 本文记录 Redis
本文记录 Redis 对象的类型与编码
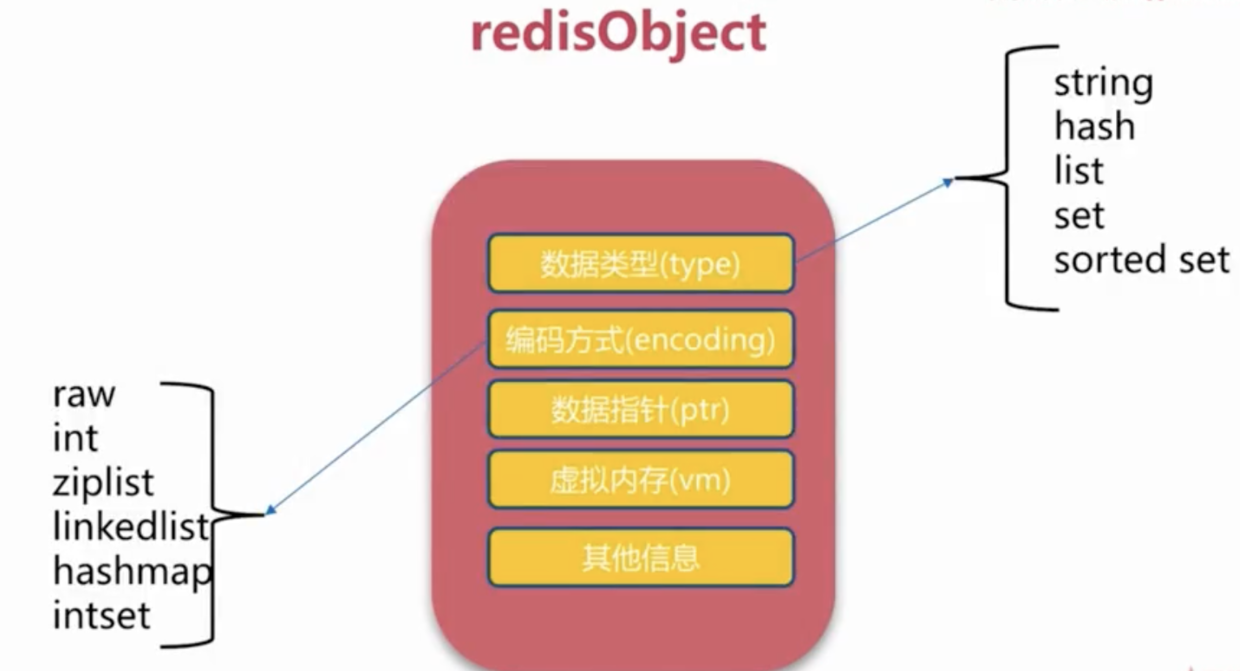
Redis 中存储键值对时,至少要创建一个键对象和一个值对象,而这两种对象都由下面数据结构表示:
typedef struct redisObject{
// 类型
unsigned type;
// 编码
unsigned encoding;
// 指向底层数据结构的指针
void *ptr;
// 引用计数
int refcount;
// 记录最后一次被程序访问的时间
unsigned lru;
}robj
type就是对象类型,用type key命令查看encoding决定ptr指针指向对象的具体数据类型,用OBJECT ENCODING key命令查看
类型及编码
| 类型值 | 编码值 | 对象数据结构 | 切换条件 |
|---|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 用整数值实现的字符串对象 | 可以用 long 表示的整数 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | SDS, redisObject 和 ptr 指向的内存是连续分配的 | 保存长度小于 44 字节的字符串,并且只读(修改即切换) |
| REDIS_STRING | REDIS_ENCODING_RAW | SDS, redisObject.ptr 指向独立的内存 | 保存长度大于 44 字节的字符串 |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 压缩列表实现 list | 元素个数 < 512 同时元素长度 < 64 字节 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 双向链表 | - |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 压缩列表实现 hash | 元素个数 < 512 同时元素长度 < 64 字节 |
| REDIS_HASH | REDIS_ENCODING_HT | HashTable | - |
| REDIS_SET | REDIS_ENCODING_INTSET | 有序整型数数组 | 所有元素都是整数,同时元素数量不超过 512 |
| REDIS_SET | REDIS_ENCODING_HT | HashTable | - |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 压缩列表实现 zset | 元素个数 < 128 同时元素长度 < 64 字节 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | SkipList | - |
- embstr 与 raw 都使用 redisObject 和 sds 保存数据,区别在于,embstr 的使用只分配一次内存空间(因此 redisObject 和 sds 是连续的),而 raw 需要分配两次内存空间(分别为 redisObject 和 sds 分配空间)。因此与 raw 相比,embstr 的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而 embstr 的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个 redisObject 和 sds 都需要重新分配空间,因此 redis 中的 embstr 实现为只读。
- Redis 中对于浮点数类型也是作为字符串保存的,在需要的时候再将其转换成浮点数类型。
- list-max-ziplist-value、list-max-ziplist-entries 可配置 list 采用 ziplist 的边界条件
- hash-max-ziplist-entries 可配置 hash 采用 ziplist 的边界条件
- set-max-intset-entries 可配置 set 采用 intset 的边界条件
- zset-max-ziplist-entries、zset-max-ziplist-value 可配置 zset 采用 ziplist 的边界条件
zset 特殊结构
zset 采用 skiplist 数据结构时有如下定义:
typedef struct zset{
// 跳跃表
zskiplist *zsl;
// 字典
dict *dice;
} zset;
如上所述,zset 同时使用了 skiplist 和 dict 两种数据结构。
- dict 可以快速判断元素是否存在、取得元素值,一次操作时间复杂度为 O(1)
- skiplist 可以实现有序查找元素,一次操作时间复杂度为 O(logn)
- dict 的 key 是元素的值、value 是元素的分值;skiplist 的 scroe 属性保存元素的分值,object 属性保存元素值; 这两种数据结构通过指针共享元素的分值和值,不会造成内存浪费。
其他类型及底层实现类型
用type key可以查看一个 key 的底层类型,有些类型本身没有创建新类型,只是封装了一层。
| 外部类型 | 内部类型 | 封装说明 |
|---|---|---|
| Bitmap | string | 以 raw 类型编码, 利用位操作, 最大支持 512MB |
| GeoHash | zset | 以 GEO 码做 score, value 存储精确的经纬度 |
| Stream | list | 每个元素保存一个 msg_id 并保持递增, 为每个 group 记录一个 idx |
| HyperLogLog | string | 以 raw 类型编码, 连续 16384 个 6bit 的串成的位图,共 12KB,在基数较小时采用稀疏存储 |
内存管理
引用计数
- redisObject.refcount 用于引用计数对象内存回收,当 refcount 减为 0 时回收内存。
- 一个 redisObject 对象可以被多个指针引用,例如顺序执行
set k1 100、set k2 100后,两个指针指向同一个REDIS_ENCODING_INT编码的对象,对应的 refcount 值为 2 - Redis 的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和 CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为 O(1);对于普通字符串,判断复杂度为 O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为 O(n^2)。
- 虽然共享对象只能是整数值的字符串对象,但是 5 种类型都可能使用共享对象(如哈希、列表等的元素可以使用)
空转时长
- redisObject.lru (Least Recently Used)记录最后一次被访问的时间,
- 用
OBJECT IDLETIME key命令可以查看空转时长,空转时长(秒数) = 当前时间 - lru - 如果打开了
maxmemory选项并且回收算法选择volatile-lru或volatile-lru,则会优先释放空转时长较长的内存
内存回收策略(key 删除策略)
- maxmemory-policy: 当内存使用达到最大值时,redis 使用的清除策略。有以下几种可以选择:
- volatile-lru 利用 LRU 算法移除设置过过期时间的 key (LRU:最近使用 Least Recently Used )
- allkeys-lru 利用 LRU 算法移除任何 key
- volatile-random 移除设置过过期时间的随机 key
- allkeys-random 移除随机 key
- volatile-ttl 移除即将过期的 key(minor TTL)
- noeviction 不移除任何 key,只是返回一个写错误,默认选项
“坑”场景
- hash 乱序
- 现象: 试验时候,存储了数据,取出是有序的;实际使用时候,发现里面存的数据发生了乱序。
- 原因: 试验时候数据量小,底层用 ziplist 存储,所以有序;正式使用时采用 Hash 存储,导致乱序。
- 经验: hash 本身是无序的,不能依赖这个顺序,否则可能随机发生问题不易调查