 最简单的方案是每个结点用
(x)框起来,反序列化时利用全局 index parse 就可以,parse 时的基本单位也是(x)
- 最简单的方案是每个结点用
- 要点:
- 用
strings.Builder减少字符串拼接成本 - 数字转换可以用
strconv.Atoi/strconv.Parse或自己写转换逻辑,要注意负数、字符串大小端方向问题 - 可以利用闭包减少参数和全局变量
- 用
- 思路:
“297. Serialize and Deserialize Binary Tree” DFS
“300. Longest Increasing Subsequence”
LIS是动态规划的常见问题
-
考点:
- 一维数组二维 DP、LIS(最长上升子序列)
-
解法 1:
- 思路:
- 原数组不能排序,否则无法取得最终结果
- 设
dp[i]表示第 i 个位置的元素与前面形成的最长子序列长度,那么dp[i]可以由前面遍历推算出 - 有状态转移方程
dp[i]=max(dp[j])+1,0≤j<i && num[j]<num[i] dp[i]初始值设为 0,最后结果要+1,表示自身也算 1 的长度
- 时间复杂度:O(n^2)
- 思路:
“300. Longest Increasing Subsequence” DP Golang
- 解法 2: DP + Lowerbound
- 思路:
- 贪心思维:在已有最长子序列基础上用尽可能小的新元素替换旧元素,使得未来上升时长度可以更长
- 维护一个数组
d[i]表示长度为 i 的最长上升子序列末尾元素的最小值, len 记录最长上升元素数、起始 len 为 1、d[1]==nums[0]
- 步骤:
- 遍历 nums,更新 d,如果
nums[i] > d[len],则d[len+1]==nums[i]; 否则在1~len中找到d[i-1] < nums[j] < d[i]并更新d[i]=nums[j] - 由于 d 本身的有序性,可以利用
Lowerbound算法查找
- 遍历 nums,更新 d,如果
- 时间复杂度: O(nlogn)
- 思路:
“300. Longest Increasing Subsequence” BinarySearch Golang “300. Longest Increasing Subsequence” BinarySearch C++
“307. Range Sum Query - Mutable”
- 解法:BIT
- 思路:
- 标准 BIT 的应用场景,频繁对数组更新、求和
- 注意:
- 每次 update 时不是 delta 而是 value,需要求一下 diff 值
- 思路:
“307. Range Sum Query - Mutable” BinaryIndexedTree C++
“312. Burst Balloons”
-
解法(推荐): DFS + Memory
- 思路:
- 用 memo[i][j]记录[i,j]区间内的最大值
- 假设打破气球的位置是 k,
i <= k <= j,我们假设 k 是区间内最后一个打破的气球,这样容易计算 - 然后套用区间 DP 模板(DFS+Memory)实现
- 注意:
- 区间内位置 k 最后一个打破的分数,要用到区间外的元素
i-1和j+1,所以需要区间边缘虚拟元素处理 - 区间内的分值由三部分相加得出:
[i,k-1] + k最后一个打破分数 + [k+1,j]
- 区间内位置 k 最后一个打破的分数,要用到区间外的元素
- 思路:
“312. Burst Balloons” DFS+Memory Golang
- 解法:区间 DP
- 思路:
- 把戳破气球反向理解为从两边为 1 的数组中增加气球,
增加新气球时分数 = 新增气球*左边区域最高分*右边区域分数 - 每个尝试新增气球被认为是一段区间内第一次插入的气球
- 先从范围为 1 的区间开始计算,逐步扩大范围,相当于除第一次插入外,其他都已经计算出结果
- 把戳破气球反向理解为从两边为 1 的数组中增加气球,
- 步骤:
- 在数组左右两遍增加一个值为 1 的元素,以便 dp 使用
- 初始化
dp[i][j]表示[i,j]可以取得的最大分数 - 第一层循环 l,1->n 表示每次处理的判断范围
- 第二层循环 i,1->n 遍历所有位置,j = i+l-1
- 第三层循环 k,i->j 遍历范围内所有位置,作为分割点
dp[i][j] = max(dp[i][j], dp[i][k-1] + vals[i-1]*vals[k]*vals[j+1] + dp[k+1][j])s
- 思路:
“312. Burst Balloons” DP Golang
“313. Super Ugly Number”
- 解法:Math + BFS + Heap + HashTable
- 思路:
- super ugly number是指,质因数都出现在指定数组中,数组隐含包含了 1。 也就是未来所有生成数都要由数组中的数相乘得出
- 为了优先生成较小的数,可以利用最小堆实现,默认 1 入堆
- 每轮处理,拿堆顶跟数组中所有元素相乘然后入堆
- 通过处理的轮数确定是否为答案
- 由于乘积过程可能产生相同的元素,所以入堆前要进行 map 检查
- 思路:
“315. Count of Smaller Numbers After Self”
- 解法:BIT + Discretization(离散化处理)
- 思路:
- 直观思路是两重循环统计,但是题目规模为
10^5,O(n^2)的时间复杂度无法满足要求, 考虑用O(logn)的 BIT 优化为O(nlogn) - 先创建一个空的 BIT,容量为所有可能元素,每个元素出现过一次就记 1,
这样可以用
preSum(i-1)求得任意时刻小于 i 的元素的总和 - 准备好结果数组,从右向左遍历原数组,统计比该元素小的元素数量,然后将当前元素添加到 BIT
- 由于元素范围较大并且存在负数,无法直接使用 BIT,所以需要利用 map 进行离散化处理,具体参考代码
- 直观思路是两重循环统计,但是题目规模为
- 思路:
“315. Count of Smaller Numbers After Self” BinaryIndexedTree
“322. Coin Change”
- 考点:
- DP、完全背包
“324. Wiggle Sort II”
- 解法:
- 利用nth_element函数在 O(n)时间内,在中间位置左边排序,保证左边比右边小,并返回中间位置的值。
- 将左边有序的较小数的奇数下标位置替换为右边特定位置的较大数(注意循环结束条件是
j <= k,判断条件是 j 与 mid 的关系)。 - 使用
(1+2*(i)) % (n|1)对所有奇数位置比较和替换,后面的(n|1)来保证不论 n 是奇偶,取模后都是奇数位置。 - 使用宏函数,避免过多重复代码。
“324. Wiggle Sort II” Sort C++
“326. Power of Three”
- 解法 1: loop
- 思路:
- n 不断除以 3,检查结果是否对 3 取余为 0
- 最后结果一定是 1
- 思路:
“326. Power of Three” Math loop
- 解法 2: Math
- 思路:
- int32 最大的 3 的幂是
3^19,那么任意 3 的幂3^x和最大可能值有如下关系:(3^19)/(3^x) = 3^(19-x) - 可以推出
0 <= 19-x <= 19一定是一个整数,所以(3^(19-x))%3 == 0
- int32 最大的 3 的幂是
- 思路:
“327. Count of Range Sum”
- 解法:BIT + Discretization(离散化处理) + 公式变换
- 思路:
- 题目要求
i<j; lower < s(i,j) < upper,其中s(i,j)可以用 preSum 实现preSum[j]-preSum[i] - 如果直接双循环统计结果,时间复杂度为
O(n^2),由于数据规模高达10^5,所以会超时,需要进一步简化 - 公式变换
lower < preSum[j]-preSum[i] => preSum[i] < preSum[j]-lower,从公式可以看出,在遍历 preSum 当前下标为j时只要统计比preSum[j]-lower更小的元素数量即可。同理推导出preSum[j]-upper < preSum[i], 进一步缩小了统计范围preSum[j]-upper < preSum[i] < preSum[j]-lower。 - 对一定范围的元素数量做快速统计,可以利用 BIT 实现
- 由于本题的元素范围较大,需要用离散化处理可能元素,包括
preSum[i]和preSum[i]-upper
- 题目要求
- 思路:
“327. Count of Range Sum” BinaryIndexedTree
“332. Reconstruct Itinerary”
- 解法:欧拉路径 Hierholzer Algorithm
- 思路:
- 当前问题正好是每张票用一次并全部用掉,符合欧拉路径
- 思路:
“332. Reconstruct Itinerary” Graph C++
“336. Palindrome Pairs”
- 解法:回文对逻辑分析 + TrieTree/HashMap(string)/RollingHash
- 思路:
- 两个字符串拼接为回文,长度有两种情况:相同长度/长度不同
- 对于相同长度的,只要找到与 A 完全反转的 B,那么”A+B”和”B+A”都是答案
- 对于长度不同的,假设
len(A+B) > len(A‘),只要较短的A'和A对称即可, 考虑到较长的左边、右边都要进行匹配尝试 - 可以先把所有字符串的特征记录在特定数据结构中,以便进行高效匹配
- 寻找反转匹配可以用下面三个方法:
- 直接用 HashMap 保存字符串、反转字符串及下标,然后在遍历过程中匹配子字符串 (对于 Go 语言,由于子字符串抽取性能损耗较大,所以性能偏差)
- 利用 TrieTree 保存原有字典,在遍历时进行查询
- 利用 RollingHash 生成每个字符串的正向、反向 Hash,以便在遍历时匹配
- 思路:
“337. House Robber III”
- 解法:tree+recur+dp 每次递归负责返回本层被选择和不选择两个结果
“337. House Robber III” Golang
“338. Counting Bits”
-
解法 1: bit
- 利用
onesCount算法,计算 0~n 每一个数的结果 - 时间复杂度:
O(n*32),假设 32 位整型
- 利用
-
解法 2: bit + dp
- 已知用
n&(n-1)算法可以求得 n 去掉最后一个 1 的值 - 有基本规律
0 <= n&(n-1) < n,所以任意 n 一定能用 n-1 推导出来,这正好符合动态规划特征 - 所以有动态转移公式
bits[x]=bits[x&(x−1)]+1 - 时间复杂度:
O(n)
- 已知用
“338. Counting Bits” DynamicPlanning Golang
“354. Russian Doll Envelopes”
- 解法 1: 二维元素一维化处理 + dp
- 思路:
- 这道题和
300. Longest Increasing Subsequence看起来类似,就是判断每个元素有多少元素能装进去形成单调序列 - 但是这道题是二维的,可以先对其中一维(如宽度)进行排序,然后剩下一维可以参照LIS算法实现
- 注意在第一维有序基础上,第二维(如高度)要逆序,即(宽度相同的情况下)后面的保证无法装下前面的,这样避免第二维间的后效性
- 这道题和
- 思路:
“354. Russian Doll Envelopes” DP Golang
“363. Max Sum of Rectangle No Larger Than K”
- 解法 1: 二维压缩 + 暴力计算
- 思路:
- 先利用”前缀和”对每一行压缩
- 利用相同方法,再对每一列压缩
- 之后可以利用二维两个坐标点确定一个矩形范围,遍历所有矩形计算出结果
- 要点:
- 注意最后计算范围结果时,要将重复减去的范围值加回来
- 思路:
“363. Max Sum of Rectangle No Larger Than K” Array
- 解法 2: OrderedMap
- 思路:
- 对行进行双重遍历,累加 ri~rj 每行的值,转化为一维数组
- 对一维数组进行 preSum 后,有公式
sr - sl <= k => sr - k <= sl,这时,如果有x >= sl则sr - x可作为备选项 - 可以把 preSum 的遍历过程用 OrderedMap 处理,快速求出
sr - k的lowerBound
- 时间复杂度:
O((m^2)(nlogn)) - Go Treap 的实现参考”220. Contains Duplicate III”
- 思路:
“363. Max Sum of Rectangle No Larger Than K” OrderedMap
“367. Valid Perfect Square”
- 解法:二分查找
- 思路:
- 类似”69. Sqrt(x)”,找到目标后要验证一下
- 思路:
“368. Largest Divisible Subset”
- 解法:DP + LIS + 反推 DP 结果
- 思路:
- 本题的基本思路参照
300. Longest Increasing Subsequence,必须先掌握 LIS 算法 - 由于题目对结果顺序没有要求,所以先对原数组排序,以便进行 DP 处理
dp[i]表示到nums[i]为止的最大长度,利用整除的数学特性逐步迭代- 在迭代过程中要记录最大长度和对应的最大值,以便最后反推,计算出最终结果
- 本题的基本思路参照
- 思路:
“368. Largest Divisible Subset” DP Golang
“374. Guess Number Higher or Lower”
- 解法:BinarySearch
- 要点:
- 最大值范围
(2^31)-1,可以变形模板r = n,最后返回r
- 最大值范围
- 要点:
“374. Guess Number Higher or Lower” BinarySearch
“377. Combination Sum IV”
-
解法 1:dfs+memory
-
解法 2:DP(多重背包)
- 考点:
- 统计排列组合,第一层状态循环、第二层物品循环
- 考点:
“377. Combination Sum IV” DFS C++ “377. Combination Sum IV” DP Golang
“380. Insert Delete GetRandom O(1)”
- 解法:HashTable + Array 实现 O(1) 数据结构
- 思路:
- 元素放在 Array 中,以便方便的随机选取
- 利用 HashMap 实现 O(1)查询,key 保存元素值,value 保存元素在 Array 中的下标
- 思路:
“380. Insert Delete GetRandom O(1)” StructDesign
- 解法:二维 HashMap + Array 实现可重复 O(1) 数据结构
- 要点:
- remove 函数的实现较为复杂,基本思路是:记录最后一个元素值、删除当前元素、删除最后一个元素旧下标、新增最后一个元素新下标、删除多余内容
- 如果删除的当前元素正好是最后一个值,则要特殊处理,避免再添加进来
- 要点:
“381. Insert Delete GetRandom O(1) - Duplicates allowed” StructDesign
“381. Insert Delete GetRandom O(1) - Duplicates allowed”
“381. Insert Delete GetRandom O(1) - Duplicates allowed” StructDesign
“382. Linked List Random Node”
- 解法:ReservoirSampling
- 思路:
- 每次采样,对所有元素遍历一遍,利用 ReservoirSampling 取得结果值
- 思路:
“382. Linked List Random Node” Random
“384. Shuffle an Array”
- 解法:Fisher-Yates Shuffle
- 要点:
- 要保留初始的数组以便
reset返回 - 要保留被随机后的数组,以便下次继续对其随机处理,否则由于随机种子被重置,无法真正实现随机,Case 会不过
- 要保留初始的数组以便
- 要点:
“384. Shuffle an Array” Random Golang
“395. Longest Substring with At Least K Repeating Characters”
- 考点:滑窗、常数内尝试
- 思路:
- 从”子数组连续”这个特性,想到用 SlidingWindow
- 控制窗内元素种类是个难点。由于字母集合总数有限,干脆尝试 1 ~ 26,共 26 次,不影响时间复杂度
- 在滑窗过程中记录几个关键参数:每种字母个数、已包含字母种类、当前未达到 k 个的字母种类数
- 在新增、删除元素时,维护好”当前未达到 k 个字母种类数”,然后当条件符合时更新最大长度结果
“395. Longest Substring with At Least K Repeating Characters” SlidingWindow Golang
“398. Random Pick Index”
- 解法:ReservoirSampling
- 思路:
- 类似”382. Linked List Random Node”,需要对所有元素遍历一遍才可以保证概率相同
- 只有指定的元素才参与随机,所以增加一个判断条件
- 思路:
“398. Random Pick Index” Random
“403. Frog Jump”
- 解法:DP
- 思路:用二维 map 或二维数组都可以
- 记录青蛙能到达的下一个位置和本次跳跃步数,直到得出结果
- 时间复杂度 O(n^2),空间复杂度 O(n^2)
- 思路:用二维 map 或二维数组都可以
“406. Queue Reconstruction by Height”
- 插入法思路:
- 个小的插入个大的前面,不影响排序规则,所以个头大的先插入。
- 同样个头的,对前面人数要求越少的应该越早进行插入操作。
- 输入是保证有效的,所以直接在对应位置插入即可。
“406. Queue Reconstruction by Height” C++
“410. Split Array Largest Sum”
- 解法:BinarySearch + Greedy
- 思路:
- 题目要求是连续子串,所以无需考虑最优分配方案,直接按连续分配即可
- 想要找到合适的桶容量,可以利用二分查找算法
- 桶的最小值,应该是最大的单个元素;桶的最大值,是所有元素的和
- 思路:
“413. Arithmetic Slices”
-
解法:Math
- 思路:
- 通过手动 DP 分析,可以看出序列长度和结果间的关系:
3, 1=14, 3=1+25, 6=1+2+3结果本身是等差数列求和 - 很容易通过遍历获得等差数列的长度,需要用到等差数列求和公式
sum = n(a1+an)/2
- 通过手动 DP 分析,可以看出序列长度和结果间的关系:
- 注意:
- diff 初始化为 2001,这样可以超出最大范围,以便下次替换
- 最后一次遍历(n-1)时,所做的处理和每次切换 diff 逻辑相同
- 优化:
- 可以看出每轮 count 的增长和等差数列有对应关系,可以直接利用 count 累加避免用求和公式,
同时还可以简化逻辑,避免对
n-1处理
- 可以看出每轮 count 的增长和等差数列有对应关系,可以直接利用 count 累加避免用求和公式,
同时还可以简化逻辑,避免对
- 思路:
“414. Third Maximum Number”
- 解法:BF
- 思路:
- 用三个变量 a b c 分别表示最大、次大、第三大的元素,然后遍历数组元素,从大到小进行判断
- 为了避免 int32 边界值的问题,用指针类型
- 注意:
- 我们只关心符合严格条件的元素,比如重复元素,可以用条件自动过滤掉;或者比第三大元素还小的也自动过滤掉
- 由于 Go 循环中使用了相同变量,导致无法使用指针,要重新定义局部变量
- 思路:
“415. Add Strings”
- 解法:
- 思路:
- 这道题是常用的进位累加思路,同时维护数组指针 p1、p2 和进位数 carry,循环处理直到三者全部”耗尽”
- 注意生成的结果 slice 是反向的,需要执行一次反转
- 思路:
“416. Partition Equal Subset Sum”
- 思路:dp
- 这是一个变形的零一背包问题
- 要想分割成两个子集,需要满足两个条件:
- 数组和为偶数,这样才可能平分成两个整数
- 任意一个元素不能超过 1 半,否则无法平分
- 通过上述演化,可以演化为一个简易的零一背包问题(只需要保存 bool 型,无需计算价值)
“416. Partition Equal Subset Sum” Golang
“417. Pacific Atlantic Water Flow”
- 解法:DFS
- 思路:
- 题目是某个点的水既可以向太平洋也可以向大西洋流,可以反向理解为, 大西洋/太平洋的水向上流到最高点,然后统计两个海洋覆盖的点的交集
- 改进:
- 可以利用 in-place 记录每个点是否能关联到某个海洋
- 思路:
“421. Maximum XOR of Two Numbers in an Array”
- 解法:XOR + HashMap
- 思路:
- 题目用双重循环很容易实现,但是要求 O(n)时间复杂度,需要进一步设计
- 设最终找到的数为 x,那么 x 的高位二进制 1 越多结果越大,所以我们考虑按位从高到低找 1
- 根据 XOR 运算特点有
x = a^b <=> a = x^b - 假设
pre_k_x为 x 的前 k 位,则同样有pre_k_a = pre_k_x ^ pre_k_b - 我们对每一位尝试查找是否存在 1,然后查找过程类似”1. Two Sum”,利用 HashMap 实现快速查找
- 时间复杂度计算:O(nlogC)
其中 n 是元素数量、C 是元素值的范围,本题是
(2^31) - 1,由于logC = 31,所以最终时间复杂度符合O(n)要求
- 思路:
“421. Maximum XOR of Two Numbers in an Array”BinaryOperation Golang
“424. Longest Repeating Character Replacement”
- 解法:SlidingWindow
- 思路:
- 可以设想一个窗口,右端向右移动,如果字符相同则不会消耗 k,可以继续增长;如果字符不同,则消耗 k,并且左边右移一次
- 关键是如何判断”k 消耗完了,左边要右移一次”,
maxNum + k < r - l + 1 - 最后返回窗口大小就行,窗口在整个过程只会增加不会减小
- 思路:
“424. Longest Repeating Character Replacement” SlidingWindow
“430. Flatten a Multilevel Doubly Linked List”
- 解法:DFS + LinkedList
“435. Non-overlapping Intervals”
- 解法:Greedy
- 思路:
- 按照 end 时间将 interval 排序,我们想寻找尽量早结束的 interval 这样后面独立 interval 数量可能更多
- 排序后遍历,如果 interval 是独立的,则更新 end 值,否则 count++
- 思路:
“435. Non-overlapping Intervals” Greedy Golang
“437. Path Sum III”
- 解法:Tree + Backtraking + PrefixSum + HashMap
- 思路:
- 利用 DFS 进行遍历,并记录中间的路径元素,在叶子结点时,可以从后向前遍历求和,判断是否存在 target
- 但是上面的方法在每个计算时,时间复杂度为
O(n^2),整体时间复杂度为O(n^3),性能太差,可以利用”Two Sum”的方法优化 - 可以利用 PrefixSum 记录路径上的前缀和,利用 Backtraking 模式维护
- 历史 PrefixSum 的值存储在全局 HashMap 中,假设历史数据 x 在 preSumMap 中,那么 x 出现次数可表示为
preSumMap[pre - target] - 最后统计返回结果
- 思路:
[]
“440. K-th Smallest in Lexicographical Order”
1 | |
- 解法:TrieTree + 逐步逼近法
- 思路:
- 题目的”字典序”比较特殊,其特点是
x+1 > x*10,即2 > 10 - 可以将符合字典序的元素组成一个 10 叉 TrieTree,每个结点有 10 个子结点,对这个树的先序遍历即为答案
- 题目要求 n 以内的数组成的数,找到先序遍历第 k 个结点,结点要把子结点遍历完才开始遍历下一个兄弟结点, 因为存在限制,所以形成的树的高度、最后一层的宽度都是受限的
- 可以类比”74. Search a 2D Matrix”的逼近法,先找到对应的行,再查找对应的列。在 TrieTree 中也是一样,先趋近找到层数,然后再找到本层的某个位置。
- 需要一个辅助函数
getCount(int) int传入当前的前缀,取得该前缀下可能的子结点数,要求所有节点在 n 范围内。 函数中求每层结点时,只要用本层下一个前缀开头第一个元素减去本层第一个元素即可。例如2-1; 20-10; 200-100; - 先通过
prefix++找到边界父前缀,然后再prefix *= 10统计子结点范围内元素
- 题目的”字典序”比较特殊,其特点是
- 注意点:
- 在
getCount函数中,如果范围已经大于n,则取右边界为n+1
- 在
- 思路:
“440. K-th Smallest in Lexicographical Order” Tree
“446. Arithmetic Slices II - Subsequence”
- 解法:DP + HashMap
- 思路:
- 首先手动演化一下子序列,发现子序列已有结果和新增一个的关系:
newCount = oldCount+1; total = newCount + oldCount - 设两个数字可形成”弱等差序列”,dp[i][d]是尾项为 nums[i]公差为 d 的弱等差数列的数量
- 用双层循环遍历,外层 i > 内层 j,
d = nums[i] - nums[j],则根据前面演化可得转移方程dp[i][d] += dp[i][j] + 1 - 在循环时,当已存在 d 的等差数列时才统计结果,避免弱等差数列计入结果
- 由于 d 的范围很大,所以用 map 保存
- 首先手动演化一下子序列,发现子序列已有结果和新增一个的关系:
- 思路:
“446. Arithmetic Slices II - Subsequence” DynamicPlanning
“447. Number of Boomerangs”
- 解法:HashMap
- 思路:
- 只要有某三点组成的两边距离相同则符合条件
- 可以双重遍历,外层对每个元素循环,内层循环记录到外层元素的距离,用 HashMap 即可检测是否有相同距离的点
- 由于不同排列算两个结果,所以结果累加时要
*2
- 优化:
- Go 可以在每轮遍历时重用 map 优化
- 思路:
“447. Number of Boomerangs” HashTable
“448. Find All Numbers Disappeared in an Array”
- 考点:
- array 操作
- 约束条件:无额外空间占用
- inplace 思想
- 思路:
- 题目保证数字只会出现在给定范围并保证正整数,所以可以利用高位做特殊标记,比如利用负数做是否存在的标记
- 第一遍遍历,把出现过的数字对应的下标元素置为负数,那么剩下未标记为负数的位置对应的值就未出现过
- 对应的,访问每个元素时,要注意把负数恢复为正数,然后再取对应下标
- 第二遍遍历,将仍然为正数的下标对应的数值记录,作为结果返回
“448. Find All Numbers Disappeared in an Array” Golang
“456. 132 Pattern”
- 思路:
- 只要直到任意位置左边最小值和右边最接近的较小值,就可以判断是否有符合条件的值
- 先从左向右遍历,记录每个位置左边的最小值
- 再从右向左遍历,利用单调栈记录比当前值更大的值,当较小值出栈时进行一次条件判断
“457. Circular Array Loop”
-
解法:in-place
- 思路:
- 可以利用原位置保存两个信息:是否被访问过 + 访问时的轮次编号
- 如果判断下一结点被访问过,并且方向相同,则返回 true
- 时间复杂度:
O(2n) => O(n) - 缺点:
- 由于二进制操作比较麻烦,逻辑会非常复杂
- 为了兼容二进制负数,也会增加逻辑复杂性
- 思路:
-
解法(推荐):快慢指针
- 思路:
- 题目要求
O(n)时间复杂度和O(1)空间复杂度,可以利用”快慢指针 + 访问标记”的方式实现 - 最外层,对每个元素遍历
- 循环内,按照快慢指针向后查找同向位置,如果找到则返回 true
- 循环内,如果没有找到,则再执行一次遍历,把上面已经走过的位置值置为 0,确保未来不被遍历到
- 题目要求
- 要点:
- 判断是否同向,可以用
x * y > 0判断 - 取得下标余数,可以
((cur+val)%n + n) % n
- 判断是否同向,可以用
- 时间复杂度:
O(2n) => O(n)
- 思路:
“457. Circular Array Loop”TwoPointers
“460. LFU Cache”
- 解法:HashMap + List
- 思路:
- 元素变动特性:每次一个元素频率改变时,这个频率只能增 1,所以只会影响到临近的频率列表
- 两个 Map:一个存储所有频率及其对应的元素链表;一个存储元素信息(值、频率、频率链表结点指针)
- 当有元素需要变更频率时,可以利用 map 和链表指针快速变更,链表结点插入到新频率末尾
- 始终记录最小频率值,如果添加新元素时容量已满,则删除一个频率最低的头部旧元素
- 思路:
“461. Hamming Distance”
- 汉明距离广泛用于多个领域,在编码理论中用于错误检测,在信息论中量化字符串之间的差异。两个整数之间的汉明距离是对应位置上数字不同的位数。
- 一般语言都会自带函数,这里要自己实现
- 解法:
- 两个数取异或,则结果中的 1 就是两者差异点,只要统计这些差异点数量即可
- 比遍历更快的方式是利用
去除x最右边的1 = x & (x-1),然后只需几次就能统计完毕
“461. Hamming Distance” Golang
“470. Implement Rand10() Using Rand7()”
-
解法 1: 暴力采样,100 次采样时不通过
- 思路:
- 用 10 个
[1,7]采样结果相加得到[10,70],然后/10取得结果
- 用 10 个
- 特点:
- 时间复杂度固定 O(7n)->O(n),但是不符合性能要求
- 思路:
-
解法 2: 拒绝采样,1000 次采样时不通过
- 思路:
- 采样两次求和,如果范围在
[2,11],则返回[2,11]-1,否则循环找到合适随机值
- 采样两次求和,如果范围在
- 特点:
- 至少采样两次,并且有
3/7概率丢弃,所以每次采样期望次数为2*(4/7+(4/7)^2+...)≈6,时间复杂度 O(6n),还是不能符合性能要求
- 至少采样两次,并且有
- 思路:
-
解法 3: 直接取余,10000 次采样时不通过
- 思路:
- 直接取余辆次,然后求和,然后和对 10 取余,再加一,
return (rand7()+rand7())%10 + 1
- 直接取余辆次,然后求和,然后和对 10 取余,再加一,
- 问题:
[1,4]的出现概率要明显高于[5~10],当采样数量大到一定程度就无法通过
- 思路:
-
解法 4:
- 思路:
- 利用
[1,7]找到最快接近[1,10]的方法,用7*7 = 49的方法,只需要两次rand7()采样就能找到最接近 40(10 的整数倍)目标 - 保留 40 以内的有效值,期望采样次数为
2*(4/5+(4/5)^2...)≈2.4,时间复杂度 O(2.4n),符合性能要求
- 利用
- 优化思路:
- 上面
[41,49]的随机值被抛弃了,实际上可以临时保留,下次凑够 10 的整数倍时还可以使用,这样用少量空间存储随机值,可以减少随机函数调用次数
- 上面
- 思路:
“470. Implement Rand10() Using Rand7()” Random
“474. Ones and Zeroes”
- 考点:
- 零一背包+二维逆序推演
- 技巧:
- 本题只求最大值,所以不用精确推算结果,在保证无后效性的同时,始终保持数组靠后为最大值即可
“474. Ones and Zeroes” DynamicPlanning
“477. Total Hamming Distance”
- 解法:
- 思路:
- 首先要明白”汉明距离”的概念,是两个二进制数间异或后 1 的数量
- 首先想到双循环,但是规模是
10^5,O(n^2)无法满足要求 - 想到先统计所有值每个位置为 1 的出现次数,然后遍历每个元素在这些位上的情况,统计出结果
- 进一步优化,某个位置如果有 m 个元素为 1,则其他元素必然累加这个 m,可以对位做第一层循环、nums 做第二层循环
- 时间复杂度:
O(n*L),其中L==30
- 思路:
“477. Total Hamming Distance” BinaryOperation
“478. Generate Random Point in a Circle”
- 解法:RejectSampling
- 思路:
- 利用随机函数生成
[0,1)之间的数,进而生成 x y 两个值,在2r*2r的正方形内,如果在圆内则采用,否则循环重试
- 利用随机函数生成
- 思路:
“478. Generate Random Point in a Circle” Random
“480. Sliding Window Median”
- 解法:heap + 延迟删除
- 思路:
- 这道题基于”295. Find Median from Data Stream”,但是增加了”滑动窗口需要动态删除元素”的条件
- 由于 heap 只能删除堆顶元素,所以需要利用 HashMap 记录已删除元素以便该元素到堆顶时再真正删除,另外维护真实的 size 以便进行 balance 处理
- 首先需要实现 heap,对于最大堆,可以利用”负数最小堆”的逻辑实现
- 为 heap 新增 prune 接口,以便发生变化时删除堆顶已被标记的元素
- 为 heap 新增 size 字段,以保存真实 size
- SlidingWindow 类作为外层封装类,同时维护一个 smallHeap(较小数、最大堆、负数) 和一个 largeHeap(较大数、最小堆、正数)
- SlidingWindow 对外提供三个接口:insert/erase/getMedian
- SlidingWindow 实现一个内部接口 balance,以便在 insert、erase 之后执行
- 最后先预处理一下前面 k 个元素,创建基本的 slidingWindow 对象,然后迭代后面的元素产生结果
- 思路:
“480. Sliding Window Median” StructDesign
“486. Predict the Winner”
- 解法:Minimax(dfs+memo)
- 思路:
- 每次可以取左边或右边,那么对手要取剩下的,剩下的范围比之前更小,所以可以利用 memo 记录
- 用二维 memo 记录结果,每次 dfs 需要 left right 两个参数限定范围
- 计算过程中只要记录两者之差会更容易,如果最后需要值,只需要根据两者之差和所有元素和计算二元一次方程即可
- 思路:
“486. Predict the Winner” Minimax
“493. Reverse Pairs”
- 解法:BIT + 离散化处理
- 思路:
- 题目类似”327. Count of Range Sum”
- 如果以双重循环处理时间复杂度过高,需要利用 BIT 统计符合
> 2 * nums[i]条件的元素数量
- 思路:
“494. Target Sum”
- 考点:
- 概率 DP、偏移重整
- 思路:
- 尝试 1、2、3 个元素的组合,可发现状态转移公式
- 利用
sum <= 1000的特性,用+1000的方式规避负数下标出现
“497. Random Point in Non-overlapping Rectangles”
- 解法:preSum + BinarySearch + Random
- 思路:
- 按照“528. Random Pick with Weight” Random的思路实现
- 不同点是计算单元是一个矩形面上的点
- 最后需要根据命中矩形同时根据偏移量求出坐标
- 要点:
- 要精确统计每个面上的点,包括边上的点,用公式:
count := (x2 - x1 + 1) * (y2 - y1 + 1) - 计算命令矩形下标时,二分查找模板中的
isLeft(m)比较难匹配,改为isRight(m)匹配。 注意点的统计是从0开始的,所以如果一个2*2的矩形,上面的点是0 1 2 3,所以4已经是右边区域了
- 要精确统计每个面上的点,包括边上的点,用公式:
- 思路:
“497. Random Point in Non-overlapping Rectangles” Random
“502. IPO”
- 解法:Greedy + sort + heap
- 思路:
- 本题初看像背包问题,但仔细分析后只需要贪心算法就可以
- 每次有一些可达的利润,用一个最大堆维护
- 先对 capital 排序,以便将可达项目的净利润放入堆
- 每次赚取一次利润后,金额值 w 增加,然后再尝试后面的项目看是否可达
- 直到所有项目做完(堆空),或 k 用尽
- 思路:
“518. Coin Change 2”
- 考点:
- 概率 DP、完全背包版
- 思路:
- 标准完全背包算法
- 注意:
- 题目是统计”组合数量”,无需考虑”排列”,所以金币的不同位置不会影响结果, 所以第一层循环必须是金币面额,这样可以避免金币位置的”后效性”
“518. Coin Change 2” DynamicPlanning Golang
“523. Continuous Subarray Sum”
- 解法:prefix sum + math(同余定理) + HashMap
- 如果两个数 x y 对某个 k 取余结果相同,那么这两个数的差值是 k 的整数倍
“523. Continuous Subarray Sum” Math
“524. Longest Word in Dictionary through Deleting”
- 解法:DP(辅助数组)
- 思路:
- 最基本的是想到用双指针,匹配比较每个字典字符串和 s,找到最大长度和字母序最小者,时间复杂度
O(d*(m+n))d 是字典元素平均长度 - 在进行每轮比较时,对于字典中的字符串,最关键的是知道下一个字母在 s 中的下一个位置。可以利用 DP 把这个位置信息先统计出来,提高匹配速度
- 最基本的是想到用双指针,匹配比较每个字典字符串和 s,找到最大长度和字母序最小者,时间复杂度
- 时间复杂度:
O(m*32 + d*n)m 是 s 长度,d 是字典元素平均长度,n 是字典元素数量。
- 思路:
“524. Longest Word in Dictionary through Deleting” DynamicPlanning
“525. Contiguous Array”
- 解法:prefix sum + HashMap
- 思路:
- 利用 preFix 分别统计 1 和 0 的数量
- 遍历中计算 1 和 0 的数量差,并记录在 HashMap,同时记录下标
- 如果数量差再次出现,说明中间段的 1 和 0 增长相同,可记录一次结果
- 改进:
- 其实关键是 1 和 0 的数量差,所以只需要一个 preSum 值就可以,遇到 1 就
++,遇到 0 就--
- 其实关键是 1 和 0 的数量差,所以只需要一个 preSum 值就可以,遇到 1 就
- 思路:
“528. Random Pick with Weight”
- 考点:
- 带权重的随机选择
- 解法:preSum + 二分查找
- 利用 pre sum 计算随机用数组
- 利用二分查找模板实现快速查找,可以在生成随机整数时
+1,这样直接利用lowerBound实现查找
“528. Random Pick with Weight” Random
“543. Diameter of Binary Tree”
- 解法:Tree + Recur
- 思路:
- 根据题目,所谓”直径 diameter”就是某结点左右两边延伸的最大长度范围
- 递归实现,假设当前结点是最终结果,计算一个值;假设当前结点是中间结点,向上返回最长距离
- 思路:
“543. Diameter of Binary Tree” Tree
“552. Student Attendance Record II”
- 解法:DP
- 思路:
- 这是一个典型的 DP 算法,根据题意可分析出 DP 状态有三个维度:当前天数 i + 已缺席数 j + 已连续迟到数 k
- 设
dp[i][j][k]为第 i 天根据结尾情况而不同的记录,可以推导出状态转移方程,详情见代码
- 思路:
“552. Student Attendance Record II” DynamicPlanning
“554. Brick Wall”
- 解法:HashMap
- 思路:
- 利用 HashMap 统计所有砖缝位置出现次数,去掉最左右两边的缝
- 返回
行数 - 某缝位置最大次数
- 思路:
“581. Shortest Unsorted Continuous Subarray”
-
解法 1: 排序
- 思路:
- 把数组想象成三段 ABC,其中 B 表示乱序的一段
- 复制数组,排序之后,遍历一遍,标记 B 的开头和结尾
- 时间复杂度:
O(nlogn)
- 思路:
-
解法 2: 遍历提取特征
- 思路:
- A 中所有元素都小于 B 中所有元素,所以只需要从右向左遍历一遍,记录 min 值和当前值的关系,就能识别出 B 和 A 的边界
- 同理可以遍历取得 B 和 C 的边界,也可以在一次遍历中双向求得边界
- 注意:
- l r 的初始值为
-1(无效值),这样可以识别出无 B 的情况,返回 0
- l r 的初始值为
- 时间复杂度:
O(n)
- 思路:
“581. Shortest Unsorted Continuous Subarray” Array
“560. Subarray Sum Equals K”
- 思路:
- 子数组和结合累加数组思想,可以把问题化简为
数组中 A - B = k <=> A - k = B - 由于可以重复统计,并且统计结果数是递增的,可以利用 map 进行累加,
map[A-K]==count - 起始处,要有
map[0]=1,以便统计独立元素直接匹配的情况
- 子数组和结合累加数组思想,可以把问题化简为
“560. Subarray Sum Equals K” HashTable Golang
“583. Delete Operation for Two Strings”
- 解法:DP-LCS
- 思路:
- 本质上就是求 LCS(“1143. Longest Common Subsequence”),然后
return m+n - 2*dp[m][n]
- 本质上就是求 LCS(“1143. Longest Common Subsequence”),然后
- 思路:
“600. Non-negative Integers without Consecutive Ones”
- 解法:DP
- 思路:
- 想到用 dfs 的方式尝试每一位为 0/1。由于存在重复检索,超时;尝试用 dfs+memo,由于数据规模太大,仍然超时;考虑用 DP 解决
- 思路:
“611. Valid Triangle Number”
- 解法 1: 排序 + 二分查找
- 思路:
- 题目是从数组中任意找到三个点,所以跟原始顺序无关,可以先排下序
- 假设有三条边 A B C,可以用两层循环确定其中两条边
- 然后根据二分查找确定是否存在第三条边,使得”两边之和大于第三边+两边之差小于第三边”
- 时间复杂度:O((n^2)logn)
- 思路:
- 解法 2: 排序 + TwoPointers
- 思路:
- 首先排序
- 设短、中、长三边下标为
i <= j <= k,确定 i 后,j 和 k 向右移动会形成一个范围, 在这个范围内都是有效的 j 值,可以利用 j k 间的 window 向右滑动的特点,利用 TwoPointers 实现 - 三层循环分别为 i j k,其中 k 的起始值为 i,所以可能存在
k-j为负数的情况 - 优先动 k 以确定最长边范围,移动 k 时,为了确保 k 有效,需要检测 k+1 是否符合
nums[k+1]<nums[i]+nums[j]
- 注意:
k - j可能为负数,需要判断一下是否累加
- 时间复杂度:O(n^2)
- 思路:
“611. Valid Triangle Number” TwoPointers
“616. Add Bold Tag in String”
- 解法:TrieTree + LineSweep
- 思路:
- 利用 TrieTree 快速判定某个单词的开始、结束位置,记录在数组中
- 利用 LineSweep 的 MergeInterval 方法把开始、结束位置合并,以便合并粗体结果
- 最后,组装结果字符串
- 注意:
- 在 TrieTree 查找结束位置时,应尽量找靠后的结束位置,以便后面的合并
- 合并时,可以利用原切片合并,最后注意缩短切片总长度
- 拼装结果时,由于字符串操作较多,需要用
strings.Builder
- 优化:
- 每次取得新 bold 范围时,可以直接合并,这样后面就不必合并处理了
- 思路:
“616. Add Bold Tag in String” TrieTree
“633. Sum of Square Numbers”
- 解法:math 分析 + 双指针
- 思路:
a^2+b^2==c考虑用双指针法从左右逼近 a 和 b。- a、b 的范围中 a==0,
b^2的最大值不会超过 c,所以b <= sqrt(c) - 由于
b^2足够大,a^2 <= (b^2-(b-1)^2),所以right只需单向运动,无需反复运动,left也是
- 思路:
“633. Sum of Square Numbers” Math Golang
“645. Set Mismatch”
- 解法:In-Place 思想 + BucketSort
- 思路:
- 题目已经给了提示,先按 In-Place 思想找到重复元素,这时当前元素位置设置为 0,表示”空洞”
- 然后继续利用 In-Place 遍历,直到所有元素归位
- 最后顺序遍历一次,找到最终空洞位置
- 思路:
“650. 2 Keys Keyboard”
- 解法 1:DP
- 思路:
- 设
dp[i]为某结果,j<i && i%j == 0,j 的结果已知,那么从 j 的结果推导到 i 有两种路线:- j 的结果重复执行
paste,则dp[i] = dp[j] * i/j - 直接从
i/j的位置用”补 1”的方式过来,则dp[i] = dp[i/j] + j - 综上两种方案,
dp[i]初始默认值为无穷大,取min
- j 的结果重复执行
- 由于 1 的特殊性,直接从 2 开始演化,无需为
dp[1]赋初值 - 由于
i%j == 0,所以j不会超过根号i,所以条件加上j*j < i
- 设
- 思路:
“650. 2 Keys Keyboard” DynamicPlanning
- 解法 2: Math
- 思路:
- 通过解法 1 的分析,可以看出,只要将 n 质因数分解,结果就可以直接由乘积得来,这样可快速得出结果
- 从 2 起始循环,查找质因数,最后如果余数大于 1 则累加到结果中
- 注意:
- 质因数分解时,同一个除数可以使用多次,如
12/2,所以第二层要用循环
- 质因数分解时,同一个除数可以使用多次,如
- 思路:
“664. Strange Printer”
- 解法 1: 区间 DP,DFS + mem 模板
- 思路:
- dp[i][j] 表示 i~j 范围最小打印的次数
- 有两种转移方程:对于
s[i] == s[j]的情况,新增左边或右边的字符不增加打印次数,memo[l][r] = min(dfs(l+1,r), dfs(l,r-1)) - 如果
s[i] != s[j],则从中间某点分割,求的最优解,memo[l][r] = min(memo[l][r], dfs(l,k) + dfs(k+1,r))。 由于中间段已经有结果,所以直接利用即可。 - 在递归开始要先对当前 dp 赋一个保底值
math.MaxInt32
- 思路:
- 解法 2: 区间 DP 模板
- 思路:
- 依据上面思路,修改为区间 DP 模板
- 优点:
- 节省了递归调用栈的空间复杂度
O(n) - 由于控制了 DP 方向,无需 Memo,节省了空间
- 节省了递归调用栈的空间复杂度
- 注意点:
- 直接设置
dp[i][i] = 1 - 遍历所有区域前,要设置初值
dp[i][j] = math.MaxInt32,避免被初始 0 值干扰 - 注意 k 的范围,允许取得单个边界元素,如
dp[i][k], k == i
- 直接设置
- 思路:
“671. Second Minimum Node In a Binary Tree”
- 解法:Tree + DFS
- 思路:
- 本题单纯就是利用二叉树 dfs 的遍历方法,寻找稍大于根结点的值
- 在遍历时,可以利用父结点小于子节点的特性,提前结束当前子树的遍历
- 思路:
“673. Number of Longest Increasing Subsequence”
- 解法:DP + BinarySearch
- 思路:
- 本题基于 “300. Longest Increasing Subsequence” BinarySearch Golang 的思路
- 对 dp 数组新增一个维度,
dp[i]的末位保存以 i 为连续序列长度的子序列、以当前元素为末尾的元素值,这样就记录了历史记录 cnt[i][j]记录dp[i][j]对应的上升子序列的个数,cnt[i][j]的值由所有满足dp[i-1][k] < d[i][j]的cnt[i-1][k]累加得到- 查找 i 、查找 k 都可以用二分查找法
- 为了方便进行
cnt[i]的累加和运算,用 prefixSum 的形式存储,cnt[i][0] == 0
- 思路:
“673. Number of Longest Increasing Subsequence” BinarySearch
“677. Map Sum Pairs”
- 解法:TrieTree
“678. Valid Parenthesis String”
- 解法 1:Stack
- 思路
- 基本思路是利用括号特性:只要中间可以配对,对两边就没有影响。可以利用栈实现这种逻辑
- 同时维护两个栈,leftStack starStack,在向右遍历过程中分别累加
- 遇到右括号,优先抵消左括号;然后再抵消星号
- 最后要用
*当作右括号尝试抵消所有左括号。由于存在这种非法情况:*((),所以要保存下标, 确保*一定在左括号右边才能抵消
- 思路
“678. Valid Parenthesis String” Stack
- 解法 2: Greedy
- 思路:
- 可以记录 leftCount,遇到
(则增加;遇到)则减一;遇到*则有三种可能性,所以考虑用一个范围来表示 leftCount - 用 minCount maxCount 记录
(的可能数量;注意 minCount 最小也不能低于 0 - 遇到
)后,如果maxCount < 0,则返回 false - 最后返回
minCount == 0
- 可以记录 leftCount,遇到
- 思路:
“678. Valid Parenthesis String” Greedy
“688. Knight Probability in Chessboard”
- 解法:dp
与之前的”935. Knight Dialer”原理相同,但是增加了两点复杂度:
- 可落子的区域变大,可能性更多,需要用两个大的棋盘来演化,并且统计数值会非常大。
- 答案要求计算概率而不是统计数值,由于统计数值过大,中间计算过程就会溢出(超出 double 型), 所以棋盘要存储每一位置的概率(double),并且每次引用上一次演化结果时要”/8.0”(上一次位置到当前位置有 8 种可能结果)而不是累计到最后”/pow(8.0, K)”。
“718. Maximum Length of Repeated Subarray”
-
解法 1:dp
- 思路:
- 类似”edit distance”,进行二维 DP
- 时间复杂度:
O(M*N)
- 思路:
-
解法 2:RollingHash + BinarySearch
- 思路:
- 由于重复子序列有递增特性,即如果有 3 个元素相同则必然有 2 个元素相同,所以可以利用二分查找猜子序列长度
- 可以利用 RollingHash 生成子序列指纹
- 时间复杂度:
O((N+M)*min(N,M))
- 思路:
“719. Find K-th Smallest Pair Distance”
- 解法:Sort + BinarySearch + TwoPointers
- 思路:
- 如果用堆的方法遍历两两元素生成距离,会超时,因为规模是
10000 - 题目要求”第 k 个最小距离”,可以思考在区间
[x,y]内的最大距离是y-x,可以反向推导最小距离逻辑, 如果所有更小距离的总数为k-1,那么就找到了目标。由于这个距离的范围非常大,所以需要用二分查找寻找 - 先对数组排序,以便用双指针法检索所有可能范围
- 如果用堆的方法遍历两两元素生成距离,会超时,因为规模是
- 思路:
“719. Find K-th Smallest Pair Distance” TwoPointers
“725. Split Linked List in Parts”
- 解法:LinkedList
- 思路:
- 遍历一遍求出总结点数。可以计算出分段内数量和余数
- 然后遍历构建每个分段,每段可以消耗余数
- 注意 head 指针不再返回,因此可以作为算法后段变量使用
- 思路:
“727. Minimum Window Subsequence”
- 解法:
- 思路:预处理 + DP
- 如果知道了 s1 的每个下标后面第一次出现某字母的下标值,则可以快速跳转查询是否有符合条件的序列, 所以先创建上述序列
- 遍历 s1 ,如果
s1[i] == s2[0],则开启一系列匹配,如果能够找到整个 s2 序列,则记录匹配长度和起始下标
- 时间复杂度:
O(nm)
- 思路:预处理 + DP
“727. Minimum Window Subsequence” DynamicPlanning
“739. Daily Temperatures”
- 解法:单调栈
“740. Delete and Earn”
- 解法:DP + Bucket
- 思路:
- 根据条件,每个元素值取后,附近的就没法取,这个和”198. House Robber”逻辑类似,可以 DP 解决
- 由于元素范围在
1 <= nunms[i] <= 1e4,可以用 Bucket 做统计,然后再 DP
- 思路:
“740. Delete and Earn” Bucket DP Golang
“740. Delete and Earn” BreadthFirstSearch BFS
- 解法:
A*- 思路:
- 利用到目标点曼哈顿距离作为额外附加距离
- 思路:
“740. Delete and Earn” BreadthFirstSearch A*
“752. Open the Lock”
- 解法:BFS
“765. Couples Holding Hands”
- 考点:
- DSU、Chart、公式推导
- 假设座位下标从 0 记,1、2 两个位置是不能拉手的,这样将导致首尾两个位置不可能拉手,最后只能所有人移动,不可行。 所以每两个座位被分为一组,所有组之间是独立的关系,可以将座位数组看作一个图,图的元素就是一组关联的座位
- 尝试 1、2、3 组情侣乱坐的情况,可以分析得出
最小移动次数=乱坐情侣组数-1,比如有 3 组乱坐需要移动 2 次。 (乱坐的组可以形成一个有序的链式关系)
- 思路:
- 遍历每组座位,通过
x/2判断是否属于情侣,如果不是则认为乱坐 - 用 DSU 把乱坐的人关联起来,最终形成多个乱坐的集合
- 遍历每个乱坐集合的总数,并统计最终移动的最小次数
- 进一步,可以简化最终结果为
总组数-集合数(包括乱坐和没乱坐的)
- 遍历每组座位,通过
“773. Sliding Puzzle”
-
解法:BFS
-
改进解法:
A*
“781. Rabbits in Forest”
- 解法:HashTable
- 思路:
- 利用 HashMap 记录
map[单色兔子总数]已知兔子数量 - 每个兔子报数
对应的该颜色兔子数量 = 报数数 + 1 - 如果相同数量可以凑整,则
总数 += 完成凑整的兔子数量 - 最后统计所有未能凑整的兔子对应的数量和
- 利用 HashMap 记录
- 思路:
“787. Cheapest Flights Within K Stops”
- 解法:Bellmen-Ford
- 思路:
- 可以利用 Dijkstra 实现,但是复杂度过高
- 用 Bellmen-Ford 正好可以利用输入的边和 K 个中转站的特性,代码简单
- 思路:
“787. Cheapest Flights Within K Stops” Graph
“789. Escape The Ghosts”
- 解法:曼哈顿距离
- 思路:
- 整个平面没有任何阻挡,所以”两点之间距离最短”,只需要求出”线段长度”就可以了。 如果 ghost 的距离比自己近,则 ghost 可以先跑到终点去等着,所以问题转化为判断”是否有 ghost 比自己的距离更近”
- 根据题目,这里的距离是曼哈顿距离
- 思路:
“797. All Paths From Source to Target”
- 解法:Backtraking
- 思路:
- DAG(Directed)
- 思路:
“802. Find Eventual Safe States”
- 解法:backtracking + memory
- 思路:
- 利用题目的图特性,深度优先遍历结点,如果所有子节点都是安全的,那么前节点也是安全的
- 一旦遍历中发现了循环,就说明一连串前结点都是非安全的,用 visited 回溯可以标识是否循环
- 由于规模较大
10^4,所以需要用 memory 记录每个结点是否有过结果,避免重复搜索 - 生成的结果要按递增排序,而且结果的元素唯一(结点下标),可以用 count 排序,降低时间复杂度
- 为了保证所有结点覆盖到,最外层循环要将每个结点作为起始结点检索一次
- 思路:
“810. Chalkboard XOR Game”
- 解法:XOR + 博弈论
- 规则:
- Alice 先选
- 轮到任何一名玩家选时,黑板上剩下当前所有数的异或值为 0 时,该玩家获胜
- 没有任何数字时,当前数组的异或值为 0
- 思路:长度为偶数非常重要
- 假设此时偶数数组所有数的异或值为 0,那么 Alice 就直接获胜
- 如果此时偶数数组所有数的异或值不为 0。得到结论:
至少有 2 个以上的数使其数组的异或值不为 0(记作 aa, bb)。
Alice 会选这两个数中的一个,假设他选了 aa。此时 Bob 有两种方式:
- 选剩下的 bb, 那么此时数组长度又回到了偶数。 情况一:此时数组异或值为 0,那么 Alice 获胜。 情况二:数组异或值不为 0,那么又回到了步骤 2,这一步可以一直到数组的数被选完,然后轮到 Alice 选,空数组 Alice 获胜(规则三)。
- 如果 bob 不选 bb,那么轮到 Alice 选时,他也跳过 b,因为 bb 有可能是此时唯一的数选完后数组的异或值为 0。
- 我们知道偶数先选方是一定获胜的! 那么对于 Bob 也是同理,如果 Alice 是奇数方,然后选去一个数字后数组变为偶数,那么 Bob 此时一定会获胜。 那么此时 Alice 只有一种情况会赢,那就是在他第一次选的时候,黑板上所有数的异或值就已经为 0 了(规则二)。
- 规则:
“810. Chalkboard XOR Game” Math
“818. Race Car”
-
考点:复杂问题建模
- 已知:可以用 A 加速、R 减速到 0 并反转方向、target 是最终目标位置、求最少指令数
- 令$A^k$表示连续 k 个 A,则在同方向走$2^k-1$步可表示为 \(A^{k_0}RA^{k_1}...A{k_n}R\) 这个表达式意思是经过一系列前进、后退动作最终到达了目标位置。 最后面的 R 可以去掉(已经到达目的地,转向没有意义),步数和方向可以用表达式表示为: \((2^{k_0}-1)+(2^{k_2}-1)+...-(2^{k_1}-1)-...\) 可以看出偶数次转向是向前的,奇数次转向是向后的
- 设 K (大写)为 terget 的二进制最高位数,那么有 \(target \leq 2^{K}-1\) 这个表达式的物理意义是,如果已经超过了 target,那么就该停下向后开,否则冲出去太长的距离再往回折返肯定是不划算的
-
解法 1: Dijkstra
- 思路:
- 设位置为 i,每个位置可以最多加速${k_j}$次。根据上面分析可得${k_j} \leq K$, 从 i 点可以向后加速${k_j}$次然后调头,每个加速和调头都会增加一次指令步数
- 逐步将范围内所有位置的最小步数演化出来,最后返回结果,每个点可以走向 K+1 个点
- 注意在没有 R(调头)时,到达此次演算目标的剩余距离为$i-(2^{k}-1)$,而调头后距离变为$(2^{k}-1)-i$表示反向走。
- 由于最终结果的位置可能会被到达多次,而最后才直到最小距离,所以本 Dijkstra 算法会计算所有范围内的点。 终止条件靠$[-(2^{k}-1), (2^{k}-1)]$范围控制
- 时间复杂度:O(TlogT),其中 T 是边界距离范围
- 空间复杂度:O(T)
- 优点:逻辑相对简单
- 缺点:由于本题利用 map 作为存储,内存占用较多
- 思路:
“818. Race Car” Dijkstra Golang
-
解法 2: BFS + memory
- 把”位置+速度”作为一个基本单元,放在 queue 里进行 BFS,每次遍历尝试继续加速或减速
- 由于规模较大”10000”,所以要进行 memory 剪枝,以”位置+速度”作为 key 保存在 map 中
- 由于规模在
1~10000之内,同时速度是”2^n”,可以用一个 32 位表示一个 key”位置+速度+速度方向”, 但是追求极致节省内存没必要,可以用一个结构体或 string 表示一个 key
- 由于规模在
- 另外还要限制 BFS 范围:当
范围 > 2*target时,就不再添加元素- 到达最终位置的路径可以是一个”蛇形”过程,超出太远就没有意义了
-
解法 3: DP
- 思路:
- 令 dp[t]表示走到 t 位置用的最小步数,要走到一个 t 有三种情况:
-
- 如果$t=2^{k}-1$,则刚好走 k 步
-
- 永远不超过 t,向右走到某个位置,然后向左走 j 步,再向右走到头($2^{k-1}-1$处)。
行走路径为$XRA^{j}RA^{k-1}R$,其中 X 表示到某位置的路径,由 dp 的演化顺序保证,最后的 R 表示停下来。
花费步数为
\(dp[t-2^{k-1}+2^{j}]+(k-1)+(j-1)+3\)
上面
+3表示一共三个 R
- 永远不超过 t,向右走到某个位置,然后向左走 j 步,再向右走到头($2^{k-1}-1$处)。
行走路径为$XRA^{j}RA^{k-1}R$,其中 X 表示到某位置的路径,由 dp 的演化顺序保证,最后的 R 表示停下来。
花费步数为
\(dp[t-2^{k-1}+2^{j}]+(k-1)+(j-1)+3\)
上面
-
- 超过 t 然后往回走,$A^{k}RX$,走到$2^{k}-1$后往回走的距离为$(2^{k}-1)-t$,步数为 \(dp[(2^{k}-1)-t]+k+1\)
- 上面 2、3 的 dp 值都可以取历史最小值
- 时间复杂度:O(TlogT),对于每一个位置 x 要循环 O(logx)次
- 空间复杂度:O(T)
- 优点:内存使用效率高,性能较高
- 缺点:逻辑较复杂
- 思路:
“847. Shortest Path Visiting All Nodes”
- 解法:BFS + 状态压缩
- 思路:
- 由于结点之间的距离都是 1,没有好的优化方案,只能用基本的 BFS 遍历
- queue 中每个结点为一个元组
tuple == {下标,状态,距离} - 由于元素数量有限(
<=12),可以利用二进制压缩状态,用 int 的 12 bit 表示
- 思路:
“847. Shortest Path Visiting All Nodes” BreadthFirsSearch
“863. All Nodes Distance K in Binary Tree”
-
解法 1: HashMap(空间复杂度 O(n))
- 思路:
- 题目给定了 target 指针,只要找到 target 后就能向下递归查找元素, 难点是没有 parent 指针,所以需要用 HashMap 帮助保存
- 由于每个结点 val 不同,可以用 val 作为 key,指针作为 value,遍历一遍保存到 HashMap
- 然后再从 target 出发,分别向 left、right、parent、brother 四个方向 dfs
- 思路:
-
解法 2: 二叉树递归遍历+状态区分
- 思路:
- 上面的算法需要额外空间,其实通过状态区分,可以尽量少的遍历
- 通过每次调用或返回的状态(找到/未找到 target),可以区分逻辑
- 思路:
“863. All Nodes Distance K in Binary Tree” Tree
“879. Profitable Schemes”
- 解法:零一背包 + 三维 DP
- 思路:
- 本题可以看作是零一背包:人数是背包容量、工作分组是物品体积、分组盈利是物品重量
- 零一背包可以用二维 DP 解决,这里需要考虑第三维:是否达到了 minProfit,如果达到了才累计到结果
- 所以用三维 DP 解决,三个维度分别是:i 分组选择(物品)、j 人数(容量状态)、k 需满足最底盈利,值表示可达到的计划数
- 关键状态转移方程
dp[i+1][j][k] = (dp[i][j][k] + dp[i][j-num][max(0, k-profit[i])]) % MOD- 如果新增人员可以满足新的组需要的人数,则在之前的基础上新增盈利,计算盈利时要先减掉本组所需人数
- 如果新增人员无法满足新组要求人数,则继续保持之前的结果
dp[i+1][j][k] = dp[i][j][k]
- 要点:
- 最后返回值时要对每个人员情况下的结果累加
- 在处理过程中要做 MOD 处理
- 改进:
- 可以看到三维中
i这个维度只会用到上一层,并且也只可能直接复制。所以可以去掉这个维度 - 由于去掉了上面维度,要给每个第二维开头加个 1
- 为了避免人数 j 和最底盈利 k 的后效性,要逆序遍历
- 可以看到三维中
- 思路:
“879. Profitable Schemes” DynamicPlanning
“887. Super Egg Drop”
- 解法:BinarySearch + DP + DFS + Memo
- 思路:
- 基本思路是用前面的鸡蛋确定大概范围、最后一个鸡蛋确定具体层数。
比如有两个鸡蛋 100 层,即
k==2, n==100,需要第一个鸡蛋尝试 10、20、30…,然后第二个鸡蛋再试 10 次 -
- 基本思路是用前面的鸡蛋确定大概范围、最后一个鸡蛋确定具体层数。
比如有两个鸡蛋 100 层,即
- 思路:
“909. Snakes and Ladders”
- 解法:BFS
- 思路:
- 每步可以有 6 个位置选择,按规则跳转
- 要点:
- 由于棋盘的蛇形排列,遍历下一位置需要特殊逻辑处理,可以先简化为最简单的行、列取值,
然后再根据规则进一步计算,这样逻辑复杂度会低很多,如下:
getCoordVal := func(pos int) (int) { x := (pos-1)/n y := (pos-1)%n if x&1 > 0 { y = n-1-y } x = n-1-x return board[x][y] }
- 由于棋盘的蛇形排列,遍历下一位置需要特殊逻辑处理,可以先简化为最简单的行、列取值,
然后再根据规则进一步计算,这样逻辑复杂度会低很多,如下:
- 注意:
- 由于本题存在”回退”的路径,所以无法使用
A*算法,否则第一个找到的最小步数未必是答案
- 由于本题存在”回退”的路径,所以无法使用
- 思路:
“912. Sort an Array”
- 快排、归并、堆排序都能在 nlogn 时间复杂度内完成,但是快排空间复杂度为 O(1)
- 快排思路:(partition)
- 将待排数组分为两部分,设定一个中值,要求遍历过程中左边小于中值、右边大于中值
- 设定两个指针,通过交替遍历向中心靠拢,使左右符合要求
- 递归左边、右边,最终达到整体有序
- pivot 取值改进思路:
- 三数取中法(效果最好)
- 随机取值法
“912. Sort an Array” Sort QuickSort C++
“912. Sort an Array” Sort QuickSort Golang
“913. Cat and Mouse”
- 解法:Minimax
“913. Cat and Mouse” Minimax C++
“918. Maximum Sum Circular Subarray”
- 解法 1:
- 思路:
下面这种解法时间和空间性能都较差,但是易于理解,以后再考虑学习性能较好的解法。
- 把循环数组想象两个重复的数组拼接在一起,按照单个数组的解法,计算一个
2*N+1长度的前 N 项和数组。 - 利用一个 deque 存储可用于被减的前面的下标,初值插入 0。
- 从 1~2N 开始遍历,首先去除间隔距离过远的下标,然后计算当前值与 dq 最前面的下标对应的值相减结果。
- 将当前下标插入后边前,先将队尾所有值小于当前的弹出。
- 总体思路是保持 deque 中有合适的比较值的下标,要么下标合适、要么值要够小(被后边减时结果会更大)。
- 把循环数组想象两个重复的数组拼接在一起,按照单个数组的解法,计算一个
- 思路:
下面这种解法时间和空间性能都较差,但是易于理解,以后再考虑学习性能较好的解法。
- 解法 2:Kadane
- 思路:
- 错误思路:按照两个拼接数组进行 Kadane,则
[5,-3,5]这种会被错误计算5+(-3)+5 = 7 < 5+5 = 10 - 假设字符串由三段组成:
A+B+C。那么答案可能是一段:A/B/C,也可能是前后两段组成C+A。 - 对于一段的情况,直接用 Kadane 就可以
- 对于两段的情况,有如下公式:
C+A = (A+B+C) - B = Sum - B,其中-B表示每个元素取-后求得的 Kadane 结果。 还有一种情况,就是 A、C 完全为空,这时-B == -Sum与题目不符,所以要尝试去掉”第一个”或”最后一个”元素
- 错误思路:按照两个拼接数组进行 Kadane,则
- 思路:
“918. Maximum Sum Circular Subarray” Array
“930. Binary Subarrays With Sum”
- 解法:PrefixSum + HashMap
- 思路:
- 通过 PrefixSum 可以实现对任意字串的和的计算
- 然后利用”Tow sum”的方法滚动计算符合条件的字串
- 由于 0 不会影响 sum 结果,所以需要重复统计,需要用 HashMap 对重复 presum 元素进行累加
- 思路:
“930. Binary Subarrays With Sum” HashTable
“935. Knight Dialer”
- 解法: 此题看似有数学规律,实际只能靠基本演化逻辑,通过动态规划推导出最后结果。 每次演化都要从之前的某个位置过来,所以只需要两组位置计数不断演化即可。
“974. Subarray Sums Divisible by K”
- 考点:
- 连续整数组成的子序列,可以利用 sum(i,j)来快速表达
- Math: 同余定理,
(a-b)%m == 0 <=> a%m == b%m == k,如果两数之差可以被 m 整除,那么两数分别对 m 取余的值相同 - 利用 HashTable 对已存在元素累加
- 思路:
- 设 P[i] 是前面 i 个数累加和,
sum(i,j) == P[j]-P[i-1] - 根据同余定理
sum(i,j)%K == 0 <=> P[j]%K == P[i-1]%K
- 设 P[i] 是前面 i 个数累加和,
“974. Subarray Sums Divisible by K” HashTable Golang
“981. Time Based Key-Value Store”
- 解法:HashMap + BinarySearch
“983. Minimum Cost For Tickets”
- 解法: dfs+memo
- 思路:
- 某天买短期还是长期车票,取决于后面是否要用这张车票,而后面的结果会被重复用到。 所以题目可以理解为从后向前(先计算 day 数大的)的 DP
- 可以用 memo dfs 方式降低代码复杂度
- 转移公式:
cost := min(dfs(day+1)+costs[0], dfs(day+7)+costs[1], dfs(day+30)+costs[2])
- 优化:
- 如果当前日期不存在,则无需买票,按
dfs(day+1)继续计算
- 如果当前日期不存在,则无需买票,按
- 思路:
“983. Minimum Cost For Tickets” DynamicPlanning dfs+memo
- 解法:DP
- 思路:
- 依据上面的算法,改成 DP 就可以了
- dp 数组需要的容量比上面的 memo 大 30,以简化计算
- 可以利用下标逻辑跳过无效 day
- 思路:
“983. Minimum Cost For Tickets” DynamicPlanning dp
“986. Interval List Intersections”
- 解法 1: LineSweep
- 思路:
- 影响区域重叠的只有 interval start end 两个位置点
- 可以将位置点拆分、排序,然后顺序遍历统计当前存在的线段数,如果 >1 则记录
- 注意排序时先处理相同坐标点的 end,这样能统计到更大的数
- 思路:
“986. Interval List Intersections” LineSweep Golang version1
- 解法 2: LineSweep + SlidingWindow
- 思路:
- 由于原始数据保证顺序、本数组不重叠,可以利用这个特性直接扫描
- 利用 max(start) 和 min(end) 函数尽量找到当前重叠区域
- 保持当前区域为可能产生交集的 Window,逐步移动两个数组的下标
- 思路:
“986. Interval List Intersections” LineSweep Golang version2
“987. Vertical Order Traversal of a Binary Tree”
- 解法:Tree + Sort
- 思路:
- 首先想到左右两边的列分别记录,单同一行、同一列可能有多个元素,所以需要三维数组比较麻烦
- 根据题目要求,二叉树的”前/中/后序”遍历都无法满足,所以必须考虑额外存储、排序
- 可以直接将所有元素的 row、col、val 保存在新数组中,然后按 col、row、val 排序
- 输出时相同 col 的合并输出
- 特点:
- 虽然时间复杂度稍微增高
O(n*系数)->O(n*logn),但逻辑复杂度大大降低
- 虽然时间复杂度稍微增高
- 思路:
“987. Vertical Order Traversal of a Binary Tree” Tree
“993. Cousins in Binary Tree”
- 解法:
- 思路:DFS
- 利用二叉树的特征,在查找过程中限定各种边界条件来减少无用搜索
- 每次起始递归函数前都要初始化全局变量
- 如果已经找到了目标层,则不再向更深遍历
- 确保同层并且父结点不同
- 思路:DFS
“993. Cousins in Binary Tree” Tree Golang
“1004. Max Consecutive Ones III”
- 思路:
关键字
contiguous,所以考虑用 sliding window
“1006. Clumsy Factorial”
- 思路: 利用 stack 进行无括号的四则运算,乘除直接计算、加减入栈,最后累加栈中所有元素
“1011. Capacity To Ship Packages Within D Days”
- 解法:BinarySearch
- 思路:
- 初看题目,以为是背包问题。但是题目要求货物按顺序放置,所以无法背包。
- 题目可以转化为二分查找,在范围内尝试船的容量
- 二分查找的最小值是最大物品重量、最大值是全部物品重量和
- 要点:
- Go 可以利用
sort.Search(int, func(int) bool)实现 LowerBound 二分查找 - 注意货物不能切割,所以如果当前放不下就要放到第二天
- Go 可以利用
- 思路:
“1011. Capacity To Ship Packages Within D Days” BinarySearch Golang
“1035. Uncrossed Lines”
- 解法:DP
- 思路:
- 经过逻辑推导,可以发现逻辑和”1143. Longest Common Subsequence”一样,求出最长公共子序列
- 思路:
“1036. Escape a Large Maze”
- 考点:bfs 稀疏矩阵 极限思想 几何
- 题干分析:
- 坐标最大值
10^6,说明矩阵范围巨大 blocked.length <= 200,说明有效数据只占一小部分,是一个稀疏矩阵,不能用传统矩阵方法标记
- 坐标最大值
- 思路:
- 矩阵太大,无法用二维数组标记,应该用 set 记录已访问位置
- 即使用 set 记录,空间复杂度也太大。可以利用几何特性缩小 bfs 范围,200 个 block 挡住的最大闭合范围也就是一个三角形,其中两条边是边界,block 充当封住边界的边。这样可以估算出数量为 20006(勾股定理、根号 2),因为 block 本身也占 200 容量,所以实际范围内单元数
<20000,只要遍历元素超过 20000,说明 visited 范围一定会延伸到 block 外 - “封口”可能发生在任何一方,需要同时检测出发点和目标点的 bfs 范围都
>20000时,才能判定为 true
“1036. Escape a Large Maze” bfs Golang
“1039. Minimum Score Triangulation of Polygon”
- 解法:DFS+Memo
- 思路:用区间 DP DFS+Memo 模板解决
“1044. Longest Duplicate Substring”
- 解法:RollingHash + BinarySearch
- 思路:
- 由于计算规模较大
3*(10^4),所以无法用O(n^3)的三重循环暴力匹配 - 假定字串长度为 K,则题目转化为”是否有长度为 K 的重复字串”
- 利用 RollingHash 可以快速进行字符串字串匹配
- 假设某个 K 符合要求,那么根据字串字串的特点 K-1 也必然符合要求,可以利用 BinarySearch 查找这个边界长度 K
- 用完整比较的方法解决 Collision
- 由于计算规模较大
- 时间复杂度:
O(nlogn)
- 思路:
“1044. Longest Duplicate Substring” SlidingWindow RollingHash
“1049. Last Stone Weight II”
- 解法:0-1 背包 + 题目分析
- 思路:
- 题目参照”416. Partition Equal Subset Sum”,进行破题
- 只要有两块石头,那么两两就可以抵消,最终一定能剩下一块石头。 在抵消过程中,我们希望尽量能抵消更多重量。可以想象将石头分为两堆,这两堆之间相互抵消,最后留下一块,正好是两堆重量差。 所以这道题可以转化为 0-1 背包:如何找到一堆石头,总重量尽量接近全部重量的一半,这样最终抵消后剩下的最少。
- 要点:
- 本题的目标是找”最值”而不是”恰好放下”,所以应使用不一定能填满的 DP 模板
- 思路:
“1049. Last Stone Weight II” DynamicPlanning Golang
“1054. Distant Barcodes”
- 思路:
- 尽量让相同元素相互隔开
- 数量越多的元素越优先考虑,因为它们更”容易”在一起
- 解法 1:
- 用 Map 统计元素数量
- 将元素按出现频次放入最大堆
- 准备一个结果数组
- for 循环堆中元素,循环每个位置防止
- 先放奇数位,放满后放偶数位(下标移到 1)
- 解法 2:
解法 1 中用到了 Heap,如果不方便使用,可以对统计结果再排序一次,然后按照从大到小处理一遍即可
- 如果 Heap 元素只在最后 pop 一次,那 Heap 完全可以用数组替代,做一次排序即可
- 技巧点:
- 由于保证存在答案,只需要让元素自己隔离就可以,不用考虑其他元素
- 在奇偶转换时,输出数组的前后位置也会自动隔离元素,所以不用担心出问题
“1063. Number of Valid Subarrays”
- 解法:单调栈
- 思路:
- 转化思维方式:从某个元素开始向右遍历,当右边遇到小于起始元素的值开始统计起始元素覆盖的子数组数量
- 采用单调栈保存下标正好可以实现上述逻辑
- 每次元素从栈顶出栈时进行统计
- 要在最右侧增加下标
-1,以便最后所有元素都有机会出栈
- 思路:
“1063. Number of Valid Subarrays” Stack
“1073. Adding Two Negabinary Numbers”
- 解法:Math
- 思路:
- “以-2 为进制”表示向上进位 1 时,相当于高位
*(-2) - 先手写一下,自然数 1 2 3 4 的表示方式,对”-2”进制有一定理解
- 然后推断低位到高位的累加模式,
sum = carray + arr[i] + arr[j],根据 sum 的不同情况(0/1/2/3)设置当前下一进位 - 利用累加模式遍历计算结果,生成时是正序的,答案要反转的,注意反转前要删除无用”前导 0”
- “以-2 为进制”表示向上进位 1 时,相当于高位
- 思路:
“1073. Adding Two Negabinary Numbers” Math
“1074. Number of Submatrices That Sum to Target”
- 解法:二维 preSum + hash + matrix 遍历
- 思路:
- 这道题的基本思路先要会:”560. Subarray Sum Equals K”
- 在 matrix 中对每列进行 preSum 压缩成一维,然后用上面现成函数
- 注意对 matrix 的遍历至少要选取两行,所以时间复杂度是
O((m^2)*n)
- 思路:
“1104. Path In Zigzag Labelled Binary Tree”
- 解法:二进制表示完全二叉树 + 逻辑
- 思路:
- 本题正好符合完全二叉树特征,所以每层元素数量正好是
2^n - 每个元素找到父元素位置很容易,
/2就可以,难点在于 zigzag 情况下特定行需要反转取值
- 本题正好符合完全二叉树特征,所以每层元素数量正好是
- 步骤:
- 先找到 label 对应的行数
- 根据行数可以确定本行起始元素和下一行起始元素
- 根据行数奇偶判断 label 是否需要反转处理
- 然后通过
/2处理,逐步取得父结点输出
- 要点:
- 不要一上来尝试用简单算法实现,事实证明最后只能分步骤逐步实现功能,代码量无法精简
- 思路:
“1109. Corporate Flight Bookings”
- 解法:LineSweep + prefix sum + diff
- 思路:
- 直观的想法是遍历 bookings 把结果累加统计到结果数组。但规模较大时这种时间复杂度是
O(m*n) - 可以利用 LineSweep 思想,结合 prefix sum 思想,创建一个数组为 prefix sum 前的数组,即 diff 差分数组。 遍历 bookings 数据影响起始结束点
- 最终生成 prefix sum 为结果并返回
- 直观的想法是遍历 bookings 把结果累加统计到结果数组。但规模较大时这种时间复杂度是
- 时间复杂度:
O(m+n)
- 思路:
“1109. Corporate Flight Bookings” Array
“1140. Stone Game II”
- 解法:Minimax
- 思路:
- 利用 dfs+memo 模板实现
- 利用 postfixSum 可以实现快速计算区间值
- 由于模板计算过程使用差值,最后结果需要解二元一次方程
- 由于本题是求尽量大的值,中间值可能为负,所以初始值要为
math.MinInt32
- 思路:
“1143. Longest Common Subsequence”
- 解法:DP
- 这是一个二维 DP,类似”edit distance”,分别以两个字符串长度作为 dp 方向
- 设
dp[i][j]表示text1[0..i]和text2[0..j]的最长公共子序列 - 边界条件:
i/j == 0时,由于一方没有字符串,所以最长公共子序列长度必然为 0 - 当
text1[i] == text2[j]时,dp[i][j] = dp[i-1][j-1] + 1,表示存在相同字符,长度增 1 - 当
text1[i] != text2[j]时,dp[i][j] = max(dp[i-1][j], dp[i][j-1]),表示延续历史最大长度
“1143. Longest Common Subsequence” DP Golang
“1192. Critical Connections in a Network”
- 解法:Tarjan
- 思路:
- 基于基本的 Tarjan 算法
- 利用回溯时,
LOW_next < DFN_i的特性,确认环内点;LOW_next == DFN_i为环起始点;LOW_next > DFN_i为环起始点前面的点 - 然后记录入环点和入环前的点组成的边
- 注意:
- 本题是双向联通图,所以从任意一点开始 dfs 都可以得到全部结果
- 思路:
“1192. Critical Connections in a Network” Graph
“1128. Number of Equivalent Domino Pairs”
- 思路:
- 只需要对”相同”的元素累加统计即可
- 由于每个分量值
<9,可以用一个排过序的两位数表示 - 可以利用一个 100 个元素的 bucket 统计,这样就无需排序一次遍历就统计出来
“1229. Meeting Scheduler”
- 解法:BF
- 思路:
- 这道题需要用到自动有序数据结构,并且最好容易得到前后元素,C++的 set(红黑树)就满足条件
- 每次向前、后中较近的 interval 合并
- 思路:
“1178. Number of Valid Words for Each Puzzle”
- 考点:
- 本题重点是元素数量巨大:
1 <= words.length <= 10^5、1 <= puzzles.length <= 10^4, 所以无法对所有 word 和 puzzle 两两比较,需要多处优化 - 分治,分两个阶段操作得到结果
- 二进制压缩保存特征值
- 极端数量下根据特征合并同类项,降低整体时间复杂度
- bitcount 算法
- bitSubset 算法
- 本题重点是元素数量巨大:
- 思路:
- 首先对 word 遍历,提取特征值为 bitmap,如果 bitcount 符合要求则累加到 map 中
- 由于数量太大,而 puzzle 元素数较小(<=7),所以直接对 puzzle 的二进制子集进行遍历
“1178. Number of Valid Words for Each Puzzle” BinaryOperation Golang
“1208. Get Equal Substrings Within Budget”
- 解法:SlidingWindow
- 思路:
- 题目要求 s t 两个字符串等长,只要其中一段(下标对应)的连续子串符合条件即可,用 SlidingWindow 统计最长有效子串长度
- 注意:
- 由于
type byte uint8,所以byte类型做减法时可能无法取得负数,无法利用abs函数,需要写专用的diff函数取得正数差值
- 由于
- 思路:
“1239. Maximum Length of a Concatenated String with Unique Characters”
- 解法:Backtracking + bit
- 思路:
- 每个可选字符串字母数量不超过 26,考虑用二进制
- 先考虑用零一背包实现,由于是位的组合,需要用二维零一背包, 但是考虑样本空间太大,占用超量存储,所以考虑用 map
- 由于总规模较小,直接用 Backtracking 解决
- 思路:
“1239. Maximum Length of a Concatenated String with Unique Characters” Backtracking
“1262. Greatest Sum Divisible by Three”
- 解法:DP + Math
- 思路:
- 类似”198. House Robber”,每次可以累加也可以不累加,多种状态同时记录用于后面的 DP
- 对某个元素累加后,对 3 取余,一定是 0 1 2 三种状态中的 1 种,而这种状态未来还可能起作用,所以要记录下来
- 对每种取余状态,只记录最大的和值
- 注意:
- 在更新时,由于初始过程可能存在三个状态相互影响,比如
6%3 == 9%3, 所以对 dp 不同状态的赋值要分行进行,确保保存了最大值
- 在更新时,由于初始过程可能存在三个状态相互影响,比如
- 思路:
“1262. Greatest Sum Divisible by Three” DynamicPlanning
“1269. Number of Ways to Stay in the Same Place After Some Steps”
- 解法:DP + 规模边界条件
- 思路:
- 按照 DP 演化思路,有两个数组分别表示两步,逐步演化
- 要点:
- 按基本思路写完会超时,原因是
arrLen <= 10^6每步演化的数组过大, 而steps <= 500步数很小,arrLen >= 251之后的不会影响结果了, 所以只要在演化前对arrLen进行一次范围修正即可
- 按基本思路写完会超时,原因是
- 思路:
“1288. Remove Covered Intervals”
- 解法:LineSweep
- 思路:
- 要保证两边都被覆盖的 interval 才删除
- 我们排序时保证按 start 顺序排序,然后按 end 逆序排序
- 之后遍历时候因为按 start 遍历,只要关注 end,一旦 end 被覆盖,说明 start 必然被覆盖
- 思路:
“1288. Remove Covered Intervals” LineSweep Golang
“1310. XOR Queries of a Subarray”
- 解法:preSum + XOR
- 思路:
- 先求出异或的 preSum 数组
- 然后利用 preSum 求出任意范围内的异或结果
- 思路:
“1310. XOR Queries of a Subarray” BinaryOperation
“1316. Distinct Echo Substrings”
- 解法:RollingHash
- 思路:
- 如果用三层 for 循环(下标、长度、子数组元素),时间复杂度为
O(n^3),无法满足题目2000的规模 - 尝试
1~(n/2)长度作为 RollingHash 长度,同时维护两个 hash 值滚动 - 用一个 set 保证不重复;用重新检查的方式避免 hash collision
- 如果用三层 for 循环(下标、长度、子数组元素),时间复杂度为
- 时间复杂度:
O(n^2)
- 思路:
“1316. Distinct Echo Substrings” SlidingWindow RollingHash
“1392. Longest Happy Prefix”
- 解法:RollingHash
- 思路:
- 是否有 HappyPrefix 没有线性演化关系,无法用 BinarySearch
- 从前向后取 hashPre,同时从后向前取 hashAfter
- 思路:
“1392. Longest Happy Prefix” SlidingWindow RollingHash
“1406. Stone Game III”
- 解法:Minimax + postfixSum
- 思路:
- 利用 Minimax 模板计算差值即可
- 注意本题在末端需要取得最后一个元素,所以 postfixSum 的容量要+1
“1438. Longest Continuous Subarray With Absolute Diff Less Than or Equal to Limit”
-
解法 1: 利用 C++ STL 的 multiset 实现。在遍历过程中维护最大、最小值及中间元素。如果是其他语言,如 Golang 需要手写 Treap 结构。
- 时间复杂度 O(nlogn),每次维护 tree 需要 logn,空间复杂度 O(n)
-
解法 2: 滑窗+单调队列
- 思路:
continuous、subarray表示用连续的元素统计结果,考虑用 SlidingWindow。- 在窗口移动过程中要记录 max、min 两个值,用来判断当前元素是否超范围
- 在窗口 left 端移动时,要调整 max、min 值
- 上面保持 max、min 值,同时要保持元素的先后顺序关系,考虑用两个 MonotoneQue 来实现
- 流程:
- for 循环所有下标,作为 right 值,保持 minQue 和 maxQue 最新状态
- 如果当前范围不匹配 limit 则将窗口移动,同时判断是否有元素出队列
- 记录 right - left 最大值,直到循环结束
- 思路:
“1442. Count Triplets That Can Form Two Arrays of Equal XOR”
- 解法:XOR + preSum + HashTable + 推导优化
- 思路:
- 最直观的方法是求出 preSum 数组,然后分别遍历 i j k 三个坐标计算结果,时间复杂度 O(n^3)。 但是这种方法太初级,经过优化可以达到 O(n)时间复杂度:
- 设前 i 项的 preSum 值是 Si,preSum 的数组元素是 arri。根据 XOR 特性有:
Si ^ Sj = arr(i) ^ ... ^ arr(j-1),那么[i,j]异或和为S(i) ^ S(j+1), 题目中左右两段异或和 a b 可以表示为a = S(i) ^ S(j)、b = S(j) ^ S(k+1), 如果a == b则有S(i) ^ S(j) == S(j) ^ S(k+1)根据 XOR 的交换律,得出S(i) == S(k+1), 也就是前后有相同的 preSum 值,则找到了目标 tuple,中间的任何 j 都成立(遍历降低一维)。
- 设当前处理到 k 时,前面有 m 个 i(i1 i2 … im)都满足
S(i) == S(k+1),则这时它们对结果的贡献数量为:(k-i1) + (k-i2) + ... + (k-im) = m*k - (i1+i2+...+im), 所以在遍历过程中我们要记录满足S(i) == S(k+1)的 i 出现次数count和下标 i 之和total, 可以利用 HashTable 记录这两个值
- 思路:
“1442. Count Triplets That Can Form Two Arrays of Equal XOR” BinaryOperation
“1449. Form Largest Integer With Digits That Add up to Target”
- 解法:完全背包 + 字符串(itoa)
- 思路:
- cost 是物品体积、index 是物品值、target 是背包容量
- 两层循环,第一层是背包容量状态、第二层是物品
- 最后将结果生成字符串形式返回
- 思路:
“1463. Cherry Pickup II”
- 考点:
- DP
- 思路:
- 用三维数组 dp[x][y1][y2]表示某行下机器人 1、机器人 2 的位置下已获取的最大分数
- 转移方程:
dp[x][y1][y2] = max(dp[x][y1][y2], dp[x-1][y1-1~y1+1][y2-1~y2+1]) - 注意设置初始行,然后开始迭代。考虑到初始行可能是 0 值,所以 dp 初始值设置为无效值 0
- 最后需遍历找到最后一行中的最大值返回,注意需要对 y1、y2 两个变量进行遍历
- 优化:可以只用两行数据进行迭代
“1482. Minimum Number of Days to Make m Bouquets”
- 解法:BinarySearch
- 思路:
- days 范围较大,但是具有顺序性,即一旦某个 days 满足条件,那>=它的都满足,所以可以利用二分查找
- 在某个 days 下,是否符合条件可以简单遍历统计实现
- 时间复杂度 O(mlogn)
- 思路:
“1510. Stone Game IV”
- 解法:Minimax
- 思路:
- 只要对手能符合条件,则不能必胜,因此需要对手必输的情况下,自己才能必胜
- 按 Minimax 模板即可
- 思路:
“1547. Minimum Cost to Cut a Stick”
- 解法:区间 DP 模板 + 边界逻辑
- 思路:
- 可以直接用区间 DP 解决,但是效率较低。其实可以利用
cuts数组长度较小的特性,只处理有效切割点。 dfs(int l, int r)函数表示[l,r)左闭右开区间结果的计算- 注意 cost 的计算需要根据当前是否为边界、curts 点来计算
- 可以直接用区间 DP 解决,但是效率较低。其实可以利用
- 思路:
“1547. Minimum Cost to Cut a Stick” DynamicPlanning
“1583. Count Unhappy Friends”
- 解法:HashTable
- 思路:
- 设有对(x,y)利用二维 map 记录 x 在 y 之前喜欢的元素,xy 可互换
- 然后遍历一遍,x 优先喜欢的元素,如果刚好该元素也优先喜欢 x,则记录到 set 中
- 最后返回 set 容量
- 思路:
“1584. Min Cost to Connect All Points”
- 解法:MST Kruskal
- 思路:
- 由于本题是一个全联通图,即任意一点可以连到其他点,所以使用 Prim PQ 算法可能超时
- 用 Kruskal 可以勉强通过
- 用 Prim Naive 可以较短时间通过
- 思路:
“1584. Min Cost to Connect All Points” MST Golang
“1646. Get Maximum in Generated Array”
- 解法:模拟
- 思路:
- 开始想要反向推导+DFS,发现中间过程和起始条件是不同的,只能用模拟的方式实现
- 思路:
“1649. Create Sorted Array through Instructions”
- 解法:BIT + bucket
- 思路:
- 利用 BIT 当成 bucket,记录每个元素出现的次数,然后取当前元素前后区间内元素出现次数总和综合统计
- 要点:
- 原本 BIT 的容量是用于存放下标的,本题是存放值,所以范围要+1,再加上模板的+1,最重要+2
- 思路:
“1649. Create Sorted Array through Instructions” BinaryIndexedTree Golang
“1707. Maximum XOR With an Element From Array”
-
解法 1: XOR + TrieTree + DP
- 思路:
- 假设给定了集合 nums 不限制 mi,求 xi 的过程可以看作从左向右查看二进制位匹配的过程, 由于 XOR 运算,最好的结果是两位不同,可以把原始 nums 每个元素放入二进制树的 TrieTree,然后遍历取得最大值
- 上面的 TrieTree 的构建可以类似 DP 从小到大,也就是 nums 排序后逐步构建,这样只要对 queries 的 mi 排序, 就能逐步求得结果,注意要记录 queries 的元素下标以组成答案
- 特殊点:如果没有满足 mi 的 nums 元素,则结果为 -1
- 时间复杂度:
O(NlogN + QlogQ + (N+Q)*L)其中 N 是 nums 规模;Q 是 queries 规模;L 是元素的二进制长度 30 位 - 优化算法:
上面算法较耗时部分是左边两个排序导致的
nlogn,能否不排序? 可以在 TrieTree 构建时,每个结点记录孩子结点的最小值,那么根结点会记录所有结点的最小值。 这样可以直接识别出返回值为-1 的 mi
- 思路:
“1707. Maximum XOR With an Element From Array” TrieTree
“1711. Count Good Meals”
- 解法:HashMap
- 思路:
- 类似”three sum”,遍历时利用 hashTable 结构快速判定是否有历史匹配元素
- 由于不同下标认为是不同元素,所以需要用
map[int]int - 遍历到每个元素,都遍历
1~2^22,这些 2 的幂
- 思路:
“1713. Minimum Operations to Make a Subsequence”
- 解法:LCS -> Rearrange + LIS + LowerBound
- 思路:
- 首先想到本题基于”1143. Longest Common Subsequence”,只需要求出最长公共子序列长度 x,然后结果就是
最小变动 = target - x - 但是本题的规模非常大:
1 <= target.length, arr.length <= 105,这使得 1143 时间复杂度为O(mn)的解法不可取 - 由于本题”target that consists of distinct integers”的特点,可以利用 Rearrange 的方法分别重整 target 和 arr,
记录 target 的元素下标为
[0,1,2,3,...],对应 arr 只取 target 中的元素并只记录下标,形如[1,0,5,4,2,0,3] - 接下来只要用”300. Longest Increasing Subsequence”的 LowerBound 解法就可以了
- LowerBound 可以自己写,也可以利用标准库函数
- 进一步精简,可以忽略中间的存储环节,只利用 Rearange 的 map 即可
- 首先想到本题基于”1143. Longest Common Subsequence”,只需要求出最长公共子序列长度 x,然后结果就是
- 思路:
“1713. Minimum Operations to Make a Subsequence” BinarySearch
“1720. Decode XORed Array”
- 解法:异或特性
- 思路:
- 异或运算具有自反性,
a^b^a == b - 由于我们知道了
first,可以利用其特性求出ret[1] = first^encoded[0] - 再用新求出的值迭代取得所有结果
ret[i+1] = ret[i] ^ encoded[i]
- 异或运算具有自反性,
- 思路:
“1720. Decode XORed Array”BinaryOperation Go
“1723. Find Minimum Time to Finish All Jobs”
- 解法:BinarySearch
- 思路
- 如何分配任务难以直接获取最优解,考虑用 backtracking,但是先要确定每人最大负荷
- 最大负荷有个特点,一旦某个负荷满足,那么更大的一定也满足,所以可以用二分查找
- 二分查找的最小值是最大的单个任务,最大值是全部任务之和
- 确定了某个单人最大负荷 limit 后,需要对每个商品进行 backtracking 处理,尽量把该商品尝试放在靠前的人身上
- 在处理时,优先尝试较大的,所以要先对数组倒序排序
- 如果某个人放某个物品已经放不下,则尝试下一个人
- 有两个提前退出条件:
- 如果当前人刚好以 limit 放满而之后的没有成功,说明一定不会成功,返回 false
- 如果当前人是空的,而之后的人也一定是空的,这时如果失败了,说明后边的人也会失败,所以返回 false
- 思路
“1723. Find Minimum Time to Finish All Jobs” BinarySearch
“1734. Decode XORed Permutation”
- 解法:XOR + 逻辑
- 思路:
- 这道题是基于”1720. Decode XORed Array”的算法,只要求出
first就可以推出结果 - 题目条件数组元素是最前面的 n 个正整数,n 必定是奇数,我们假设为
A B C D E - 设
AB表示A^B,根据异或的结合律,我们可以求出一个”蕴含”了所有元素的值ABCDE - 根据已知的 encoded 数组
AB BC CD DE,我们只要从中取出BC DE然后求得BCDE - 再根据异或的”自反”性
A = ABCDE ^ BCDE,求得first - 然后根据”1720. Decode XORed Array”的算法求得结果即可
- 这道题是基于”1720. Decode XORed Array”的算法,只要求出
- 思路:
“1734. Decode XORed Permutation”BinaryOperation Go
“1736. Latest Time by Replacing Hidden Digits”
- 解法:Greedy
- 思路:
- 按照每个位置的具体情况分类讨论
- 优先设定左边的高位,然后处理后面位置时可以根据前面高位值设置当前值
- 思路:
“1738. Find Kth Largest XOR Coordinate Value”
- 解法:XOR + preSum + nth_element
- 思路:
- XOR 的处理和
+类似,可以适用于 preSum - 利用二维 preSum 可以求得 sum 矩阵
- 然后遍历 sum 矩阵,将元素加入 array,通过排序取出目标值
- XOR 的处理和
- 改进:
- 二维 preSum 可以利用原 matrix 节省空间
- 二维 preSum 可以一次遍历就完成,节省循环次数
- 可以利用 DP 实现 preSum 一次遍历,转移方程:
dp[i][j] = dp[i-1][j]^dp[i][j-1]^dp[i-1][j-1]^matrix[i-1][j-1] - “查找第 K 大元素”可以利用 nth_elemet 实现,时间复杂度 O(n)
- 思路:
“1738. Find Kth Largest XOR Coordinate Value” BinaryOperation
“1743. Restore the Array From Adjacent Pairs”
- 解法:HashMap
- 思路:
- 这道题类似”399. Evaluate Division”,可以用 HashMap 形成关系链,可以用
map[int][]int存储 - 由于最两端元素的关联元素只有 1 个,可以利用这点创建初始结果
- 答案可以不唯一,所以随便选一个开头元素都可以
- 这道题类似”399. Evaluate Division”,可以用 HashMap 形成关系链,可以用
- 注意:
- 可以利用元素总数和最末尾元素只有一个关联的特性进行遍历处理
- 思路:
“1743. Restore the Array From Adjacent Pairs” HashTable
“1818. Minimum Absolute Sum Difference”
- 解法:
- 思路:
- 想要尽量降低总 diff,那么需要尝试所有元素对,找到可能的最大改变量
- 对于每一个 nums2,可以在 nums1 中找到最接近的两个元素进行尝试,如果 nums1 有序,则可以利用二分查找找到这两个最近的 nums1 元素
- 步骤:
- 利用排序将 nums1 排序,可以单独将 nums1 复制达到一个数组中排序,也可以绑定 nums1 nums2 一起排序,这样可以节省容量
- 遍历 nums2 数组,同时利用二分查找计算 nums1 中最接近 nums2 的两个数,结合 nums2 下标对应的 nums1 中的数,计算最大减小量
- 时间复杂度:O(nlogn),空间复杂度:O(1)
- 其他:
- 利用双指针归并排序的思路,可以在步骤 2 中将时间复杂度降为 O(n),但是由于步骤 1 已经达到 O(nlogn),所以没有必要做这个优化
- 思路:
“1833. Maximum Ice Cream Bars”
- 解法:Bucket Sort
- 思路:
- 由于 cost 范围有限(1 ~ 1e5),可以用 bucket 排序后统计结果
- 思路:
“1738. Find Kth Largest XOR Coordinate Value” Sort
“1838. Frequency of the Most Frequent Element”
- 解法:Sort + SlidingWindow
- 思路:
- 先将数组排序,则问题演化为”对连续的阶梯进行填补,能否填平”的问题
- 可以利用 SlidingWindow 保证 Window 内的”楼梯”可以填平
- 要点:
- 注意 r 向右移动时,所有旧有范围都需要填
- 注意 l 向右移动时,只需要去除对应的长度差
- 思路:
“1846. Maximum Element After Decreasing and Rearranging”
- 解法:CountSort + Greedy
- 思路:
- 根据题目描述,可以想象为排序之后进行铺楼梯,并且当前可用砖块只能降低不能升高
- 首先想到可以排序+遍历的方式填补空缺,最终找到最高点
- 由于本题的特点,台阶必须连续,所以最高值不会超过 len(arr),可以利用 Count Sort 进行排序
- 思路:
“1846. Maximum Element After Decreasing and Rearranging” Sort
“1877. Minimize Maximum Pair Sum in Array”
- 解法:CountSort + TwoPointers
- 思路:
- 只要排序后,从左右分别拿元素相加,就能尽量最小化和
- 由于元素范围较小,利用 Count Sort 排序速度更快
- 思路:
“1885. Count Pairs in Two Arrays”
- 解法:公式化简 + BinarySearch
- 思路:
- 题目要求的公式为:
(i < j) && (nums1[i] + nums1[j] > nums2[i] + nums2[j]) - 右边可变形为:
nums1[i] - nums2[i] > nums2[j] - nums1[j] - 可以直接计算新数组:
diff[i] = nums1[i] - nums2[i] - 然后上面的可进一步变形为:
nums1[i] - nums2[i] > nums2[j] - nums1[j] => diff[i] > -diff[j] - 变形为:
diff[i] + diff[j] > 0,至此只要在diff数组中找到一组正负数即可,这时 i j 已经无需顺序,找到任意两个即可 - 将
diff数组排序后,设diff[k]满足k >= j && diff[i] + diff[k],则所有的 k 都满足答案,这时答案数量为n-k - 遍历 i,寻找
j > i && (-diff[j])
- 题目要求的公式为:
- 思路:
“1885. Count Pairs in Two Arrays” BinarySearch
“1893. Check if All the Integers in a Range Are Covered”
- 解法:LineSweep + Bucket
- 思路:
- 利用 LineSweep 原理,将 ranges 拆分成 start end 两个端点
- 由于目标范围较小,可以直接用 bucket 记录拆分后的变动点累加值
- 最后遍历一遍 bucket,如果当前累加结果为 0 说明有未覆盖的位置,返回 false
- 思路:
“剑指 Offer 03. 数组中重复的数字 LCOF”
- 解法:Bucket + In-place + Array
- 思路:
- 理想的元素和下标一一对应,只要尝试遍历并把元素放到合适的位置,一旦出现重复元素就返回
- 思路:
“剑指 Offer 03. 数组中重复的数字 LCOF” Array
“LCP 07. 传递信息”
- 解法:DP
- 思路:
- 用一般的 DP 迭代演化即可
- 注意题目给定的 Graph 结构无需改造,直接在每轮迭代中利用边即可
- 思路:
“剑指 Offer 22. 链表中倒数第 k 个节点”
- 解法 1:链表反转
- 思路:
- 先执行一遍链表反转,这样 tail 就成了 head
- 然后在执行一遍链表反转,这时根据输入参数计数 k,然后返回第二次反转后的链表中段即可
- 思路:
“剑指 Offer 22. 链表中倒数第 k 个节点” LinkedList RevertLinkedList
- 解法 2 :TowPointers
- 思路:
- 两个指针 slow fast,遍历中保持 slow fast 的间隔为 k
- 当 fast 指向结尾的 nil 时,返回 slow 即可
- 思路:
“剑指 Offer 22. 链表中倒数第 k 个节点” LinkedList TwoPointers
其它一些题
- 给定整形数组,求其中子串和为 0 的个数,子串允许叠加
- 解法 1,prefix sum
- 用 preSum 数组存储前缀和,然后双层循环求每一子串和是否为 0
- 这个算法的缺点是空间复杂度较高,连续内存不好申请;时间复杂度也高,需要 O(n^2)
- 解法 2,prefix sum map
- 基于解法 1 的思路,可以观察前缀和数组特性,preSum 元素每重复出现一次,说明中间这段子串和为 0
- 可以利用 map 记录 preSum 的出现次数,默认累加值为 0
- 注意初始化
countMap[0]=1,如果 0 出现了则自动累加
- 解法 1,prefix sum