相关的几种搜索树结构
B Tree(Binary Search Tree,二叉搜索树)
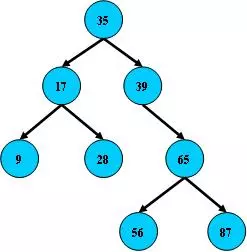
- 所有非叶子结点至多拥有两个子节点
- 所有结点存储一个关键字
- 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树
B- Tree(B-树)
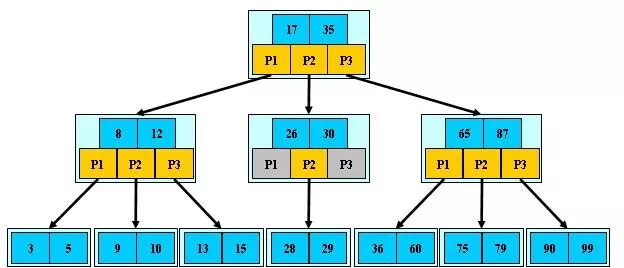
- 定义任意非叶子结点最多只有 M 个子节点, 且 M > 2
- 根结点的子节点数为[2, M]
- 除根结点以外的非叶子结点的子节点数为[M/2, M]
- 每个结点存放至少 M/2-1(取上整)和至多 M-1 个关键字(至少 2 个关键字)
- 非叶子结点的关键字个数 = 指向子节点的指针个数-1
- 非叶子结点的关键字: K[1], K[2], …, K[M-1]; 且 K[i] < K[i+1]
- 非叶子结点的指针: P[1], P[2], …, P[M]; 其中 P[1]指向关键字小于 K[1]的子树,P[M]指向关键字大于 K[M-1]的子树,其它 P[i]指向关键字属于(K[i-1], K[i])的子树
- 所有叶子结点位于同一层
B-树的特性:
- 关键字集合分布在整颗树中
- 任何一个关键字出现且只出现在一个结点中
- 搜索有可能在非叶子结点结束
- 其搜索性能等价于在关键字全集内做一次二分查找
- 自动层次控制
B+ Tree(B+树)
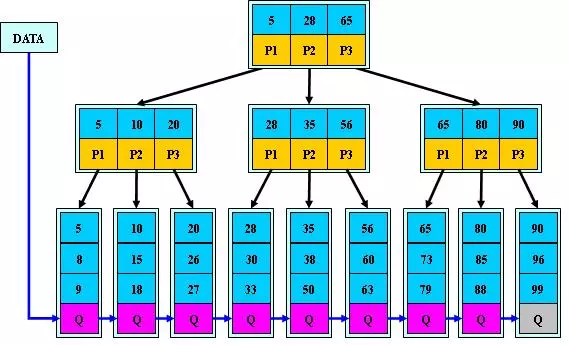
B+树是 B-树的变体, 也是一种多路搜索树,与 B-树的差别:
- 非叶子结点的子树指针与关键字个数相同
- 非叶子结点的子树指针 P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间)
- 为所有叶子结点增加一个链指针
- 所有关键字都在叶子结点出现
B+的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引), 且链表中的关键字恰好是有序的
- 不可能在非叶子结点命中,每次查询数据的节点访问次数是固定的 n,n 就是 B+树的层级
- 非叶子结点相当于是叶子结点的索引(稀疏索引), 叶子结点相当于是存储(关键字)数据的数据层
- 更适合文件索引系统
B* Tree(B*树)
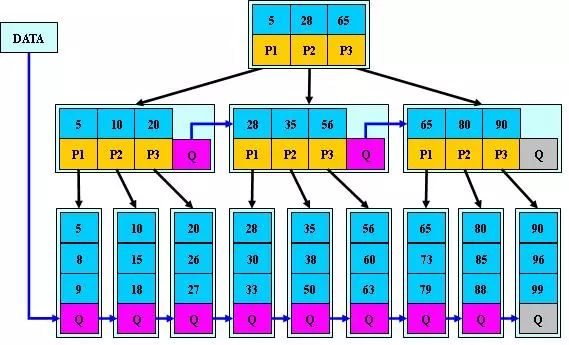
- B*树是在 B+树基础上, 为非叶子结点也增加链表指针
- B*树定义了非叶子结点关键字个数至少为(2/3)M,即块的最低使用率为 2/3(代替 B+树的 1/2);
为什么 InnoDB 选择 B+树?
最关键的问题是硬件约束:内存小,适合存放索引;磁盘大,适合最后取数据;如果数据量较大,大多数的索引也要放在磁盘上;磁盘操作速度比内存慢至少两个数量级,所以磁盘操作次数越少越好。
- 如果用 B 树,层次过多,并且节点上直接有数据,放在内存占用空间,放在磁盘、磁盘操作过多,不合适
- 如果用 B- 树,节点上有数据,会占用内存空间,另外查询速度也不稳定(有可能提前找到结果)
- B+树除叶子节点外,整个索引可以存在内存中(放不下可以放硬盘),叶子节点放在磁盘,占用内存少、磁盘访问次数少、并且比较稳定(固定比较次数找到目标),三层 B+树可以存放上百万条数据(具体由 M 决定)
- B*树非叶子节点的链表用处不大,没必要占用内存,B+树最后叶子节点的链表指针已经可以进行区间取值了
参考:B 树、B-树、B+树