 Apache Kafka 是一个分布式、开源消息队列(MQ message quere)系统,由 Scala 写成。可为网络服务提供一个高通量、低延迟的异步消息中间件。
Apache Kafka 是一个分布式、开源消息队列(MQ message quere)系统,由 Scala 写成。可为网络服务提供一个高通量、低延迟的异步消息中间件。
- Scala 也是基于 JVM,可以和 Java 混编
- Kafka 在 2011 年初被 LinkedIn 开源,后由 Apache 开源维护
MQ 的应用场景
MQ 类似 Queue,符合 FIFO(First In First Out)规则,通常用于生产者消费者模式。
- 大并发下的削峰作用 由于 Kafka 集群的性能高、高可用,所以常用于大并发下将任务暂存,然后异步处理,避免实时系统超负荷导致雪崩。
- 对实时性要求不高的异步处理 对于对响应速度要求不高的场景,可以利用异步处理架构提高系统的稳定性。比如发邮件系统。
- 调用时机解耦合 可以利用 Kafka 作为消息中间层进行解耦合。上游只负责生产数据,不用非等下游返回才能继续执行
核心结构
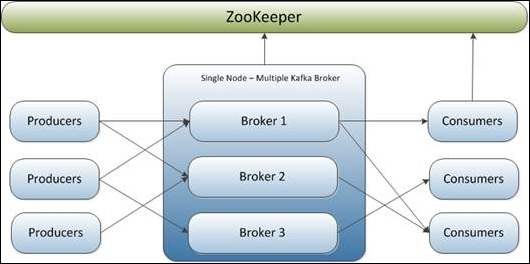
- Topic(主题) 消息按照 Topic 进行分类,在一个类型中进行生产、消费。
- Producer(生产者) 向 Topic 发送消息
- Consumer(消费者)
从 Topic 取消息消费。分为 push 和 pull 两种消费模型
- push 模式,也叫”发布订阅模式”,Consumer 先订阅指定的 Topic,当有新消息时,Kafka 主动将消息 push 给消费者客户端。
- pull 模式,由 Consumer 主动拉数据。
- Broker(服务) Kafka Cluster(集群)是由多个实例组成的,每个服务实例称为 Broker
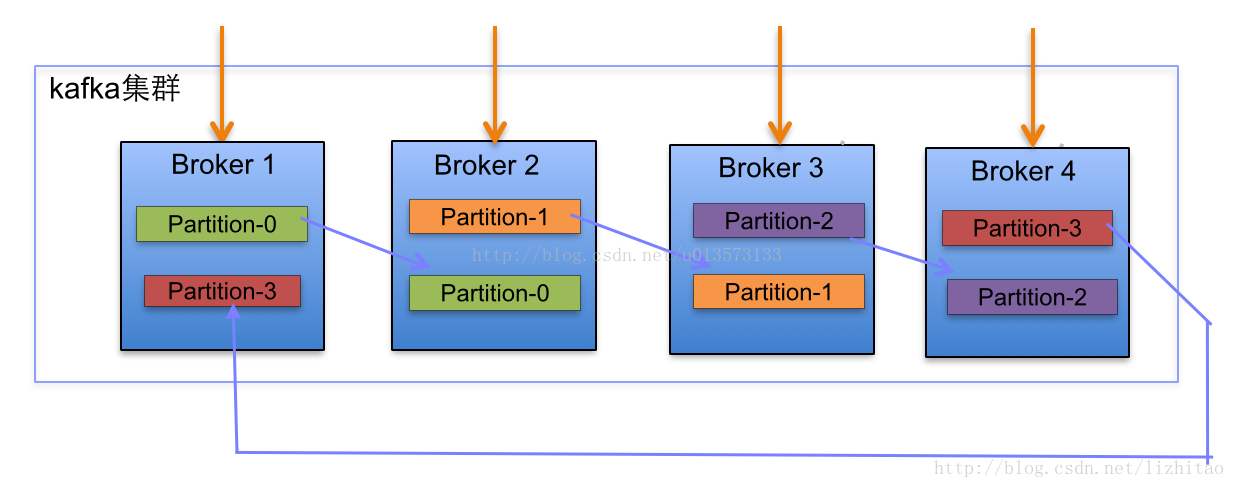
- Partition(分区)
为了实现扩展性,一个 Topic 可以分布到多个 Broker 上,每个 Broker 上对应这个 Topic 分配一个 Partition。每个 Partition 是一个有序队列,Partition 中的每条消息会分配一个 id(offset)。kafka 只能保证一个 Partition 中的消息顺序发给 Consumer,不保证一个 Topic(多个 Partition 间)的顺序。Kafka 集群会自动分散分配 Partition,一个 Broker 不会存储同一个 Topic 的多个 Partition,创建时会失败,这样可以更好的利用磁盘的吞吐量。
- Offset(偏移量) 在 Producer 发送一条消息到 Kafka 时,会产生一个 Offset,表示在一个 Partition 中的唯一偏移量,这个值在一个 Partition 中的自增的
- 订阅的最小粒度是 Topic,不可以订阅 Partition。Consumer 在每个 Partition 上的当前 offset 存储在 Zookeeper 中。
- pull 的最小单位也是 Topic,一般根据 range 策略将 Partition 分配给 Consumer。Partition 按数字排序、Consumer 按字母顺序排序,然后整除分配。
- Partition 中存储的每条数据包含:index(索引, offset)、event log(二进制内容)、timeIndex(时间索引)
- Partition 中的数据存储在磁盘中,可以按照 offset(index)、时间段进行查询。
- Replicated Partition(副本分区) 为了实现高可用、避免单个 Broker 宕机后无法使用的情况,一个 Partition 可以有多个副本。各个副本与原 Partition 以及各个副本间不允许在同一个 Broker 上,创建时会失败。往同一个 Topic 发送消息时,默认以轮训的方式发到 Partition,也可以自己指定 Hash 方式确定 Partition。
- Leader 原 Partition 所在的 Brokder 也叫 Leader,负责对应 Partition 的读写
- Follwer 副本 Partition 所在的 Broker 也叫 Follwer,副本在原 Partition 失效后起作用
- Controller 在集群中负责管理的 Broker,负责分配 Partition、监控 Broker 失效
- Zookeeper
分布式文件系统,Zookeeper 集群可以为上面各个角色保存 meta data(元数据),来保证系统可用性。可以通过 Zookeeper 查询到 Kafka 的各种信息。
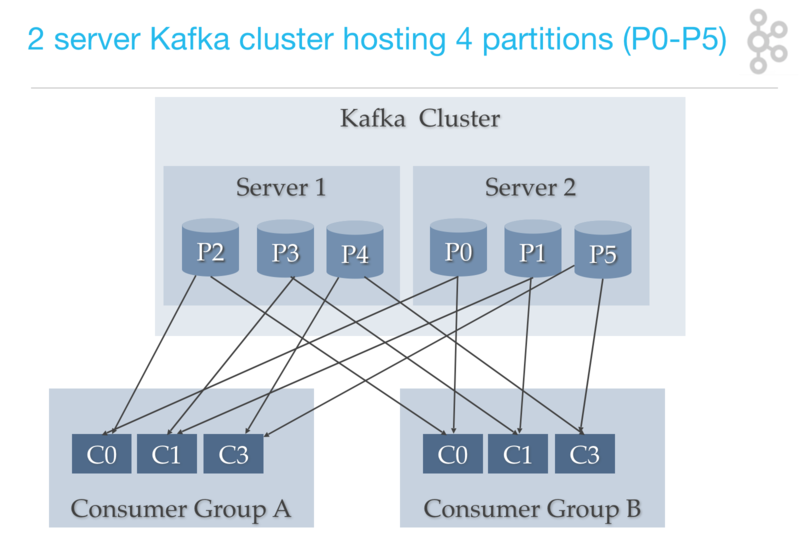
- Consumer Group(消费组)
Consumer 并不是独立存在的,一个 Consumer 必定属于一个 Consumer Group。有时,单个 Consumer 消费速度不足,可以通过设定几个 Consumner 在一个 Consumer Group 中。
- 一个 Consumer Group 有一个 group.id,是唯一标识
- 一个 Consumer Group 可以订阅多个 Topic,但该 Topic 的一个 Partition 只能分配给一个 Consumer 实例消费
- 不同的 Consumer Group 可以消费同一个 Topic 下的同一 Partition
- 一个 Consumer Group 中 Consumer 的实例数不应超过 Topic 的 Partition 数,超过了不会起作用
- 如果已经分配了一个 Topic 的 Partition 和一个 Consumer Group 的 Consumer 绑定,但是这个 Consumer Group 宕机了,则会自动进行 Rebalance 动作,分配一个新的该 Consumer Group 下的 Consumer
性能和特性
- 优点
- 通过消息队列解偶
- 可实现 ETL(Extract-Transform-Load)/CDC(Change-Data-Capture)架构
- 可消化海量数据
- 高吞吐率
- 基于硬盘的存储
- 多个 Producer/Consumer 并行处理
- 高可伸缩性(集群横向扩展)
- 容错性(一致性保证机制)
- 低延迟
- 高可配置性
- 可实现 Backpressure 反向限流机制
- 缺点
- 异步机制不易理解,容易出设计漏洞
- 并不适合真正”实时响应”的低延迟系统
处理速度
- 每个 Broker 每秒可读取百万次
- 每个 Broker 每秒写入可达数万条
容量
- 每个 Broker 可存储上千个 Partition
- 可以设置通用的消息保留条件,可以设定保存多大容量之内的消息或保存多长时间之内的消息
- 也可以为每个 Topic 可以设置消息保留条件
Topic 有序机制
同一个 Topic 的多个 Partition 间的顺序不能保证,如果想整个 Topic 的顺序保证,那只能建一个分区。 如果想保证特定的一些消息有序,可以利用 Hash 等方法,将这些消息发往同一个 Partition,这样无论 Consumer 如何消费,都能保证这些消息被有序消费。
一致性保证机制
- At-Least-Onece 最少一次,可能重复
- At-Most-Onece 最多一次,可能丢失
- Exactly-Onece 精确一次,不多不少
ACK 应答机制
Producer 向 Kafka 发送消息后,Kafka 会以下面三种方式应答:
- 0, 生产数据不需要 ACK。速度较快,数据可能丢失(例如 Broker 宕机)。属于 AT-MOST-ONECE
- 1, Leader 写入磁盘后给响应,速度一般,可能数据重复。属于 AT-LEAST-ONECE
-
-1, Follwer 都写成功后给响应,速度慢,可能数据重复。属于 AT-LEAST-ONECE
- 设置为 1,响应为 OK 的情况下,消息为什么会丢失? 当 Leader 写入后返回 OK 的响应,但是没来得及同步 Follwer 就挂掉了,这时消息就会丢失
Kafka 向订阅的 Consumer 发送消息,符合 AT-LEAST-ONECE 机制。Consumer 应答后则认为收到了消息,否则会重试。
- Kafka 原生不提供 Exactly-Onece 机制,但是可以使用 KAFKA STREAMS 等第三方库 实现。Exactly-Onece 机制的关键是对每个消息进行唯一标识并判断是否重复,由 Kafka 保证 At-Least-Onece。
权衡组合
通常 Kafka 集群有下面两种使用模式:
- RELIABILITY(高可靠)+CONSISTENCY(一致性)
- AVAILABILITY(高可用)+HIGH-THROUGHPUT(高吞吐量)+LOW-LATENCY(低延迟)
常用命令
创建 Topic
创建 Topic 时要指定 Zookeeper、Partition 的数量、每个 Partition 的副本数
./kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partition 3 --replication-factor 2
启动 Producer
Producer 启动参数要有 Kafka 集群节点
./kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test1
启动 Consumer
Consumer 启动参数需要填 Zookeeper,在 Zookeeper 会自动保存该 Consumer 的消费到的 offset
./kafka-console-consumer.sh --zookeeper node01:2181,node02:2181,node03:2181 --topic test1
查看所有 topic
./kafka-topics.sh --zookeeper 192.168.40.148:2181 --list
查看 kafka 指定 topic 的详情
./kafka-topics.sh --zookeeper 192.168.40.148:2181 --topic testtopic --describe
查询 topic 内容
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topicName --from-beginning
查看消费者 consumer group 列表
./kafka-consumer-groups.sh --bootstrap-server 192.168.40.148:9092 --list
查看消费者 consumer group 详情
./kafka-consumer-groups.sh --bootstrap-server 192.168.40.148:9092 --group logstash-xdoctorx --describe
常见问题
Consumer 重复收到消息
- 问题现象 Consumer 有规律重复处理消息,大概每隔 30 秒重复处理一次消息
- 原因分析 Consumer Group 中的另一个 Consumer 原本负责其中一个 Partition 中的消息,但是这个 Consumer 处理一条数据结束时崩溃,没有给 Kafka 返回 ACK。Consumer 宕机后,Kafka 进行 Rebalance,分配到发生重复收消息的那个 Consumer 上,重复处理了消息。而宕机的 Consumer 被 Supervisor 自动重启,然后再次 Rebalance、处理消息,所以有规律的重复。
- 解决方案 修正代码,不再宕机即可
Consumer 处理消息速度很慢
- 问题现象 Consumer 处理消息速度慢、吞吐量低,从 log 查看是从 Kafka 拉取数据较慢
- 原因分析 Consumer 消费消息时缓冲时间设定过短,导致网络交互次数过多,严重影响吞吐率
- 解决方案 设定缓冲时间为 1 秒,即可解决
Producer 生产消息速度慢
- 为了避免宕机时丢失消息,将写入缓冲区条数设置为 1 条,原本没有问题,但是当并发较大时,频繁写入磁盘导致 kafka 吞吐率太低。
- 优化方法:将写入数据缓冲区条数改大,发送者发送前记录 log 以便极端情况下恢复丢失数据
- 生产者在大并发下每秒生产上万条数据,但是数据始终没有发到 kafka 里,数据积压造成丢失
- kafka 在多个 Partition 副本的情况下,设置了 ACK 应答模式为 -1,要所有 Partition 副本都写入成功后才返回成功响应,导致写入过慢。改为 1 后修复问题。
- Producer 处理过程中要留下 log,以便极端情况下可以分析 log,重发 kafka