单表复合索引用法
在 SQL 中索引的利用时机点顺序(从左到右)是where ... group by ... having ... select ... order by
在上面的依次匹配中,索引字段出现的顺序要符合最佳左前缀原则:
- 要从最左边的复合索引字段开始,依次使用
- 语句之间可以连续使用,例如
where a,b ... order by c,d,这样也算是连续使用 - 不允许出现跨列,如果跨列则会完全不使用或者中断使用,例如:复合索引
a,b,c,d,以a,b,d,c顺序使用时只用到a,b
其他优化点:
- SQL 优化器会把一些明显的问题自行修正,比如在
where中你使用b,c,a,会被自动优化为a,b,c。但最好还是不要依赖优化器 - SQL 优化器会将前后 SQL 语句中的字段综合优化,例如
where a,d ... order by b,c,会被优化为a,b,c,d,最终不会出现using filesort - 多个复合索引之间,可能发生干扰,所以不用的复合索引要删掉
- where 中的 in 可能导致索引失效(发生跨列),可以通过调整复合索引字段顺序以及 where 语句中字段顺序(将用到 in 的字段向后调整),使得索引尽量可以多命中
- 与 in 同理, 与其等价的 or 也会导致索引失效
联表查询索引优化
- “小表驱动大表” 在联表查询时,关联字段小表(数量少的表)放在左边,如
select ... where 小.a = 大.b这样做的原理是 Mysql 在遍历时左边会作为外层循环,在嵌套循环中外层循环次数少、内层次数多,这样更符合空间的局部性原理,遍历效率更高。- 同理,for 循环中循环次数少的放在外层、循环次数多的放在内层,这样寄存器总的切换次数会更少
- 在左连接中,给左表 on 关联字段加索引;右连接中,给右表关联字段加索引;另外,where 后的第一个字段要加索引
索引失效的情况
- 复合索引依照”最佳左前缀”原则使用,从最左边开始匹配,顺序使用,不要跨列。跨列将导致索引使用中断,不过前面的已经使用了。
- 使用 in/or 时,索引失效。or 在旧版本中会把左边的有效索引也干掉,新版本不会
- 在索引上进行操作时将导致索引失效,例如:计算、函数、类型转换
select ... where a*3 = 6;这里进行了计算,索引失效select ... where id='123',对数字类型使用了字符串查询,进行了隐含的类型转换,索引失效
- 对于复合索引,如果前面的索引由于操作而失效,则后面的索引也失效
- 索引使用”不等于”
!= <>或is null或is not null,索引失效 - 对于两个独立的索引,如果 where 语句中都用了,Mysql 会自动用其中一个
- like 如果以
%开头,则索引失效。用常量开头,不会失效。- 如果必须
%开头,可以利用索引覆盖,索引不会失效
- 如果必须
</<的右边(后边)索引失效- 由于优化器,索引优化会存在概率问题
复合索引失效原因——复合索引数据结构
为什么<出现之后,索引就会失效?为什么 like 以%开头时索引就会失效?原因在于复合索引的数据结构:
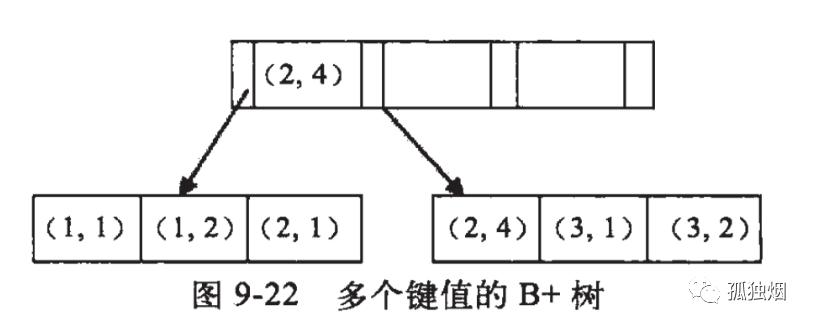
上面是一个 InnoDB 复合索引,由两个 int 型字段组成,假设(A,B) 在 InnoDB 的查询过程,其实是一个数据排序查找过程,最好的方式是通过已有序的索引进行二分查找。 假设我们查找(1,3),那么二分查找找到(1,)后,再二分查找(1,3),发现(1,3)不存在。
但是 A 的值并不能确定 B 的值的范围,只有 A 值确定时候,B 的值才有序。如果只是确定 A 的范围,那么 B 的查找将无法利用索引,需要对 B 的值进行排序。
例如where A <= 2,这个范围内,可以快速二分查找到 1、2,但是 B 的值不保证有序,所以要对所有 B 的值进行排序,然后再查找,这种排序过程索引就会失效。
如果是字符串类型的字段,如果以常量开头、%结尾,那么仍然可以利用索引(单字段索引/复合索引)快速确定范围。但是如果以%开头,则无法利用索引。
索引之外的其他优化方法
关于 exists 和 in
select ... from ... where exists (子查询) select ... from ... where field1 in (子查询)
- 如果主查询的数据量大,用 in
- 如果子查询的数据量大,用 exists
- 上面的优化,本质上是用小表驱动大表进行双重循环
order by 优化
using file sort 有两种算法(根据 IO 次数区分):
- 双路排序(4.1 版之前默认),扫描两次磁盘。
- 从磁盘读取排序字段
- 在内存 buffer 里进行排序
- 扫描其他字段
- 单路排序(4.1 版之后默认)
- 只读取一次(全部字段)
- 在 buffer 中排序
- 单路排序会占用更大的 buffer,可以考虑调大 buffer 的容量
set max_length_for_sort_data = 1024(单位字节) - 不一定真的是一次 IO,有可能多次 IO。在数据量大的情况下内存放不下,需要多次读取 IO 读取排序
- 单路排序会占用更大的 buffer,可以考虑调大 buffer 的容量
- 如果 buffer 容量过低,MySQL 会自动切换为双路排序
优化 order by 的方法:
- 根据情况选择单路/双路查询
- 调整 buffer 的大小
- 避免用
select **本身代表哪些字段,需要耗费一次计算*表示所有字段,包含很多无用字段,会占用 buffer 容量*很难达到索引覆盖- 保证 order by 是,多个字段情况下,都是升序或都是降序
索引要用”NOT NULL”
这里只针对 InnoDB 讨论。
- 如果不设置”NOT NULL”,”NULL”是默认值,如果不是故意使用的话,尽量不要默认为”NULL”
- 如果字段为”NULL”,在做索引、索引统计、值计算时会更加复杂
- 聚合函数(如 count)会忽略”NULL”值,导致统计不准确
- 使用
=判断会失效,必须用is null - 进行
group by、order by时,所有 NULL 值会被视为相等
- 索引列”NULL”会带来存储空间问题
- NULL 本身不会占用空间,但会多一个标志位记录是否为 NULL
- 除非是数据本身非常”稀疏”,只有少量值为”非 NULL”,这种适用”NULL”