 java.util.HashMap(jdk8) 设计精巧,在这里记录一下底层原理
java.util.HashMap(jdk8) 设计精巧,在这里记录一下底层原理
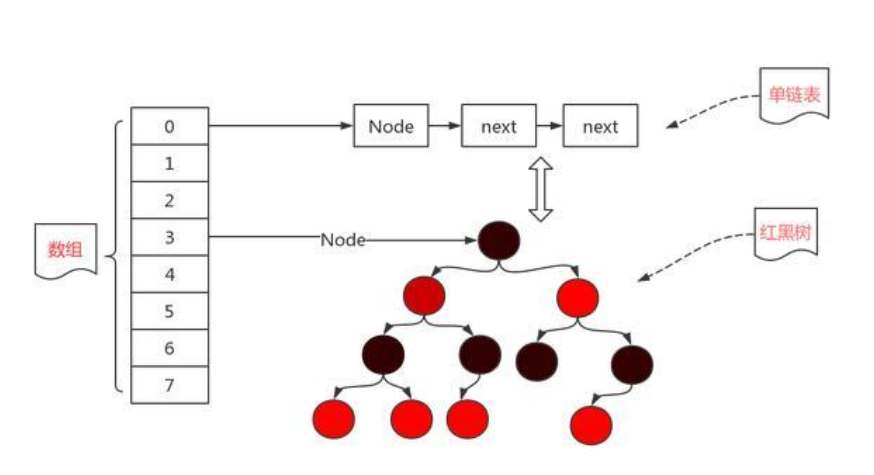
基本结构
- hash 任意长度的输入输入,经过 hash 函数的处理,输出一个固定长度的输出值,用来生成输入数据的指纹。输入数据的微量变化必然导致结果不同,这样在输入非常临近的情况下输出不会是同一个值。
- hash 冲突(碰撞) 由于输出值是固定长度,包含信息量较小,所以两个不同的输入可能输出相同,这就是冲突。
- node(key+value+next+hash) 一个 key-value 对组成一个 node,记录着 HashMap 中的一个元素
- bucket bucket 是一个数组,数组元素是一个 node。key 经过 hash 运算、对 bucket 长度取模后可作为 bucket 的下标,用于 CRUD。CRUD 时间复杂度 O(1) 如果有两个元素 key 值不同,但是经过 hash 运算、对 bucket 取模后被分配到同一个 bucket 下标,这就发生了 hash 碰撞,两个元素都要存储在这个 bucket 位置
- slot bucket 中的每个位置就是一个 slot,默认填充 null
- list node 有一个 next 属性指向下一个 node,可以形成单链表,用来处理发生 hash 碰撞的情况,可以把碰撞的元素存在链表中。CRUD 时间复杂度 O(n)
- 红黑树 如果局部 hash 碰撞情况较多,但整体没有达到扩容标准,list 过长可能引起性能问题,这时可以将链表转化为红黑树。CRUD 时间复杂度缩短为 O(logn)
- 扩容 bucket 的初始容量是 16,当 HashMap 中的元素数量与 bucket 长度的比值达到 0.75(负载因子)时,就会发生扩容。每次扩容 bucket 的容量左移一位(相当于*2,但是性能更好),最大容量为 2^30。
1 | |
算法细节
-
通常的一个插入动作流程
- 通过
node.key计算node.hash - 通过
node.hash计算 bucket 中的 slot 位置 - 如果
slot == null,直接插入 - 如果
slot != null,对比 key 是否相等,相等则替换 node;如果不相等,则链化;如果已经链化,则遍历比较,然后插入; - 4 插入之后如果达到了树化阈值则进行树化,转为红黑树
- 如果 slot 已经是红黑树,则遍历查找、对比 key 是否相等,插入/替换 node
- 达到负载因子条件,扩容
- 通过
-
扩容流程
- 达到扩容标准后,申请一个新的容量增加一倍的 bucket 空间,然后顺序处理每一个元素
- 如果只是普通 node,赋值到新 bucket 对应空间即可
- 如果是链表,则将其拆分为高位链和低位链,低位链填入新空间同样位置,高位链填入新空间新位置,新位置 = 旧位置 + 旧容量
- 如果是红黑树,则利用红黑树仍然维护的 next 形成的链表分为高位链和低位链,填入新空间,方法同链表。如果拆分出的链表长度<=6,则按链表处理;如果拆分出的链表长度 >6 ,则升级为红黑树。
-
hash 算法应具有的特点
- 计算效率高,便于大量数据使用
- 是单向散列的,不能从结果逆推出原文
- 输入的少量不同,输出一定不同
- hash 后的结果要尽量的分散,避免 hash 倾斜
- node.hash 并不是 Object.hashCode()的值
- Object.hashCode()是为了用于快速比较对象内容的方法
node.hash = node.key.hashCode()>>16 ^ node.key.hashCode(),通过这样的运算,hash 值低 16 位中蕴含了高 16 位的信息,这样对于低位相同而高位不同的 key 可以从低位直接区分出来。由于通常 HashMap 的容量不会太大,所以高 16 位在寻址算法时很难用到,取异或后相当于在低 16 位也用到了。后续通过低位取 bucket 位置时可以减少 hash 冲突。- bucket 中下标寻址算法是
index = node.hash & (bucket.length - 1)。因为bucket.length一定是2^n,所以其二进制高位是一个 1,低位全是 0。例如默认容量2^4 - 1 = 16 - 1 = 0b10000 - 0b1 = 0b1111,这样进行了寻址算法后取得的 index 一定在bucket.length范围内。这样取下标的好处是避免使用取余运算,因为 CPU 进行取余时耗费的时钟周期是二进制运算的 1000 倍。
-
懒加载机制 new HashMap 时,bucket 的容量并没有创建,在第一个 put 时才创建。这有利于减少不必要的空间浪费。jdk7 是 new 时直接创建,jdk8 改进为懒加载
-
关于链表的”尾插”和”头插” 在 jdk8 之前新节点是插入到尾部,jdk8 改为头部。这样更好的符合了”时间的局部性”原理,之后重复 key 值被操作时可以更快找到。
-
关于”高位链”、”低位链” 在扩容拷贝过程中,链表会被拆分为高位链和低位链。比如扩容前
bucket.length - 1 == 2^4 - 1 == 0b1111,那么做寻址运算时,0b10001 & 0b1111和0b1 & 0b1111的结果都为0b1,被放在了一个 slot 中,其中0b10001在拆分时会放在高位链,而0b1会放在低位链。 - 链表重构为红黑树的条件 在新增一个元素时,链表长度达到 8 同时 HashMap 容量已达到 64 时,才会重构。如果链表长度达到 8 但是 HashMap 容量不足 64,则会触发 bucket 扩容。
线程安全的 HashMap
HashMap 并非线程安全,在多线程情况下链表操作可能引起死循环。所以就有了三种线程安全的 HashMap: Collections.synchronizedMap(map)、Hashtable、ConcurrentHashMap
-
Collections.synchronizedMap(map)是直接用 synchronized 包装过的线程安全的 Map,而 Hashtable 是在一些可能引起线程安全问题的特定方法增加了 synchronized 锁。
-
ConcurrentHashMap 是专门做了线程安全优化的 HashMap,构造比较复杂
- 每一个 slot 加一个锁,这样发生锁竞争的情况就会很少
- 利用 LongAdder 原理实现了高并发时的 size 计算,相比锁和 CAS 效率更高
- 定义了一些特殊节点如:ForwardingNodes(转移节点)、ReservationNodes(瞬态节点),用于大并发下进行扩容操作
- 通过精妙的设计可以多个线程一起参与扩容过程,减少时间消耗