 《Pattern-Oriented Software Architecture–Volume 1–A System of Pattern》中文版于 2013 年出版,被公认为是架构师的必读读物,与《设计模式》同被奉为经典。
《Pattern-Oriented Software Architecture–Volume 1–A System of Pattern》中文版于 2013 年出版,被公认为是架构师的必读读物,与《设计模式》同被奉为经典。
- 本书的知识体系发源于《设计模式》,但是又提高了一个层次,以更通用的视角总结模式。将模式分为三个层次:架构模式、设计模式和成例(方言)。介绍了常用的架构模式、成例,补充了《设计模式》中没有介绍但常用的一些模式。
- 模式有助于将复杂的代码抽象成可学习的内容,提高学习效率、提高沟通效率
- 模式的实现并不局限于特定的范式或语言(这正是我之前把 C++中使用的设计模式应用于 Javascript 时的感受)
- 以前只知道系统设计要按照分层结构(Layers),现在知道这其实只是其中一种模式,只不过这种模式使用较广泛
- 以前只知道单向依赖或依赖倒置,而 Reflection 模式中 Meta 和 Base 层是相互依赖的
- 不得不吐槽一下,这本书的翻译有一些不专业的地方,比如”Proxy”翻译为”代表”,其实有更好的已知的翻译”代理”;有的句子看起来像直接 Google 翻译过来的,有些地方对照英文原版看会更明白。
第一章 模式
1. 模式是什么?
模式最早在建筑学中被使用,建筑师 Christopher Alexander: “简而言之,模式既是现实世界中的一件作品,又是如何及何时创作该作品的规则。”
- 建筑示例:
- 人性需求:1.既想舒适地坐下来。2.又想光线充足的地方。
- 设计模式:低矮的窗台 + 舒适的座椅
- 解释:上面两种元素缺少一种,都会让人很不舒服,而组合在一起往往适合某个场景。
- 软件示例:
- 软件需求:1.带人机界面的程序,对应的有底层数据。2.界面会经常变化、并且可能有多个界面描述同一数据。3.界面对数据会有操作,可以改变数据。
- 设计模式:MVC 设计模式
- 解释:MVC 三个层正好满足了需求,在界面变更时减少了代码变更。
软件架构模式描述了在特定设计情形下反复出现的设计问题,并提供了已得到充分证明的通用解决方案摘要。解决方案摘要描述模式的组件、组件的职责和关系,以及这些组件协作的方式。
2. 模式之所以为模式
- 模式三要素
- 背景 引发设计问题的背景情况
- 问题 在特定背景下反复出现的一系列作用力
- 解决方案 平衡这些作用力的配置方式
- 结构 组件和组件之间的关系
- 行为 运行阶段的行为
3. 模式类型
模式的规模和抽象程度各异,我们将模式分为三类:
- Architectural Patterns(架构模式)
描绘基本的软件系统组织纲要,提供了一组预定义的子系统,指出了这些子系统的职责,也包含用于子系统间关系进行组织的规则和指南。
- 例如:MVC 模式就是一个架构模式,指定了交互式软件系统的总体结构。
- Design Patterns(设计模式)
提供了对软件系统的子系统、组件或它们之间的关系进行改进的纲要,描绘了对彼此通信的组件进行组织的常见结构,可解决特定背景下的一般性设计问题。
- 例如:Observer(观察者模式),比架构模式小,可以独立于编程语言和编程范式(paradigm),可以有效的改进子系统的协作。
- Idiom(方言,译作成例)
是一种低层(low-level)模式,针对的是特定的编程语言。成例阐述如何使用给定的语言的功能来实现组件或组件间关系的特定方面。
- 例如:Counted Pointer 模式,可以用于 C++的引用计数智能指针。而其它很多语言如 Go 就不需要这样的模式。
4. 模式之间的关系
- 改进,例如 MVC 模式就是由多个更小的 Observer 模式改进而来。
- 变种,例如 Document-View 模式是 MVC 的变种,更适合文档的编辑,但通知也更局限于文档编辑。
- 组合,例如 利用 Forwarder-Receiver + Proxy 实现 RPC。
5. 模式的描述
描述、记录模式的目的是让别人也理解新找到的模式,能够用相同的语言、词汇来讨论模式,对于没有接触过该模式的人可以通过描述尽快把握模式的精髓。描述模板如下:
- Name(名称) 模式的名称和摘要
- Also Known As(别名) 模式的其它名称——如果有的话
- Example(示例) 一个真实的示例,证明问题确实存在,对即将介绍的模式确实有需求。在整个模式的描述中,将通过这个示例来说明解决方案和实现。
- Context(上下文/背景) 模式可能适用的情形
- Problem(问题) 模式解决的问题,包括涉及的作用力
- Solution(解决方案) 模式背后的基本解决原则
- Structure(静态结构) 详细说明模式的结构,包括每个参与组件的 CRC 卡(Classes, Responsibilities, Collaborations,面向对象设计中对一个类的描述)以及一个 OMT 类图(也可以用 UML 类图)
- Dynamics(动态行为) 在一些情景下,描述了模式运行阶段的行为。可以用序列图表示
- Implementation(实现) 模式实现指南。这些指南并非不变的规则,应根据实际需求调整实现
- Example Resolved(示例解答) 在前面没有涉及,但对示例的解决至关重要的各个方面进行讨论
- Variants(变种) 简要地描述当前模式的变种或具体化(specialization)
- Known Uses(已知应用) 模式在既有系统中的应用
- Consequences(结果) 模式提供的优点及潜在的缺点
- See Also(参考) 列举其它一些模式,它们要么解决了类似的问题,要么有助于改进当前模式
6. 模式与软件架构
- 模式可以作为我们思维的组件,在设计系统时使用。相比继承、多态这种架构技术,模式更加具体。
- 为了有效的使用模式,要将模式组织成模式系统(pattern system)。这种关系组织方式比模式分类(pattern catalog)更加有效,指出了模式之间错综复杂的关系,有助于寻找适合解决问题的模式及其替代方案。
- 模式的实现并不局限于特定的范式或语言,例如:既是不实用继承(面向对象范式)实现 Proxy,代码差别也很小;利用函数指针完全可以用 C 语言实现 Strategy 模式。
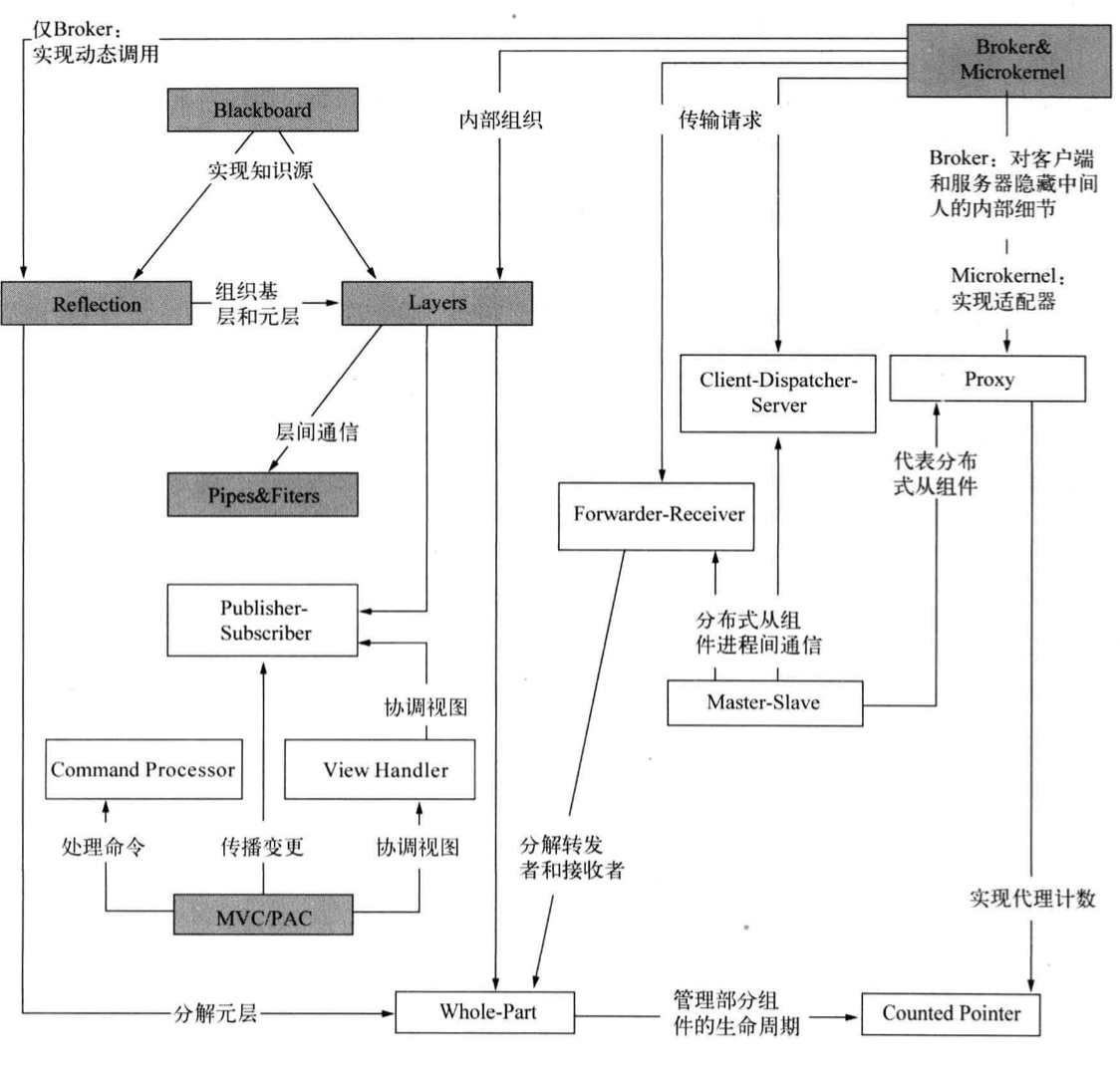
第二章 架构模式
2. 从混乱到有序
在需求没有明确或已部分明确的情况下,只按照需求应用领域的规则来切分模块、类是无助于解决问题的。一方面,最终的系统将包含大量与应用领域没有直接关系的组件;另一方面,我们要求系统不仅能正常运行,还要具备一些与应用程序功能没有直接关系的特质,如可移植性、易维护性、易理解性、稳定性(鲁棒性)等。我们将介绍三个以不同方式对系统进行粗略划分的架构模式:Layers、Pipes and Filters、Blackboard。
Layers
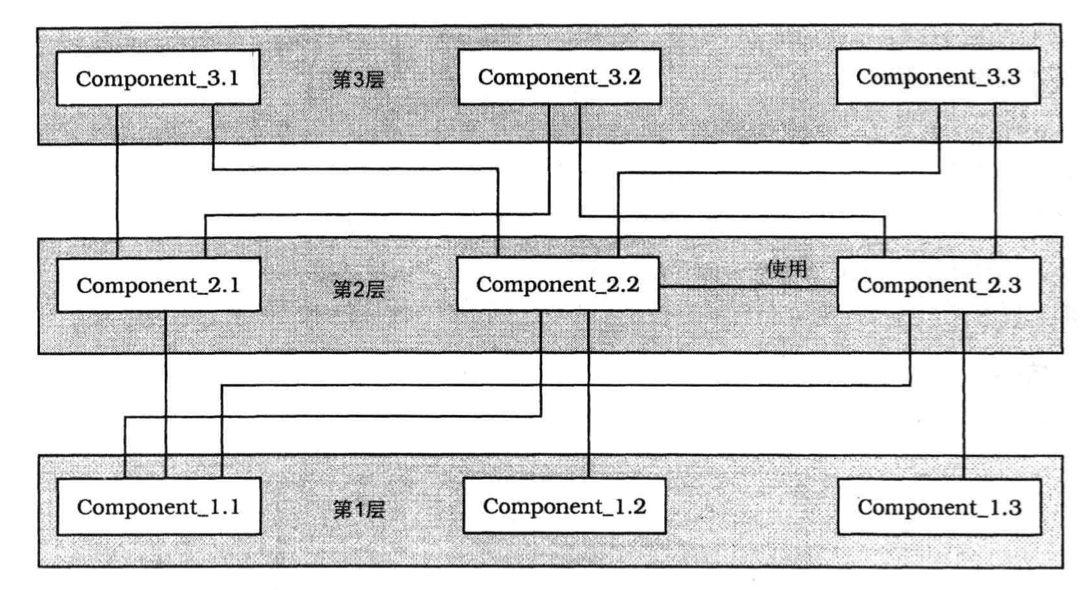 Layers 架构模式有助于将应用程序划分为多组子任务,其中每组子任务都位于特定抽象层。
Layers 架构模式有助于将应用程序划分为多组子任务,其中每组子任务都位于特定抽象层。
示例
网络协议的分层架构
背景
需要分解的大型系统
问题
需要设计一个系统,需要同时解决高层问题和低层问题,而且高层依赖于低层。通常指定了目标平台,高层任务与平台之间的关系并非显而易见,这重要是因为这些任务过于复杂,无法直接使用平台提供的服务来实现。需要平衡下述作用力:
- 以后修改源码不会波及整个系统,其影响限定在一个组件内,不会影响其它组件。
- 接口稳定,甚至遵守标准组织制定的标准。
- 系统的各个部分都可以更换。可使用其它实现替换组件,而不影响其它组件。
- 未来可能需要打造其它系统,这些系统与当前设计的系统面临着相同的低层次问题。
- 应将类似的职责编组,让系统更容易理解和维护。
- 根本没有所谓的标准组件粒度。
- 复杂度组件需要进一步分解。
- 跨越组件边界可能影响性能,例如,必须跨越多个组件边界传输大量数据时。
- 系统将由一个程序员团队打造,因此分工必须明确,在架构设计阶段这种需求常常被忽视。
解决方案
- 笼统的看,解决方案极其简单:将系统划分成适当的层数,并将它们堆叠起来。从最低的抽象层开始,沿抽象阶梯往上走。第 i 层的请求,将转换为发给 i-1 层的请求,每层的所有组件都必须处于相同的抽象层级。每层的服务都实现了一种功能,以有意义的方式组合下一层的服务。另外,服务还可能依赖于同一层的其它服务。
结构
这种结构类似洋葱,每层都将下面的层保护起来,禁止上面的层直接访问它们。
- 类
- 第 i 层
- 职责
- 提供 i+1 层使用的服务
- 将子任务委托给 i - 1 层
- 协作者
- 第 i - 1 层
动态
- 自上而下的请求,往往需要再分解为更多的自上而下的请求
- 自下而上的通知,往往会合并或者不合并的向上传递
- 请求不一定要转发到所有层,如果在中间某层能够处理了就可以直接返回结果
- 有些层是缓存层,要保存数据,所以是有状态的;有些层是只做转发、无状态的,开发起来较简单
- 两个包含 N 层的栈相互通信,其中的栈被称为协议栈,这是通信协议中常见的情景
实现
下面的步骤并不是必须顺序执行或必不可少的,要根据实际程序开发改变,往往是”悠悠球”式的设计过程。
- 定义将任务划分到不同层的抽象准则。
- 根据抽象准则确定抽象层级数。
- 给每层命名并分派任务。
- 规范服务。最重要的实现原则是相邻层界限分明,即任何组件都不跨越多层。在层之间共享模块有悖于严格分层的原则。将更多服务放在高层通常胜过放在低层,低层应尽量保持”苗条”,这就是”倒置的重用金字塔”。
- 完善层次划分,反复执行 1~4 步。
- 规范每层的接口。通常下层对上层来说是一个”黑盒”,只提供一个统一的接口(flat interface)。通常尽量采用”黑盒”而不是”白盒”或”灰盒”。可以利用 Facade 进行封装,如果实在需要知道下层内部结构,可以利用 Reflection 救场。
- 确定隔层的内部结构。可以利用 Bridge 来提供多种实现、用 Strategy 动态的更换算法。
- 规范相邻层之间的通信。通常采用推模型,具体推拉模型之后在 Pipes and Filters 介绍。
- 将相邻层解耦。可以用 Reactor 和 Command 模式解耦。
- 制定错误处理策略。对于分层架构,处理错误的时间和代码量都会特别高。处理错误时最好能在本层完成,如果非要向上抛出则一定要先转换为上层可以理解的出错信息,并且是比较笼统的错误信息。如果不这样做,上层就会因为不了解内部结构而感到莫名其妙。例如我们常见的”404”错误。
示例解答
FTP 应用间通信的功能,实际上是 FTP->TCP->IP->以太网->物理连接->…->FTP 的方式传输的,也是分了 5 层(包含物理连接)。
变种
Relaxed Layered System. 层间关系不那么严格,每层都能使用下面的所有服务。这会使得系统难以维护,常见于操作系统,变化不频繁、性能要求比可维护性要求更高。 Layering Through Inheritance. 常见于面向对象系统中。将低层实现为基类、高层通过继承的方式使用积累。优点是高层可以根据需要修改低层的服务;缺点是高层和低层紧密耦合,当低层修改后,所有代码需要重新编译。
已知应用
- 虚拟机。JVM 就是一种低层平台。
- API。API 通常就是低层向高层提供的。
- 信息系统(IS)。通常包含四层,由上到下分别为:表示层、应用程序逻辑层、领域层、数据库层。
- WindowsNT,属于 Relaxed Layered System。
效果
-
优点:
- 隔层可重用 最佳实践:抽象明确、黑盒模式、良好的文档
- 支持标准化
- 限制了依赖关系的范围 提高可移植性、可测试性
- 可更换性 用 Adapter 模式可以更换实现;用 Bridge 模式可以通过指针动态更换实现;硬件接口更换不同设备
-
缺点:
- 行为变化可能引发雪崩效应 例如低层网络性能变差,为了适应,各层都要改
- 效率低下 分层结构由于层间的数据转换,通常比整体结构(对象海洋)效率更低
- 不必要的工作 如果低层服务做了高层未要求的多余或重复的工作,将对性能带来负面影响。例如用户态到内核态的切换,未必有检查的必要。
- 难以确定正确的层次粒度
参考
- Composite Message 是 Composite 模式的变种,以面向对象的方式在层间传输消息。
- Microkernel 架构可视为一种特殊的分层结构。
Pipes and Filters
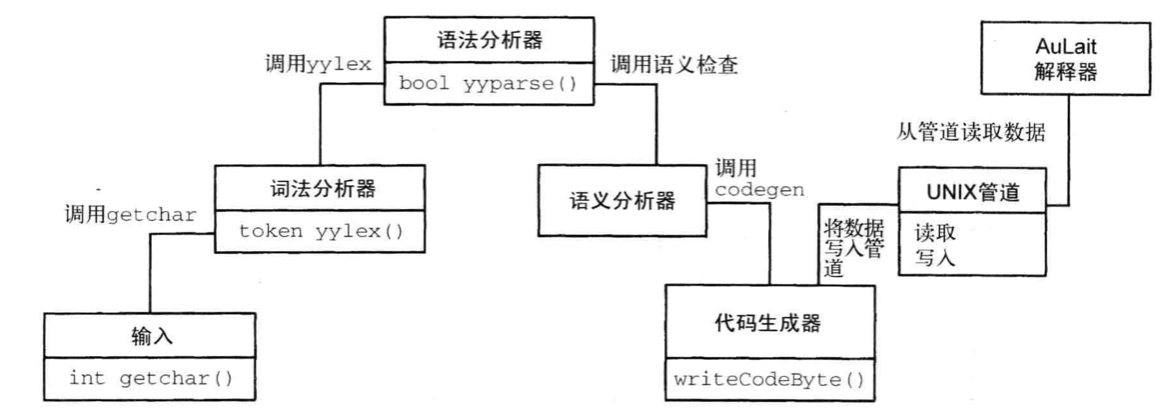 Pipes and Filters 架构模式提供的结构适合用于处理数据流的系统。每个处理步骤都封装在一个过滤器组件中,数据通过相邻过滤器之间的管道传输。通过重组过滤器,可打造多个相关的系统族。
Pipes and Filters 架构模式提供的结构适合用于处理数据流的系统。每个处理步骤都封装在一个过滤器组件中,数据通过相邻过滤器之间的管道传输。通过重组过滤器,可打造多个相关的系统族。
示例
一个可移植的编译器。编译通常要经过下面步骤:词法分析、语法分析、语义分析、中间代码(AuLait Another Universal Language for Intermediate Translation)生成、可选的中间代码优化(针对不同后端)
背景
处理数据流
问题
系统必须对输入数据流进行处理或转换,以单个组件的方式实现这种系统不可行,原因有多个:系统必须由多名开发人员打造;整个系统要完成的任务分多个处理阶段;需求很可能发生变化。需考虑如下作用力:
- 以后可通过更换或重组处理步骤来改进系统,这甚至可以由用户完成
- 相比大型组件,在其他环境中重用小型处理步骤更容易
- 不相邻的处理步骤不共享信息
- 存在不同的输入数据源,如网络连接和提供温度的硬件传感器
- 最终结果能够以各种方式显示和存储
- 如果要求用户将中间结果存储到文件中,供以后进一步处理,将很容易出错
- 应避免同时执行多个处理步骤,如并行或半并行地执行这些步骤
对于事件驱动的交互式系统,就不能划分为一系列执行的阶段,不适用这种架构。
解决方案
架构模式 Pipes and Filters 将系统面临的任务分为多个一次执行的处理步骤。这些步骤通过在系统中传输的数据相关联:一个步骤的输出是下一个步骤的输入。每个处理步骤都由过滤器组件实现。过滤器一边使用数据一边提供数据,而不是等到获得所有输入后才生成输出。这降低了延迟,实现了真正的并行处理。系统的输入由诸如文本文件等数据源提供,而输出进入数据接收器(data sink),如文件、终端、动画程序等。数据源、过滤器、数据接收器通过管道依次相连,每条管道都在相邻处理步骤之间传输数据。由管道连接的过滤器序列成为处理流水线(processing pipeline)。
结构
- 类
- 过滤器
- 职责
- 获取输入数据
- 对输入数据进行处理
- 提供输出数据
- 协作者
- 管道
过滤器组件的三种功能:
- 充实 通过计算和添加信息来充实数据
- 提炼 通过浓缩或提取信息来提炼数据
- 转换 通过改变表示方式来转换数据
过滤器操作可由多种事件触发:
- 下一个流水线元素从过滤器拉取输出
- 前一个流水线元素向过滤器推送输入
- 常见的情况是,过滤器不断地循环,从流水线上游拉取输入,并向下游推送输出
管道指的是过滤器之间、数据源和第一个过滤器之间、最后一个过滤器和数据接收器之间的连接。
- 类
- 管道
- 职责
- 传输数据
- 缓冲数据
- 同步相邻的主动过滤器
-
协作者
- 数据源
- 数据接收器
- 过滤器
- 类
- 数据源
- 职责
- 向处理流水线提供输入
-
协作者
- 管道
- 类
- 数据接收器
- 职责
- 使用输出
- 协作者
- 管道
动态
- 情景 1 推式流水线,数据源首先采取行动。数据写入触发被动过滤器采取行动。
- 情景 2 拉式流水线,控制流程始于数据接收器请求数据。
- 情景 3 推——拉式流水线,数据源和数据接收器都是被动的。在这里,由第二个过滤器主动发起处理过程。
- 情景 4 这是 Pipes and Filters 系统更复杂也更为典型的行为。所有过滤器都主动拉取数据、执行计算并推送数据,因此每个过滤器都运行在独立的控制线程中,如作为独立的进程运行。过滤器由它们之间的缓冲管道同步。该情景还表明,使用过滤器可并行地执行程序。
实现
- 将系统要完成的任务划分为一系列处理阶段,每个阶段都只依赖于前一个阶段的输出。
- 定义沿管道传递的数据的格式。注意数据类型的传输效率,如用文本表示浮点型效率较低。必须定义输入末尾的方式,可以用$、Ctrl-D、Ctrl-Z 等标记。
- 确定如何实现每条管道连接。管道是先进先出缓冲区,可以利用操作系统提供的,也可以直接调用的方式。可以将过滤器实现为独立的线程,并将管道实现为让数据生产者和消费者同步的队列。
- 设计并实现过滤器。
- 设计错误处理机制。流水线出错后很难恢复,通常是重启解决。可以使用特殊标记来标记输入数据流,数据原封不动地传输,最终进入输出,在这个过程中出现故障何以在响应阶段重启。另一种方法是使用管道缓冲数据,在过滤器崩溃时用它来重启流水线。
- 搭配处理流水线。
示例解答
在编译器的实现中,我们采用了全局的符号表,每个过滤器都可以访问。
变种
tee and join 流水线系统。修改过滤器的入口和出口只能有一个的规定,允许过滤器有多个入口和多个出口。将流水线搭建成有向图,甚至可以包含反馈回路。如 UNIX 中的过滤器程序 tee。
已知应用
- UNIX shell 和众多过滤器程序使 Pipes and Filters 随 UNIX 得以风行。
- CMS Pipelines 是 IBM 大型机操作系统的一种扩展。
- LASSPTools 是一个支持数值分析和图形学的工具集。
效果
- 优点:
- 不需要中间件,但也可以使用。
- 可更换过滤器。通常不能在运行阶段更换过滤器。
- 可重组过滤器。如 UNIX 管道机制。
- 可重用过滤器组件。
- 可快速创建流水线原型。
- 效率因并行处理得以提高。
- 缺点:
- 共享状态信息的开销高昂或缺乏灵活性。
- 通过并行处理提高效率的初衷常常成为泡影,原因如下:
- 相比由单个过滤器执行所有计算,在过滤器之间传输数据的开销可能更高。使用网络连接过滤器时尤其如此。
- 有些过滤器使用完所有输入后才生成输出,这要么是它执行的任务(如排序)使然,要么是设计不佳,例如在应用程序允许逐渐处理的情况下没有这样做。
- 在只有一个处理器的计算机上,线程或进程切换上下文的开销大。
- 通过管道同步过滤器而管道缓冲区很小时,频繁地开启和停止管道效率低下。
- 数据转换开销。
- 错误处理。错误处理是 Pipes and Filters 模式的阿喀琉斯之踵。如果用于关键任务系统,根本不可能重启流水线或对错误置若罔闻,应该考虑其他架构(如 Layers)来打造系统。
参考
对于必须可靠运行的系统,Layers 模式更适合,更容易实现错误处理机制。而 Pipes and Filters 模式的重要特征——轻松地重组和重用组件,这是 Layers 模式不具有的。
Blackboard
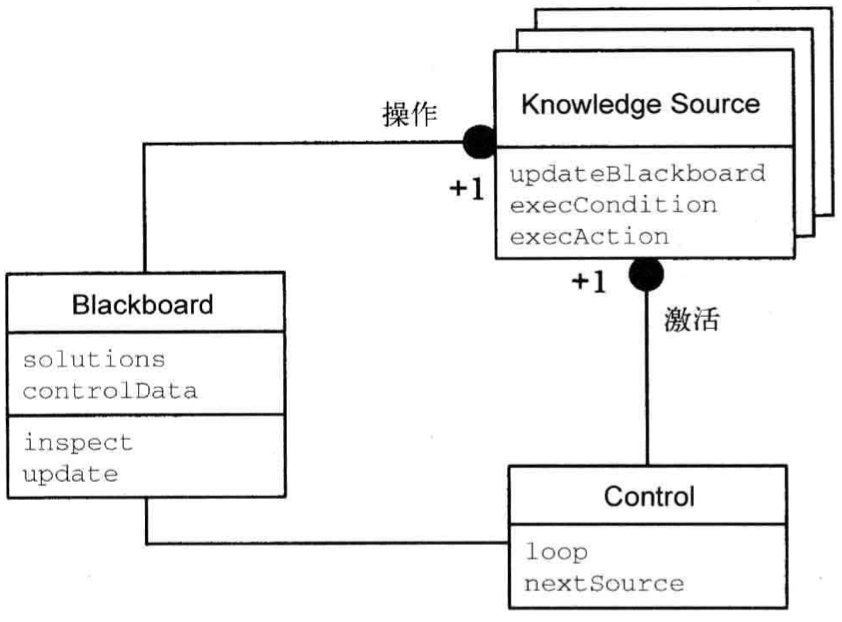 Blackboard 架构模式对还未找到确定解决策略的问题很有帮助。在 Blackboard 模式中,多个专业子系统通过集思广议,获得可能的部分解或近似解。
Blackboard 架构模式对还未找到确定解决策略的问题很有帮助。在 Blackboard 模式中,多个专业子系统通过集思广议,获得可能的部分解或近似解。
PS:Blackboard 的执行过程看起来像是状态模式,寻找最优解的过程正好适用于 AI 类项目。
示例
语音识别,需要跨领域完成功能。
背景
未找到或找不到确定解决之道的不成熟领域。
问题
没有可行而确定的解决方案将原始数据转换为高级数据结构(如图表或英语词组)。例如:视觉识别、图像识别、语音识别、监控等。这种问题具有如下特点:可分解成多个子问题,但每个子问题都属于不同的专业领域。要解决子问题,需要使用不同的表示法和范式。
上述有些领域的信息可能不可靠或不准确,且每个转换步骤都可能提供多个解。在这种情况下,通常能找到最优解,但也可能只有次优解,甚至无解。因此,如果要根据其结果作出重要决策,必须对结果进行验证。
作用力如下:
- 不可能在合理的时间内遍历整个解空间。
- 鉴于领域还不成熟,可能需要对同一个子任务尝试不同的算法。因此,各个模块应易于更换。
- 子问题的算法各不相同。例如,识别波形中语音片段的算法就与根据单词序列生成词组的算法毫无关系。
- 输入、中间结果和最终结果的表示方式各不相同,而不同算法是根据不同范式实现的。
- 一个算法通常使用另一个算法的结果。
- 涉及不可靠的数据和近似解。
- 算法的执行顺序不确定时还可能要求支持并行。应尽可能避免严格按照顺序执行的解决方案。
解决方案
Blackboard 架构背后的理念是,一系列独立的程序携手合作,致力于处理同一个数据结构。每个程序善于解决整项任务的某一部分;所有程序同理合作,致力于找到解决之道。
结构
对系统进行划分,使其包含一个黑板组件、一系列知识源以及一个控制组件。
黑板为中央数据存储区,解空间中的元素及控制数据都存储在这里。我们使用术语词表(vocabulary)表示可能出现在黑板上的所有数据元素。黑板提供了一个接口,让所有知识源都能够对其进行读写。
解空间中的所有元素都可能出现在黑板上。对于在问题解决过程中得到的解,如果它出现在黑板上,我们便称之为推测(hypothesis)或黑板项(blackboard entry)。遭到否决的推测将从黑板中删除。
每个知识源都是一个独立的子系统,解决整个问题的特定方面。这些知识源解决的子问题一起构成问题域。任何一个知识源都无力独自完成系统面临的任务,找到解的唯一途径是整合多个知识源的结果。
知识源通常运行在两个抽象层级。如果知识源实现的是正向推理,将把解转换为上一个层级的解;进行反向推理的知识源在下一个层级寻找证据,如果找不到证据,可能退回到上一层级的解。
- 类
- 黑板
- 职责
- 管理中央数据
-
协作者
- 类
- 知识源
- 职责
- 评估自己的适用性
- 计算结果
- 更新黑板
- 协作者
- 黑板
每个知识源都负责判断自己在什么情况下可帮助找到解,因此知识源分为条件部分和行动部分。条件部分对求解过程的当前状态(写在黑板上)进行评估,以判断自己能否助一臂之力。行动部分生成结果,可能导致黑板的内容发生变化。
控制组件运行一个监视黑板内容变化的循环,并决定接下来采取什么措施。它根据知识运用策略决定激活哪个知识源,让它发起评估。这种策略的依据是黑板上的数据。
该策略可能依赖于控制知识源,这些特殊的知识源不直接参与求解,而执行为控制决策提供依据的计算。他们的典型任务包括估算可能取得的进展以及知识源的计算开销。他们的计算结果为控制数据,也被写到黑板上。
- 类
- 控制
- 职责
- 监视黑板
- 安排知识源激活
- 协作者
- 黑板
- 知识源
从理论上说,黑板可能处于任何知识源都不适用的状态。在这种情况下,系统将无法提供结果。实际上,更可能出现的情形是,每个推理步骤都提出了多个新推测,导致接下来可采取的步骤猛增。因此,要解决的问题是限制备选方案的数量,而不是找到适用的知识源。
控制组件中有一个特殊的知识源或过程,它负责决定系统在什么情况下该停止以及最终结果是什么样的。在找到可接受的解或者系统的时间或空间资源已经耗尽时,系统将停止。
动态
- 控制组件的主循环启动。
- 控制组件调用过程 nextSource()选择下一个知识源。
- nextSource()首先查看黑板,判断哪些知识源可能会提供帮助。
- nextSource()调用每个知识源的条件部分,知识源判断自己在当前状态下能否提供帮助以及如何提供帮助。
- 控制组件选择要调用的知识源以及一个或一组要处理的推测。
实现
- 定义问题
- 确定问题域以及为找到解所需的知识领域。
- 仔细研究系统的输入,找出输入的所有特点。
- 定义系统的输出,确定为确保输出规范而可靠应满足的需求。
- 详细描述用户如何与系统交互。
- 定义问题的解空间 我们将解分为中间解和顶级解,还将其分为部分解和完整解。需要执行如下步骤
- 指出顶级解由哪些内容组成
- 列出解的各种抽象层级
- 将解组织成一个或多个抽象层次结构
- 找出完整解中可独立处理的部分,如词组中的单词、图片或区域的各个部分
- 将求解过程分为如下步骤:
- 定义如何将解转换为上一层级的解
- 描绘如何作出同一抽象层级的推测
- 详细说明如何从其他层级寻找证据,以证实作出的推测
- 指出可以利用什么样的知识将部分解空间排除在外
-
根据子任务将知识划分为专业知识源。
-
定义黑板的词表。 细化最初的解空间和解抽象层级定义,找到解的一种表示方式,让所有知识源都能读写黑板,必要时提供在黑板和知识源内部表示之间进行转换的组件。
-
规范系统的控制机制。 我们的目标是找到解空间中可信度最高的顶级完整解。
制定良好的控制策略是系统设计中最难的一项工作,常常要经历繁琐的流程,尝试多种机制和子策略。在这种情况下,Strategy 模式有助于方便地更换(甚至在运行阶段更换)控制策略。
下述机制可以优化知识源评估,让控制策略更有效、性能更高。
- 将黑板内容变化分为两类,一类可能新增一组适用的知识源,另一类不会。发生第二类变化时,控制组件不会再次调用所有知识源的条件部分,而直接选择一个知识源。
- 将每个黑板内容变化类别与另一组可能适用的知识源关联起来。
- 控制聚焦(focusing of control)。焦点要么包含接下来应处理的黑板上的部分结果,要么包含应优先考虑的知识源。
- 创建一个队列,适用的知识源在其中等待执行。
下面是一些可供控制策略使用的经验法则。
- 排列适用知识源的优先顺序。
- 优先考虑低层级或高层级的推测。
- 优先考虑对应于问题较大部分的推测。
- 岛屿驱动(island driving)。这种策略假设特定推测是合意的一部分,并将其视为一个”确定性岛屿”,从而优先激活处理该推测的知识源,这样就无序不断搜索优先级更高的替代推测了。
-
实现知识源。 根据控制组件的需求,将知识源划分为条件部分和行动部分。为确保知识源的独立性和可更换性,不要对其他知识源和控制组件做任何假设。 对于同一个系统的不同知识源,可使用不同的技术来实现。例如,一个知识源可能是基于规则的系统,另一个可能使用神经网络,第三个可能使用一组传统函数。
变种
- Production System(产生式系统)。
- Repository(仓库)。
已知应用
- HEARSAY-II。20 世纪 70 年代推出的语音识别系统。
- HASP/SIAP。用于发现敌方潜艇。
- CRYSALIS。用于根据 X 射线衍射数据推断蛋白质分子的三维结构。
- TRICERO。用于监视飞行器的活动。
- SUS。Software Understanding System (软件理解系统),旨在帮助理解软件及寻找可重用的资产,通过将模式库中的模式与被分析的系统进行比较,逐渐生成一副可供用户查看的”模式地图”(pattern map)。
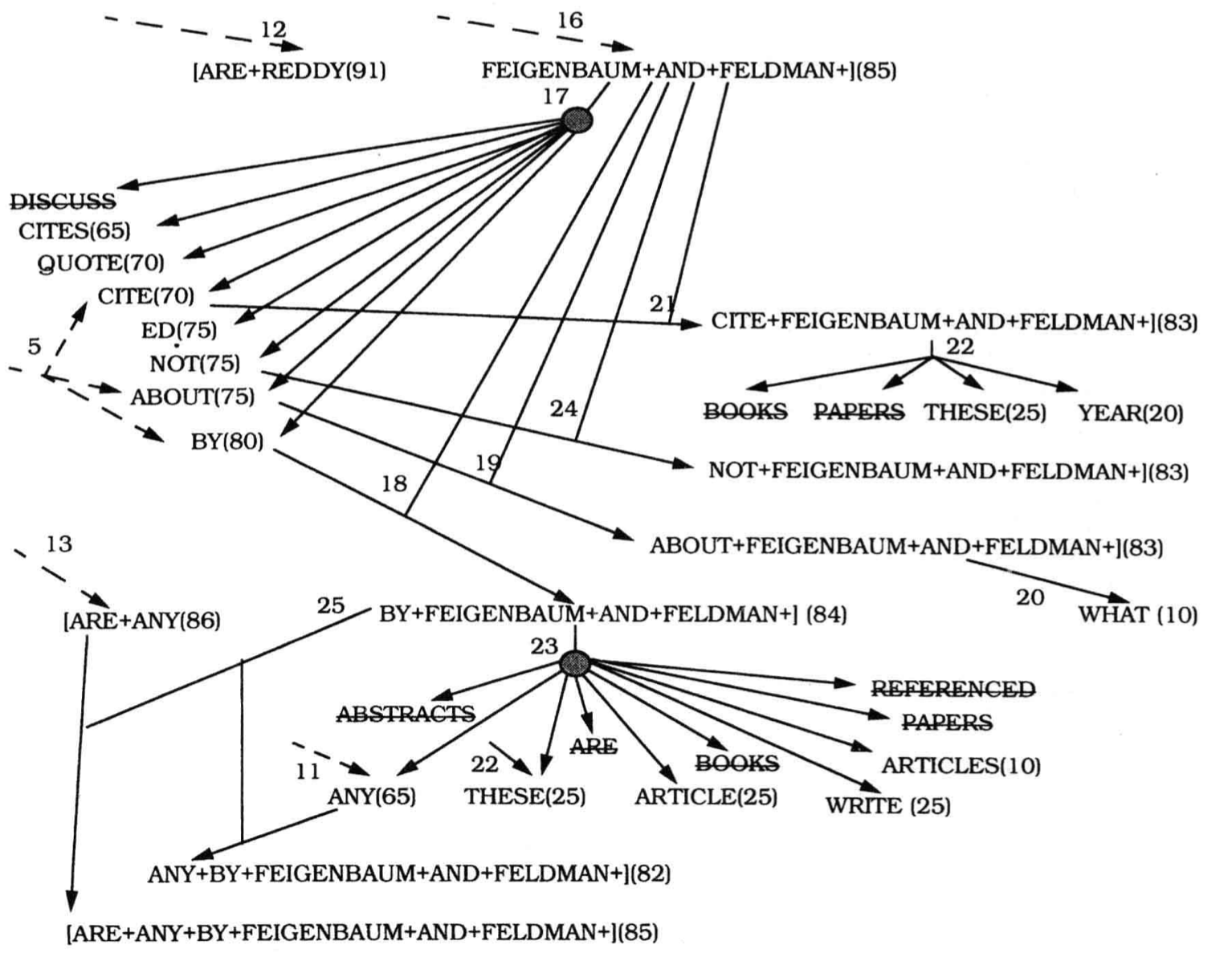
示例解答
此图为 HEARSAY-II 理解词组”Are any by Feigenbaum and Feldman?” 执行的步骤的简化版本。
效果
- 优点
- 可以试验。可以试验不同的算法、尝试不同的控制经验法则。
- 有助于提高可修改性和可维护性。
- 知识源可重用。
- 可提高容错能力和健壮性。
- 缺点
- 难以测试。结果常常不可重现。
- 不保证提供满意的解。
- 难以制定上好的控制策略。
- 效率低。在没有确定算法的情况下,效率低下胜过无能为力。
- 开发工作量大。大多数 Blackboard 系统都需要经过数年才能发展成熟。原因包括下面两个:问题领域不明确;为确定词表、控制策略和知识源,需要做大量的试错性编程工作。
- 不支持并行性。
3. 分布式系统
单机多 CPU、计算机网络化,是量大硬件技术发展趋势。
分布式系统有如下优点:
- 经济实惠。相比于大型机性价比高。
- 性能和扩展性
- 固有的分布性
- 可靠性
然而相比集中式系统,分布式系统对软件的要求截然不同。
有三个分布式架构模式:Pipes and Filters、Microkernel、Broker,下面将介绍 Broker。
Broker
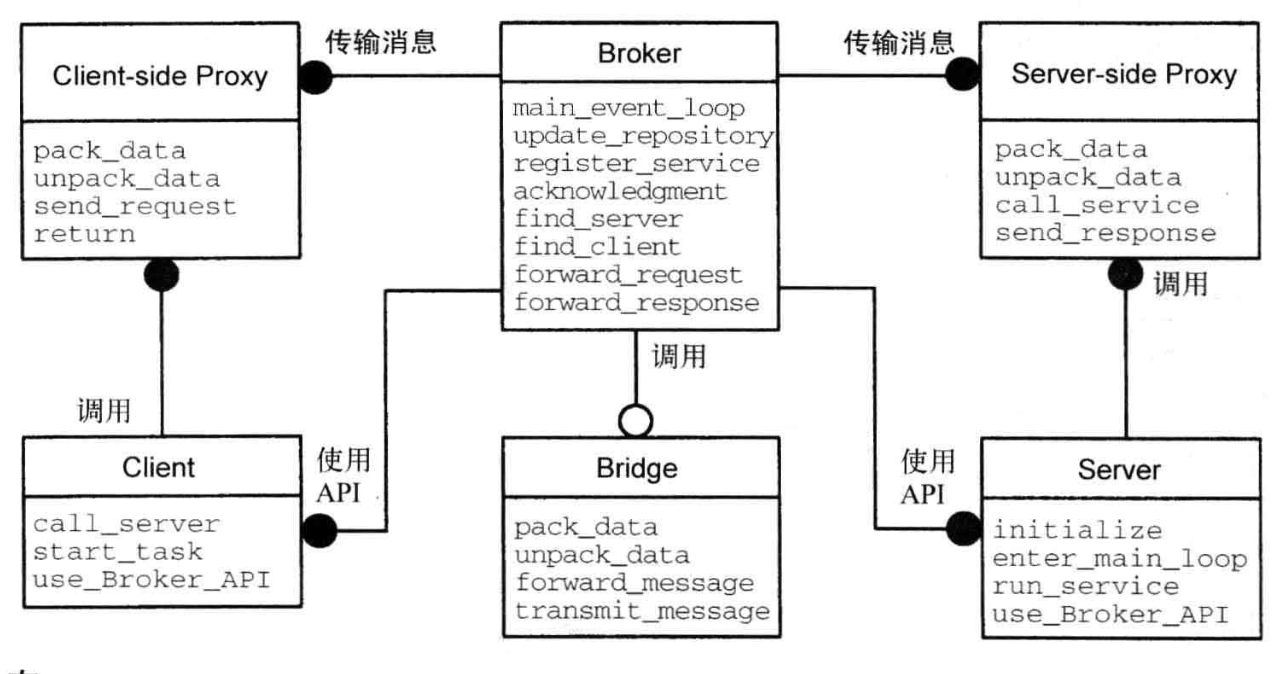 Broker 架构模式可用于设计这样的分布式软件系统,即包含通过远程服务调用交互的组件。一个中间人组件负责协调通信(如转发请求)以及传递结果和异常。
Broker 架构模式可用于设计这样的分布式软件系统,即包含通过远程服务调用交互的组件。一个中间人组件负责协调通信(如转发请求)以及传递结果和异常。
示例
一个运行在广域网上的 CIS(City Inofomation System),提供餐馆、酒店、历史遗址或公共交通方面的信息。
背景
分布式异构系统,其中的组件彼此独立又相互协作。
问题
使用 Broker 可平衡如下作用力:
- 组件能够通过位置透明的远程服务调用访问其他组件提供的服务;
- 能够在运行阶段更换、添加或删除组件;
- 对组件和服务的用户隐藏与系统和实现相关的细节。
解决方案
引入一个中间人组件,以降低客户端和服务器之间的耦合度。服务器向中间人注册,让客户端能够通过方法接口访问其服务。客户端通过中间人发送请求,以访问服务器的功能。中间人的任务包括找到合适的服务器、将请求转发给服务器以及将结果和异常传回给客户端。
因为对开发人员隐藏了分布性,Broker 模式降低了分布式应用程序的复杂度。这是通过引入一种对象模型实现的,这种对象模型将分布式服务封装在对象中。因此,Broker 系统可以集成两种核心技术:分布式技术和对象技术。
结构
Broker 模式包含 6 类组件:客户端、服务器、中间人(broker)、网桥(bridge)、客户端代理(client-side proxy)和服务器端代理
服务器(server)实现了一些对象,这些对象通过由操作和属性组成的接口暴露其功能。通过接口定义语言(IDL)或二进制标准来提供这些接口。服务器分为两类:
- 向众多应用领域提供通用服务的服务器
- 实现特定功能,供单个应用领域或任务使用的服务器
客户端(client)是这样的应用程序,即它至少访问一个服务器的服务。为调用远程服务,客户端将请求转发给中间人。请求执行完毕后,客户端将从中间人那里收到响应或异常。
- 类
- 客户端
- 职责
- 实现用户功能
- 通过客户端代理向服务器发送请求
- 协作者
- 客户端代理
- 中间人
- 类
- 服务器
- 职责
- 实现服务
- 想本地中间人注册
- 通过服务端代理向客户端发送响应和异常
- 协作者
- 服务器端代理
- 中间人
中间人(broker)相当于信使,负责将来自客户端的请求传输给服务器以及将响应和异常传回客户端。中间人必须有办法根据唯一的系统标识符找到请求的接收方。中间人向客户端和服务器提供 API,包括用于注册服务器和调用服务器方法的 API。
- 类
- 中间人
- 职责
- 注册/注销服务器
- 提供 API
- 传输消息
- 错误恢复
- 通过网桥与其他中间人互操作
- 查找服务器
- 协作者
- 客户端
- 服务器
- 客户端代理
- 服务器端代理
- 网桥
- 类
- 客户端代理
- 职责
- 封装系统特定的功能
- 在客户端和中间人之间居中调停
- 协作者
- 客户端
- 中间人
- 类
- 服务器端代理
- 职责
- 调用服务器的服务
- 封装系统特定的功能
- 在服务器和中间人之间居中调停
- 协作者
- 服务器
- 中间人
网桥(bridge)是可选组件,它在两个中间人互操作时隐藏实现细节。如果 Broker 系统运行在异构网络中,通过网络传输请求时,不同中间人必须能够独立于网络和操作系统进行通信。网桥封装了所有这些与系统相关的细节。
- 类
- 网桥
- 职责
- 封装网络特定的功能
- 在本地中间人和远程中间人的网桥之间居中调停
- 协作者
- 中间人
- 网桥
动态
- 情景 1 服务器向本地中间人组件注册
- 情景 2 客户端向本地服务器发送请求
- 情景 3 不同中间人通过网桥组件交互
实现
- 定义对象模型或使用现有模型。
- 决定系统应提供什么样的组件互操作性。
- 指定中间人组件应向客户端和服务器提供的 API。
- 使用代理对象对客户端和服务器隐藏实现细节。
- 设计中间人组件,这是与 3 和 4 同时进行的。
- 开发 IDL 编译器。
示例解答
无
变种
Direct Communication Broker System。出于效率考虑,有时可能放松客户端只能通过本地中间人发送请求的限制。在这个变种中,客户端可直接与服务器通信。中间人将服务器提供的通信渠道告知客户端,这样客户端就能建立到服务器的直接链路。在这种系统中,代理接替中间人负责大多数通信任务。
Message Passing Broker System。这个变种适用于专注数据传输(而非实现远程调用的抽象)的系统。
Trader System。客户端请求通常被转发给一台唯一标识的服务器。在有些情况下,客户端的目标是将请求发送给服务而非服务器。此时,客户端代理使用服务标识符(而不是服务器标识符)来访问服务器的功能。同一个请求可能被转发给多个实现了所需服务的服务器。
Adapter Broker System。为提高灵活性,可再添加一层,以便对服务器隐藏中间人组件的接口。这个适配器是中间人的一部分,负责注册服务器以及与服务器交互。
Callback Broker System。在主动通信模型中,客户端发出请求,服务器执行请求。也可以使用被动模型(reactive model)。被动模型是事件驱动的,没有客户端和服务器之分。事件发生时,中间人调用这种组件的回调方法,即它通过注册指出自己将对这种事件作出响应。
已知应用
-
CORBA 对象管理组织(OMG)定义的 CORBA(通用对象请求代理架构)规范采用了 Broker 架构模式。
-
Microsoft OLE 定义了一种暴露和访问服务器接口的二进制标准。
-
万维网(World Wide Web)
效果
- 优点
- 位置透明性
- 组件的可修改性和可扩展性
- 可移植性
- 不同 Broker 系统之间的互操作性
- 可重用性
- 缺点
- 效率不高
- 容错性差
- 测试和调试困难
参考
Forwarder-Receiver 模式相比 Broker 模式,实现起来更简单,但灵活性差一些。
Proxy 模式的一个远程(remote)变种。
Client-Dispatcher-Server 模式。
Mediator 设计模式,这种模式将对象之间的全互联拓扑变成星型拓扑。
4. 交互式系统
Model-View-Controller
Model-View-Controller(MVC)架构模式将交互式应用程序划分为三种组件:包含核心功能和数据的模型(Model)、向用户显示信息的试图(View)以及处理用户输入的控制器(Controller)。视图和控制器一起组成用户界面,变更传播机制确保用户界面和模型一致。
示例
一个用比例代表政治选举的简单信息系统。用户通过徒刑界面与系统交互,投票数据发生变化后,必须马上在所有显示结果中反映出来。
背景
人机交互界面灵活的交互式应用程序。
问题
作用力如下:
- 在不同的窗口(如柱状图和饼图)中,以不同的方式显示相同的信息
- 数据发生变化后,必须马上在应用程序的显示结果和行为中反映出来
- 可轻松修改用户界面,甚至在运行阶段都能修改
- 支持不同的外观标准,移植用户界面不影响应用程序核心的代码
解决方案
模型组件封装了核心数据和功能,独立于输出的表示方式和输入行为。
视图组件向用户显示信息,并从模型中获取数据。同一个模型可以有多个不同的视图。
每个视图都有相关联的控制器组件。控制器接收输入,这通常是表示鼠标移动、单机鼠标按钮或键盘输入的事件。
结构
模型组件包含应用程序的功能核心,它封装了合适的数据,并暴露了执行应用程序特定处理的过程,而控制器代表用户调用这些过程。模型还提供了用于访问其数据的函数,供视图组件获取要显示的数据。
变更传播机制在模型中维护了一个注册表,其中列出了依赖于模型的组件。所有视图及部分控制器都通过注册指出发生哪些变化时应通知它们。模型的状态发生变化时,将触发变更传播机制。变更传播机制是模型与视图和控制器联系的唯一渠道。
- 类
- 模型
- 职责
- 提供应用程序的功能核心
- 注册依赖于它的视图和控制器
- 数据发生变化后通知依赖于它的组件
- 协作者
- 视图
- 控制器
视图组件向用户显示信息。不同的视图以不同方式显示模型中的数据,每个视图都定义了一个更新过程,该过程由变更传播机制激活。更新过程被调用时,视图从模型获取要显示的最新数据,并显示到屏幕上。
控制器接收用户事件表示的用户输入。如何将这些事件传递给控制器取决于用户界面平台,事件被转换为向模型或相关联的视图发出的请求。
如果控制器的行为依赖于模型的状态,它将向变更传播机制注册,并实现一个更新过程。
- 类
- 视图
- 职责
- 创建并初始化相关联的控制器
- 向用户显示信息
- 实现更新过程
- 从模型那里获取数据
- 类
- 控制器
- 职责
- 接收用事件表示的用户输入
- 将事件转换为向模型(视图)发出的服务请求(显示请求)
- 必要时实现更新过程
- 协作者
- 视图
- 模型
动态
- 情景 1 用户输入导致模型发生变化,进而触发变更传播机制
- 情景 2 初始化 MVC 模式中的组件。这种代码通常不在模型、视图和控制器中,例如,可能位于主程序中。每次打开模型的视图都将以类似的方式初始化视图和控制器。
实现
第 1 ~ 6 步是编写基于 MVC 的应用程序的基本步骤,第 7 ~ 10 步是可选的,可提高灵活性,适合用于打造高度灵活的应用程序或应用程序框架。
- 将人机交互与核心功能分离
- 实现变更传播机制。Observer 模式(这里叫 Publisher-Subscriber 设计模式)
- 设计并实现视图
- 设计并实现控制器
- 设计并实现视图-控制器关系
- 实现搭建 MVC 的代码
- 动态地创建视图。 如果应用程序允许动态地打开和关闭视图,最好提供一个负责对打开的视图进行管理的组件。该组件还可负责在最后一个视图关闭后终止应用程序。要实现这种管理组件,可使用 View Handler 设计模式。
- “可插入式”控制器。通过将控制方面与视图分离,可将视图与不同的控制器组合。可以利用这种灵活性实现不同的运行模式(如供新用户和专家级用户使用的模式)。
- 创建视图和控制器层次结构。
- 进一步降低系统的依赖性
变种
Document-View。这个变种没有将视图和控制器分离。Document-View 的文档组件和视图组件之间是松耦合的,让一个文档可以同时有多个同步的视图。
已知应用
- Smalltalk
- MFC,Microsoft Foundation Class Library(基础类库)使用了 Document-View
效果
- 优点
- 一个模型可以有多个视图
- 视图同步
- “可插入的”视图和控制器
- 可更换外观
- 可开发框架
- 缺点
- 更复杂
- 更新可能过度频繁
- 视图和控制器联系紧密
- 视图和控制器与模型紧耦合
- 视图的数据访问效率低下
- 移植时必须修改视图和控制器
- 使用较新的用户界面工具时难以遵循 MVC
参考
Presentation-Abstraction-Control 模式采用不同的方法将系统的用户界面与功能核心分离,其抽象组件相当于 MVC 模型组件,表示组件将 MVC 视图和控制器组件合二为一,而控制器组件负责协调抽象组件和表示组件之间的通信。在 Presentation-Abstraction-Control 模式中,表示组件和抽象组件之间的交互不像 MVC 那样仅限于调用更新过程。
PS: 感觉 PAC 模式就像 MVVM 模式的功能。
Presentation-Abstraction-Control 模式
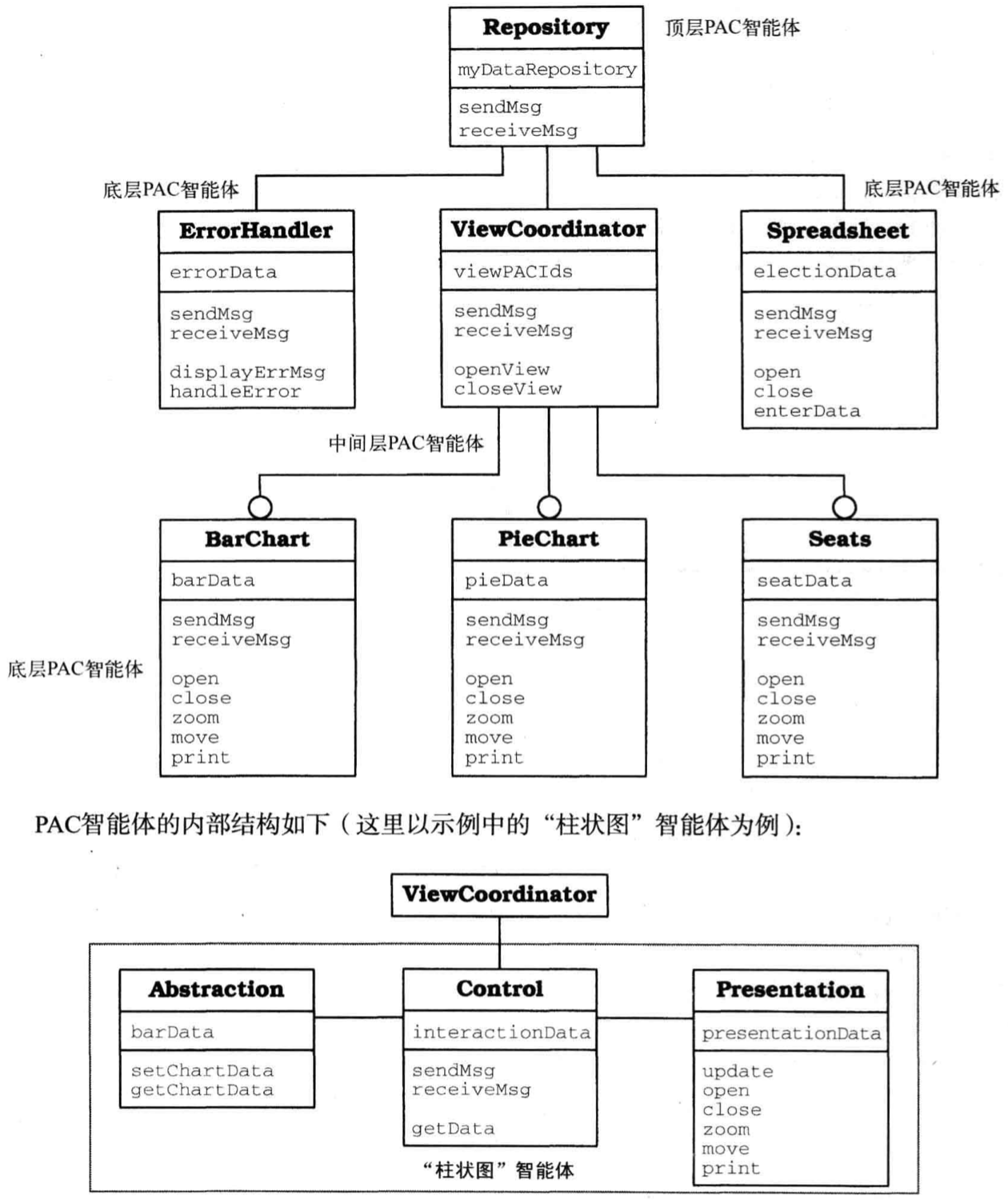 架构模式 Presentation-Abstraction-Control(PAC)定义了一种适用于交互式软件系统的结构——由相互协作的智能体组成的层次结构。每个智能体都负责应用程序功能的特定方面,并包含三个组件:表示组件、抽象组件和控制组件,这将智能体的人机交互方面功能能够核心和通信方面分离了。
架构模式 Presentation-Abstraction-Control(PAC)定义了一种适用于交互式软件系统的结构——由相互协作的智能体组成的层次结构。每个智能体都负责应用程序功能的特定方面,并包含三个组件:表示组件、抽象组件和控制组件,这将智能体的人机交互方面功能能够核心和通信方面分离了。
示例
一个用比例代表政治选举的简单信息系统。
背景
利用智能体开发交互式应用程序。
- 智能体(agent)指的是信息处理组件,包含事件接收器、维护状态的数据结构和处理器(processor),其中处理器负责处理到来的事件及更新状态,还可能触发新事件。
问题
交互式系统常常可视为一组相互协作的智能体。可能的作用力如下:
- 智能体通常维护自己的状态的数据。为了完成整个应用程序面临的任务,各个智能体必须有效地协作。为此,它们需要一种交换数据、消息和事件的机制。
- 每个智能体的人机交互方面的大不相同,需要提供自己的用户界面。
- 系统随事件的推移不断发展变化,表示方面尤其如此。
解决方案
将交互式应用程序设计成由 PAC 智能体组成的树形结构,其中包含一个顶层智能体、多个中间层智能体和数目众多的底层智能体。每个智能体负责应用程序的特定方面,并由三个组件组成:表示组件、抽象组件和控制组件。
表示组件提供了 PAC 智能体的可视化行为;抽象组件维护智能体的底层数据模型,并提供操作这些数据的功能;控制组件是表示组件和抽象组件之间的桥梁,并提供了让智能体能够与其他 PAC 智能体通信的功能。
顶层 PAC 智能体提供了系统的功能核心,其他大部分 PAC 智能体都依赖或操作这个核心。另外,顶层 PAC 智能体还包含不属于特定子任务的用户界面,如菜单栏、显示应用程序信息的对话框等。
底层 PAC 智能体表示用户可操作的独立语义概念,如电子表格和图表。底层智能体向用户呈现这些概念,并支持用户可对这些智能体执行所有操作,如缩放或移动图表。
中间层 PAC 智能体表示下一层智能体的组合或它们之间的关系,例如,中间层智能体可能维护相同数据的多个视图,如建筑 CAD 系统中的房屋平面图和外观图。
结构
- 类
- 顶层智能体
- 职责
- 提供系统的功能核心
- 控制 PAC 层次结构
- 协作者
- 中间层智能体
- 底层智能体
- 类
- 中间层智能体
- 职责
- 协调下一层 PAC 智能体
- 将下一层 PAC 智能体组合成抽象程度更高的单元
- 协作者
- 顶层智能体
- 中间层智能体
- 底层智能体
- 类
- 底层智能体
- 职责
- 提供软件的特定视图或系统服务,包括相关联的人机交互
- 协作者
- 顶层智能体
- 中间层智能体
动态
- 情景 1 打开新的选举数据柱状图视图时。
- 情景 2 用户在电子表格输入新数据时。
实现
- 定义应用程序模型
- 制定 PAC 层次结构的总体组织策略
- 确定顶层 PAC 智能体 在分析模型中,找出表示系统功能核心的部分,这主要是维护系统全局数据模型的组件以及直接操作这些数据的组件。另外,找出在整个应用程序中都通用的用户界面元素,如菜单栏及显示系统信息的对话框。这一步找到的所有组件都将是顶层智能体的一部分。
- 确定底层 PAC 智能体。 在分析模型中找出这样的组件:表示系统最小的独立单元,且用户可对其进行操作或查看。
- 确定提供系统服务的底层 PAC 智能体。
- 确定用于组合下一层 PAC 智能体的中间层 PAC 智能体。
- 确定用于协调底层智能体的中间层 PAC 智能体。
- 将核心功能与人机交互分离。
- 提供外部接口。
- 连接成层次结构
变种
-
PAC 智能体为主动对象
-
PAC 智能体为进程
已知应用
- 网络流量管理(Network Traffic Management)
- 移动机器人(Mobile Robot)
效果
- 优点
- 分离关注点
- 支持修改和扩展
- 支持多任务
- 缺点
- 系统更复杂 请务必仔细考虑设计的层级粒度,决定在什么情况下不再将智能体细化为更多的底层智能体。
- 复杂的控制组件
- 效率 PAC 智能体之间的通信开销可能影响系统的效率。
- 适用性 应用程序中不可分割的语义概念越小、这些语义概念的用户界面越相似,这个模式就越不适用。另一方面,如果不可分割的语义概念很大,且需要自己的人机交互,PAC 将提供一种易于维护和扩展的结构,并完全分离不同系统任务的关注点。
参考
MVC 模式
5. 可适应系统
Microkernel
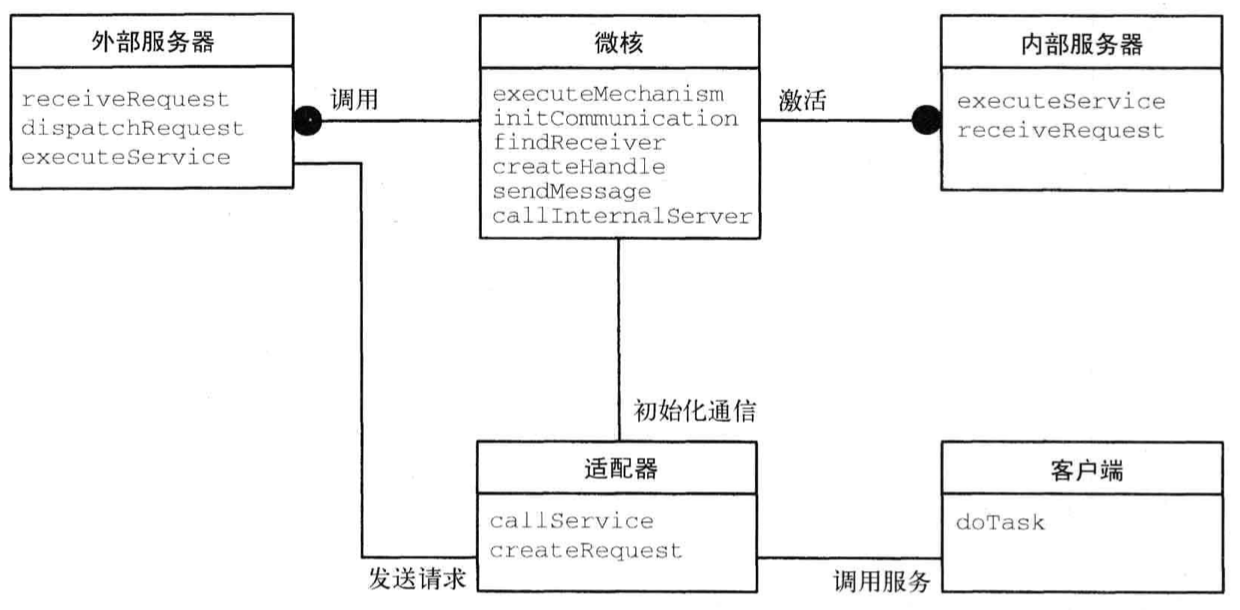 架构模式 Microkernel 适用于必须能够适应不断变化的需求的系统,他将最基本的功能核心与扩展的功能和随客户而异的部分分离。微核还充当插座,用于插入扩展及协调它们之间的协作。
架构模式 Microkernel 适用于必须能够适应不断变化的需求的系统,他将最基本的功能核心与扩展的功能和随客户而异的部分分离。微核还充当插座,用于插入扩展及协调它们之间的协作。
示例
一个新的台式机操作系统 Hydra,能够轻松的移植到相关的硬件平台,能够轻松的适应未来的发展。
背景
使用依赖于相同核心功能的编程接口开发多个应用程序。
问题
有些应用领域需要应对大量类似的标准和技术,例如操作系统和图形用户界面等应用程序平台。这种系统的使用寿命通常很长,有时达 10 年甚至更长。在此期间,新技术会出现,旧技术会改变。需关注下述作用力:
- 应用程序平台必须应对硬件和软件的持续发展
- 应用程序平台必须可移植、可扩展、可适应,这样才能轻松地集成新兴技术
这种应用程序平台还需要能运行既有标准编写的应用程序。为支持范围广泛的应用程序,需要应用程序平台底层功能的多个视图。例如,Hydra 被设计成能够运行为 Microsoft Windows 和 OS/2 Warp 等流行操作系统开发的应用程序。这带来如下作用力:
- 你所属领域的应用程序需要支持不同但类似的应用程序平台
- 多个应用程序可能以不同的方式使用相同的功能核心,这要求底层应用程序平台模拟既有标准。
- 将应用程序平台的功能核心分为一个组件和一系列服务,并确保这个组件占用的内存尽可能少,而服务占用的处理时间尽可能少。。
解决方案
将应用程序平台的基本服务封装到微核组件中。微核包含让运行在不同进程中的其他组件能够互相通信的功能,它还负责维护系统级资源,如文件和进程。另外,它还提供了让其他组件能够访问其功能的接口。 外部服务器实现了底层微核的视图,它们使用微核通过接口暴露的机制来创建这种视图。每个外部服务器都是一个独立进程,该进程本身就是一个应用程序平台,因此可将 Microkernel 系统视为集成了其他应用程序平台的应用程序平台。 客户端使用微核提供的通信工具与外部服务器通信。
结构
微核实现了不可分割的服务,我们将这些服务称之为机制。这些机制相当于根基,更复杂的功能(我们称之为策略,policy)建立在它们的基础上。
- 类
- 微核
- 职责
- 提供核心机制
- 提供通信工具
- 封装系统细节
- 管理和控制资源
- 协作者
- 内部服务器
内部服务器(也叫子系统)扩展了内核提供的功能,是一个提供额外功能的独立组件。微核通过服务请求调用内部服务器的功能,因此内部服务器可封装一些与底层硬件或软件系统相关的细节。例如,支持特定显卡的设备驱动程序就非常适合作为内部服务器。
- 类
- 内部服务器
- 职责
- 实现额外的服务
- 封装一些系统细节
- 协作者
- 微核
外部服务器(也叫个性,personality)是使用微核实现其底层应用领域视图的组件。前面说过,视图是抽象层,建立在微核提供的不可分割的服务的基础上。不同外部服务器为特定应用领域实现了不同的策略。
- 类
- 外部服务器
- 职责
- 向客户端提供编程接口
- 协作者
- 微核
客户端是与单个外部服务器相关联的应用程序,它只访问外部服务器的编程接口。
- 类
- 客户端
- 职责
- 表示应用程序
- 协作者
- 适配器
如果客户端需要直接访问其外部服务器的接口,那么每个客户端都得使用可用的通信工具与外部服务器互操作,与外部服务器的所有通信都是硬编码的方式实现的。会引起如下缺点:
- 可修改性不佳
-
如果外部服务器模拟的是既有应用程序的平台,为这些平台编写的客户端应用程序必须修改才能运行 因此,需要引入适配器。适配器位于客户端的地址空间内。
- 类
- 适配器
- 职责
- 对客户端隐藏系统细节,如通信工具
- 代表客户端调用外部服务器的方法
- 协作者
- 外部服务器
- 微核
动态
- 情景 1 客户端调用其外部服务器的服务是,Microkernel 架构的动态行为。
- 情景 2 这个情景说明了外部服务器请求内部服务器提供的服务时,Microkernel 架构的动态行为。
实现
- 分析应用领域
- 分析外部服务器
- 将服务分类
- 划分类别
- 对于第 1 步确定的每种类别,找出其完整的操作和抽象集。
- 确定请求传输策略,同步、异步
- 确定微核组件的结构
如果可能,使用 Layers 模式来设计微核,将微核中与系统相关的部分独立于系统的部分分开。可以用面向对象技术来实现微核:
- 最底层包含低级对象,它们对微核的其他部分隐藏了总线架构等硬件细节;
- 在中间层,主要服务都由系统对象(如负责内存管理的对象以及用于管理进程的对象)提供;
- 最顶层包含微核向外暴露的所有功能,是所有进程访问微核服务的入口。
- 确定微核的编程接口
- 微核负责管理所有的系统资源
- 将内部服务器设计并实现为独立进程或共享库
- 将主动服务器实现为进程
- 将被动服务器实现为共享库
- 实现外部服务器 每个外部服务器都被实现为独立进程,并提供了服务接口。
- 实现适配器。
每当客户端调用外部服务器的函数时,适配器都将所有相关的信息打包成请求,再将请求转发给合适的外部服务器。然后,适配器等待服务器作出响应,并最终将控制权交还给客户端,这是使用组件间通信工具完成的。
可将适配器视为一个外部服务器的代理,因此可使用 Proxy 模式来实现。可采取下述方式优化适配器:
- 让它独自执行某些 API 操作,而不是将所有请求都转发给外部服务器;
- 将客户端请求存储在缓存中,等缓存多个请求后再转发;
- 在适配器中存储常见请求的响应。
- 为准备就绪的 Microkernel 系统开发客户端应用程序或使用现成的客户端应用程序
示例解答
变种
- Microkernel System with indirect Client-Server connections(客户端和服务器不直接通信的微核系统)。
- Distributed Microkernel System(分布式微核系统)。
已知应用
- 操作系统 Mach
- Windows NT
效果
- 优点
- 可移植性
Microkernel 系统的可移植性极高,原因有两个:
- 将 Microkernel 系统移植到新的软件或硬件环境时,大多数情况下无需移植外部服务器和客户端应用程序
- 将微核迁移到新的硬件环境时,只需修改与硬件相关的部分
- 灵活性和可扩展性
- 策略与机制分离
- 其变种 Distributed Microkernel 模式还有如下优点:
- 可伸缩性
- 可靠性
- 透明性
- 可移植性
Microkernel 系统的可移植性极高,原因有两个:
- 缺点
- 性能低 虽然会比提供特定视图的软件系统性能低,但是通过优化 Microkernel 系统的内部通信以提高性能,这种代价几乎可以忽略不计。
- 设计和实现复杂 工作量较大,有时很难分析或预知微核组件必须提供的基本机制。需要有丰富的领域知识,并在需求分析和设计阶段做大量工作。
参考
- Broker 模式适合于分布式软件系统,可以与 Distributed Microkernel 系统相结合。
- Reflection 模式提供了一种两层架构,其中基层相当于微核和内部服务器,元层让你能够动态地改变基层功能的行为,如调整资源管理和组件通信策略。
- Microkernel 系统可以被视为 Layers 模式的变种。
Reflaction
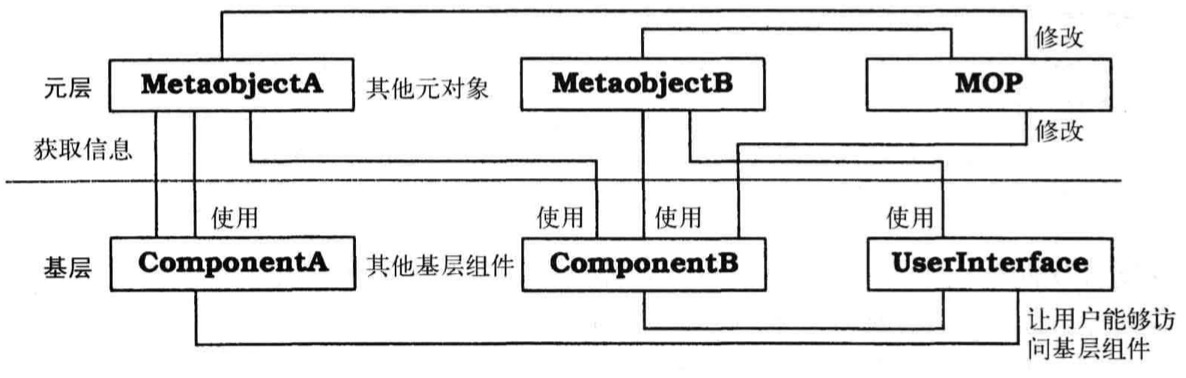 Reflaction 架构模式提供了一种动态地修改软件系统的结构和行为的机制。它支持对基本方面(如类型结构和函数调用机制)进行修改。采用这个模式时,应用程序分为两部分:元层和基层。元层提供有关选定系统属性的信息,让软件能够了解自己;基层包含应用程序逻辑,其实现依赖于元层,修改元层存储的信息将影响基层的行为。
Reflaction 架构模式提供了一种动态地修改软件系统的结构和行为的机制。它支持对基本方面(如类型结构和函数调用机制)进行修改。采用这个模式时,应用程序分为两部分:元层和基层。元层提供有关选定系统属性的信息,让软件能够了解自己;基层包含应用程序逻辑,其实现依赖于元层,修改元层存储的信息将影响基层的行为。
别名
- Open Implementation(开放实现模式)
- Meta-Level Architecture(元层架构模式)
示例
一个 C++程序,需要将 C++对象写入磁盘并从磁盘读取它们。由于 C++并没有内置持久化功能,我们必须在应用程序中指定如何存储和读取每种类型的对象。如果每种数据都实现一个类,这样容易出错、代价太高、每次都要重新编译。
背景
打造天生支持修改的系统。
问题
作用力:
- 修改软件是项繁琐的工作,既容易出错又代价高昂。
- 可适应软件系统的内部结构通常很复杂。
- 确保系统易于修改所需的技术(如参数化、子类化、混合类、复制和粘贴)越多,对系统进行修改时就越麻烦、越复杂。
- 修改规模各不相同,小至为常见命令提供快捷键,大至根据客户需求调整应用程序框架。
- 即便是软件系统的基本方面,如组件间通信机制,也可能需要修改。
解决方案
让软件能够了解自己,并让其结构和行为的某些方面可调整和修改。这要求采用的架构将系统划分为两个主要部分:元层和基层。 元层提供软件的自我表示(self-representation),让软件能够知道自己的结构和行为,它由元对象组成。元对象封装并提供有关软件的信息,这包括类型结构、算法和函数调用机制。 基层定义了应用程序逻辑,其实现使用的是元对象,以免依赖于可能变化的方面。 指定一种用来操作对象的接口,这种接口被称为元对象协议(MOP),让客户端能够指定要做的修改,如修改上述函数调用机制元对象。元对象协议本身负责检查要做的修改是否正确,并执行修改。通过元对象协议对元对象所做的每项修改(如修改函数调用机制),都将影响基层的后续行为。
结构
- 类
- 基层
- 职责
- 实现应用程序逻辑
- 使用元层提供的信息
- 协作者
- 元层
- 类
- 元层
- 职责
- 封装可能变化的系统内部信息
- 提供接口以方便修改元层
- 协作者
- 基层
- 类
- 元对象协议
- 职责
- 提供接口,用于指定要对元层所做的修改
- 执行指定的修改
- 协作者
- 元层
- 基层
不同于分层架构,这两层彼此依赖:基层依赖于元层,元层也依赖于基层。
动态
要全面的描述反射系统的动态行为,几乎是项不可能完成的任务,因为系统自身还在变化。
- 情景 1 读取存储在磁盘文件中的对象时,基层和元层如何协作。
- 情景 2 使用元对象协议在元层添加类型信息。
实现
- 定义应用程序模型。
为了对问题域进行分析,将其分解为合适的软件结构。需回答下述问题:
- 软件应提供哪些服务?
- 哪些组件可执行这些服务?
- 组件之间的关系是什么样的?
- 组件如何协作?
- 组件操作哪些数据?
- 用户将如何与软件交互?
- 找出可能变化的行为。
变化通常发生在系统的下面方面:
- 实时约束,如时间限制、时间界限(time-fence)协议以及检测超过时限的算法。
- 事物协议,如记账系统中的乐观事务控制和悲观事务控制。
- 进程间通信机制,如远程过程调用和共享内存。
- 发生异常时的行为,如实时系统中应对超过时限的方式。
- 应用程序服务算法,如随国家而异的增值税(VAT)计算公式。
- 找出发生变化时,不应影响基层实现的系统结构方面,这包括应用程序的类型结构及其底层数据模型,还有组件在异构网络中的分布情况。
- 找出支持第 2 步应用程序服务可能变化以及独立于第 3 步的结构细节的系统服务。基本服务包括:
- 异常处理
- 资源分配
- 垃圾回收
- 页面交换
- 对象创建
- 定义元对象。
- 定义元对象协议,支持以明确而受控的方式修改和扩展元层,同时支持对基层组件和元对象之间的关系进行修改。
- 定义基层。 根据第 1 步开发的分析模型实现系统的功能核心和用户界面。
示例解答
由于 C++对反射支持力度不大,所以实现时可能会依赖于编译器。
变种
- 包含多个元层的反射 理论上可以形成一个无限反射塔,实际上,大多数现有反射系统都只包含一两个元层。
已知应用
- CLOS 这是一种经典的反射编程语言。
- MIP 这是一个 C++运行阶段类型信息系统,主要用于以自省的方式访问应用程序的类型系统。
- PGen 这是一个基于 MIP 的 C++持久化组件,让应用程序能够存储和读取任何 C++对象结构。
- NEDIS 汽车经销商系统,使用了反射以适应不同客户和国家的需求。
- OLE 2.0 提供了暴露和访问 OLE 对象及其接口的类型信息的功能。
效果
- 优点
- 无需显式地修改源代码
- 修改软件系统轻而易举
- 支持众多不同类型的修改
- 缺点
- 在元层所做的修改可能带来破坏
- 增加了组件数量
- 效率低下
- 并不支持对软件的所有修改
- 并非所有语言都支持反射
参考
Microkernel 架构模式提供了添加新功能或客户特定功能的机制,有助于提高软件的可适应性和可修改性。
第三章 设计模式
设计模式描绘了一种反复出现的结构,可用于组织相互通信的组件,以解决特定背景下普适的设计问题。
PS: 本章介绍了 8 个《设计模式》中没有的设计模式。
1. 导言
设计模式分为几类:
- 结构分解模式 这类模式有助于以恰当的方式将子系统和复杂组件分解为一系列相互协作的部分。最常见的是 Whole-Part,它非常适合组织复杂的组件。
- 工作组织模式 这类模式定义组件如何协作,以解决复杂的问题。我们将介绍 Master-Slave,它可以帮助组织必须能够容错或计算必须精确的服务,还有助于将服务划分为多个部分,这些部分彼此独立,可同时执行。
- 访问控制模式 这类模式监视并控制对服务或组件的访问。我们将介绍其中的 Proxy,借助它,客户端能够与组件的代表(而非组件本身)通信。
- 管理模式 这类模式处理一系列同质对象、服务和组件,我们将介绍其中两个:Command Processor 和 View Handler,其中前者致力于管理和调度用户命令,后者描述了如何管理软件系统中的视图。
- 通信模式 这类模式帮助统筹组件间通信。Forwarder-Receiver 致力于点对点通信,而 Client-Dispatcher-Server 描述了如何在客户端-服务器模型中实现位置透明的通信。
- Publisher-Subscriber 模式有助于确保协作组件的数据一致,与 Observer 模式是一回事。我们会重点介绍其变种 Event Channel。
2. 结构分解模式
Whole-Part
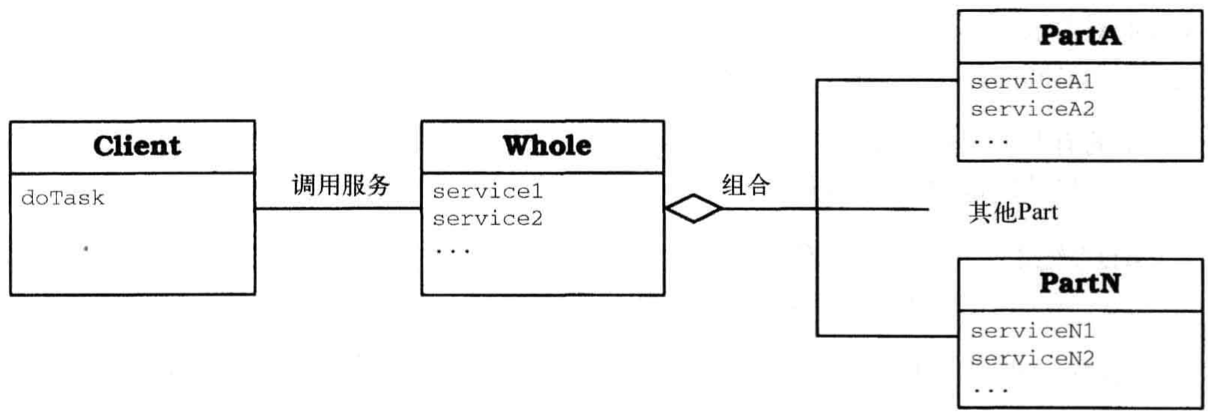 Whole-Part 设计模式有助于将组件聚合成语义整体。聚合组件(Whole)封装组成它的组件(Part),统筹它们之间的协作,并提供访问其功能的通用接口。从外部不能直接访问 Part 组件。
Whole-Part 设计模式有助于将组件聚合成语义整体。聚合组件(Whole)封装组成它的组件(Part),统筹它们之间的协作,并提供访问其功能的通用接口。从外部不能直接访问 Part 组件。
PS: 其实就是面向对象封装的基本用法,组合、聚合。
示例
用于 2D 和 3D 建模的计算机辅助设计(CAD)系统。
背景
实现聚合对象。
问题
模拟组成结构时,要平衡下述作用力:
- 要么使用既有对象组合成复杂对象,要么将复杂对象分解为更小的对象。
- 在客户端看来,聚合对象是个整体,不能直接访问其组成部分。
解决方案
Whole-Part 的基本原则适合用于组织三种关系:
- 总成-零件关系 将产品同其零件(组合件)区分开来,如前述示例中分子与原子之间的关系。所有零件都依照总成的内部结构紧密结合在一起。组合件的数量和类型是预先确定的,始终保持不变。
- 容器-内容关系 在这种关系中,聚合对象为容器。例如邮政包括中可能有不同的东西。这些内容之间的耦合度不像总成-零件关系中的零件之间那么高,可以动态地增删。
- 集合-成员关系 这种关系有助于将类似对象编组,如组织与成员之间的关系。集合提供了诸如遍历成员并对每个成员执行操作等功能。集合不区分其成员,同等对待每个成员。
这些类别定义的是对象(而非数据类型)之间的关系。
结构
- 类
- Whole
- 职责
- 聚合多个小对象
- 提供依赖于 Part 对象的服务
- 充当 Part 的包装器
- 协作者
- Part
- 类
- Part
- 职责
- 表示特定对象及其服务
- 协作者
实现
- 设计 Whole 的共有接口
- 将 Whole 划分为 Part 或使用现有对象来合成它
- 如果采用自下而上的方式,从组件库或类库中选择现有 Part,并确定它们如何协作。
- 如果采用自上而下的方式,将 Whole 的服务划分成相互协作的小服务,而这些服务将对应不同的 Part。
- 使用 Part 的服务来定义 Whole 的服务
- 实现 Part
- 实现 Whole
变种
- Shared Parts(共享部分)
- Composite 模式也采用 Whole-Part 层次结构,但可同等对待 Whole 及其 Part,即 Whole 和 Part 实现了相同的抽象接口
效果
- 优点
- 可修改 Part
- 分离关注点
- 可重用性
- 缺点
- 间接导致效率低下
- 分解为 Part 的工作很复杂
参考
- Composite 模式
- Facade 模式提供一个简单接口,用于访问复杂的子系统。Facade 模式没有将 Part 封装起来,客户端也可以直接访问 Part。
3. 工作组织模式
Master-Slave
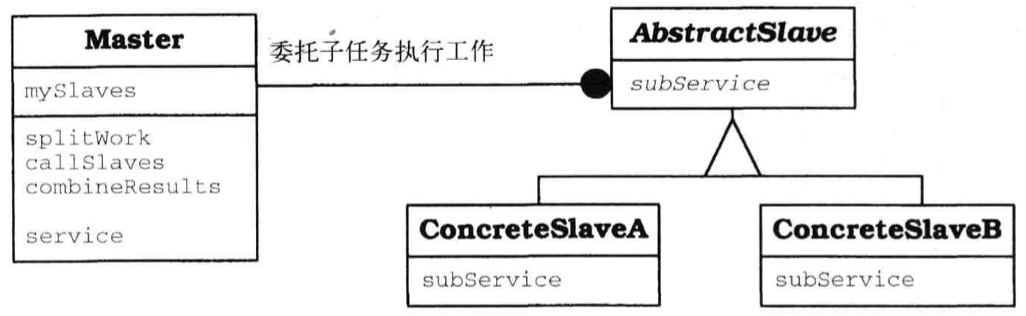 设计模式 Master-Slave 有助于改善容错性以及计算的并行性和准确度。一个主组件将工作分配给多个相同的从组件,并根据这些从组件返回的结果计算最终结果。
设计模式 Master-Slave 有助于改善容错性以及计算的并行性和准确度。一个主组件将工作分配给多个相同的从组件,并根据这些从组件返回的结果计算最终结果。
示例
旅行商问题,由于不可能遍历整个可能性空间,希望同时计算多条路线,取其中较优的一条。各条路线要不同并足够随机。
背景
将工作分为多个语义上等价的子任务。
问题
“分而治之”是解决众多问题的常用策略。实现这种结构时,将面临多个作用力:
- 不应让客户端知道计算是基于”分而治之”策略的
- 无论是客户端还是子任务的处理,都不依赖于划分工作和计算最终结果的算法
- 如果每个子任务的处理方式都不同,但从语义上说又都是等价的,将大有裨益,如提高计算的准确度。
- 有时候(如在使用有限元方法的模拟应用程序中),需要协调子任务的处理
解决方案
在服务的客户端和子任务呢处理之间引入一个协调组件——主组件。 主组件将工作分为多个子任务,将它们委托给多个独立但语义上相同的从组件,并根据从组件返回的部分结果计算最终结果。 这种基本原则适用于三个应用领域:
- 容错 将执行服务的工作委托给多个相同的实现。服务执行失败时,能够发现并采取应对措施。
- 并行计算 将复杂任务均分为数量固定且并行执行的子任务,再利用处理这些子任务得到的结果计算最终结果
- 提高计算的准确度 将执行服务的工作委托给多个相同的实现。结果不准确时,能够发现并采取应对措施。
结构
主组件提供可采取”分而治之”策略来执行的服务。它提供了一个接口,让客户端能够访问这项服务。在内部,主组件实现了用于完成如下任务的函数:将工作均分为多个子任务、启动并控制子任务的处理、根据获得的所有结果计算最终结果。主组件还维护指向所有从组件的引用,并将处理任务的工作委托给这些从组件。在 Master-Slave 结构中,至少又两个从组件实例与主组件相关联。
- 类
- 主组件
- 职责
- 在多个从组件之间分配工作
- 启动从组件
- 根据从组件返回的结果计算最终结果
- 类
- 从组件
- 职责
- 实现供主组件使用的服务
- 协作者
- 无
实现
- 分工
- 合并子任务的结果
- 规范主组件和从组件之间的协作
- 根据前一步制定的规范实现从组件
- 根据第 1~3 步制定的规范实现从组件
变种
Master-Slave 模式的应用领域有三个:
- 用于容错 主组件同时调用多个实例不同而功能相同的从组件,只要有一个从组件成功返回,就能返回给客户端有效结果
- 用于并行计算 将复杂任务划分为多个不同从组件并行执行的子任务,最后由主组件负责同步、结果收集
- 用于提高计算准确度 将执行服务的工作委托给至少三个不同实现,主组件等待所有从组件结束,然后从中选择最优结果
还有下列变种:
- Slaves as Threads(从组件为独立线程) 在这个变种中,每个从组件都运行在独立的控制线程中。主组件创建线程,启动从组件,并等待所有线程结束后执行自己的计算。实现这种结构时,Active Object 模式可助一臂之力。通常线程数比 CPU 数量稍多。
- Master-Slave with slave coordination(从组件需要协调) 从组件执行计算时可能依赖于其他从组件的计算状态,例如执行有限元模拟时,所有从组件必须定期挂起。
已知应用
- 三个并行计算的例子:
- 矩阵乘法
- 图像编码变换
- 计算两个信号的相关性
- 工作池(workpool)
- 对大数进行质因子分解
效果
- 优点
- 可更换性和可扩展性
- 分离关注点
- 效率(并行计算)
- 缺点
- 可行性 由于多个从组件要并行执行,所以会比较消耗处理时间和存储空间
- 依赖于计算机 支持并行计算的时严重依赖于计算机的架构
- 难以实现 必须应对各种错误,如从组件执行失败、主组件和从组件无法通信、无法启动并行从组件。通常必须对目标计算机的架构有相当深入的认识。
- 可移植性 由于依赖于底层硬件架构,可能难以移植
4. 访问控制
Proxy
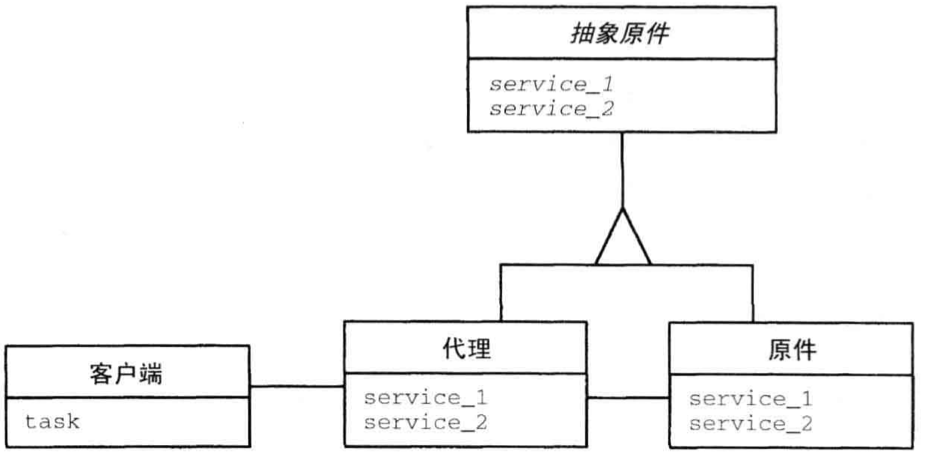 设计模式 Proxy 让客户端与代理而非组件本身通信。引入这样的代理可达成很多目的,如提高效率、简化访问以及禁止未经授权的访问。
设计模式 Proxy 让客户端与代理而非组件本身通信。引入这样的代理可达成很多目的,如提高效率、简化访问以及禁止未经授权的访问。
示例
在访问数据库查询时设置一个代理,对查询进行优化。
背景
客户端需要访问另一个组件提供的服务。直接访问从技术上说可行,但可能不是最佳的方式。
问题
作用力:
- 对客户端和组件来说,访问组件的方式必须高效、划算、安全
- 对客户端来说,对组件的访问必须透明而简单 具体的说,调用行为和语法应与调用直接访问的组件时一样。
- 客户端应深知访问远程服务可能带来的性能和财务开销 完全透明可能导致不同服务的成本差异变得模糊
解决方案
让客户端与代理而非组件本身通信。这个代理提供了组件的接口,但执行额外的预处理和后处理,如访问控制检查或创建原件的只读副本。
结构
- 类
- 客户端
- 职责
- 使用代理提供的接口请求特定服务
- 完成自己的任务
- 协作者
- 代理
- 类
- 抽象原件
- 职责
- 作为代理和原件的抽象基类
- 协作者
- 无
- 类
- 代理
- 职责
- 向客户端提供访问原件的接口
- 确保安全、高效、正确地访问原件
- 协作者
- 原件
- 类
- 原件
- 职责
- 实现特定服务
- 协作者
- 无
动态
- 执行任务期间,客户端请求代理执行一项服务。
- 收到服务请求后,代理对其进行预处理。预处理包括查找原件的地址或检查缓存查看其中是否有请求的信息等操作。
- 如果必须让原件执行请求,代理使用合适的通信协议转发给原件,并采取合适的安全措施。
- 收到请求后,原件执行请求并将响应发送给代理。
- 收到响应后,代理将其转发给客户端,但在此之前或之后可能执行额外的后处理操作,如缓存结果、调用原件的析构函数或对资源解除锁定。
实现
- 找出与组件访问控制相关的所有职责,将这些职责交给一个独立组件(代理)。
- 如果可能,用一个抽象类定义代理和原件接口都有的部分,并从这个抽象基类派生出代理和原件。 如果无法让代理和原件的接口相同,可使用适配器模式。
- 实现代理的函数
- 让原件和客户端不再承担已由代理承担的职责
- 在代理中包含一个指向原件的句柄(handler),将代理与原件关联起来。 这个句柄(handler)可以是指针、引用、地址、标识符、套接字、端口等。
- 消除客户端与原件的直接关系,用客户端与代理的类似关系取而代之。
变种
- Remote Proxy(远程代理) 对客户端隐藏远程组件的网络地址和进程间通信协议
- Protection Proxy(保护代理) 保护组件免受未经授权的访问
- Cache Proxy(缓存代理) 让多个本地客户端共享远程组件返回的结果
- Synchronization Proxy(同步代理) 同步对组件的并发访问
- Counting Proxy(计数代理) 防止无意间删除组件,收集使用统计信息
- Virtual Proxy(虚拟代理) 处理或加载组件的开销很高,而只需获取有关组件的部分信息就足够了
- Firewall Proxy(防火墙代理) 保护本地客户端,防止从外面直接访问它们
示例解答
有时代理会同时扮演多个角色并承担相应的责任
已知应用
- Web 代理
- Microsoft OLE,可实现为动态链接到客户端地址空间的库
效果
- 优点
- 效率更高、开销更低
- 将客户端与服务器组件位置分离
- 将管理代码与功能分离
- 缺点
- 间接降低了效率
- 无谓的复杂策略
参考
Decorator(装饰者模式)的结构与 Proxy 很像。在这个模式中,具体组件(ConcreteComponent,相当于 Proxy 模式中的原件)实现了一些通过装饰器(相当于 Proxy 模式中的代理)调用的行为。这两个类从同一个基类派生而来。Decorator 和 Proxy 的主要差别在于目的不同:前者旨在方便给组件动态的选择可添加的功能,而后者旨在避免在原件中包含具体的管理代码。
5. 管理模式
Command Processor
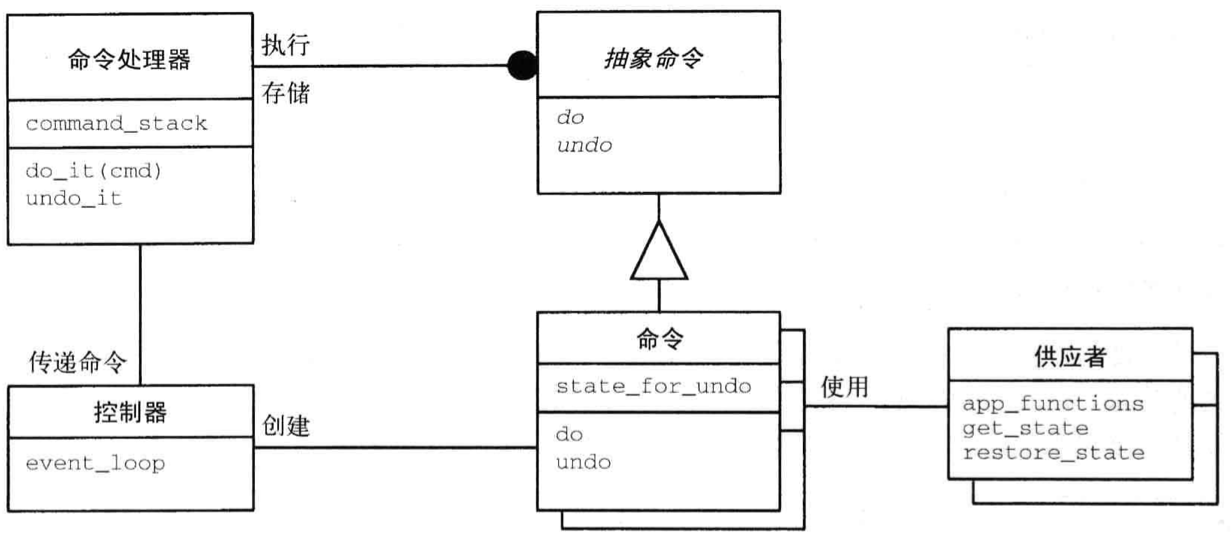 设计模式 Command Processor 将服务的请求和执行分开。命令处理器组件将请求作为独立的对象进行管理,调度其执行并提供额外服务,如存储请求对象以便以后能够撤销请求。
设计模式 Command Processor 将服务的请求和执行分开。命令处理器组件将请求作为独立的对象进行管理,调度其执行并提供额外服务,如存储请求对象以便以后能够撤销请求。
示例
文本编辑器的撤销功能。
背景
应用程序需要灵活且可扩展的用户界面,或提供与执行用户请求(如调度或撤销)相关的服务。
问题
除系统的核心功能外,你经常需要实现与执行用户请求相关的服务。这样的例子包括撤销、重做、将请求编组的宏、将操作写入日志以及调度和挂起请求等。需消解下述作用力:
- 不同的用户喜欢以不同的方式使用应用程序 如初级用户(简单界面)、中级用户(菜单栏)、高级用户(快捷键)
- 改进应用程序时不应导致既有代码无法正常运行
- 必须以一致的方式为所有请求实现额外服务,如撤销
解决方案
Command Processor 模式建立在《设计模式》介绍的 Command 模式的基础上。在 Command Processor 模式中,一个中央组件(命令处理器)负责管理所有命令对象,它调度命令的执行,可能存储命令对象以便能够撤销,还可能提供其他服务,如将命令序列写入日志以便测试。每个命令对象都将其任务委托给应用程序功能核心中的提供者(supplier)组件去执行。
结构
- 类
- 抽象命令
- 职责
- 定义用于执行命令的统一接口
- 扩展接口以支持命令处理器提供的服务,如撤销和写入日志
- 协作者
- 无
- 类
- 命令
- 职责
- 封装请求
- 实现抽象命令的接口
- 使用供应者来执行请求
- 协作者
- 提供者
- 类
- 控制器
- 职责
- 接收服务请求
- 将请求转换为命令
- 将命令交给命令处理器
- 协作者
- 命令处理器
- 命令
- 类
- 命令处理器
- 职责
- 启动命令
- 维护命令对象
- 提供与命令执行相关的额外服务
- 协作者
- 抽象命令
- 类
- 提供者
- 职责
- 提供应用程序特定的功能
- 协作者
- 无
动态
一个典型场景:收到将选定单词转换为大写的请求,执行该请求,再撤销。
- 控制器在事件循环中收到用户的请求,并创建命令对象”大写转换”(capitalize)
- 控制器将这个新命令对象传递给命令处理器,以便执行并做额外处理
- 命令处理器启动命令,并存储它以便能够撤销
- 命令 capitalize 从其提供者获取当前选定的文本,存储这些文本及其在文档中的位置,再请求提供者将选定文本转换为大写
- 收到撤销请求后,控制器将该请求传递给命令处理器。命令处理器调用最后一个命令的撤销过程。
- 命令 capitalize 用存储的文本替换制定位置的文本,将供应者恢复到以前的状态。
- 如果不再需要该命令,命令处理器将把它删除。
实现
- 定义抽象命令的接口
- 为应用程序支持的每类请求设计命令组件
- 提供组合多个相连命令的宏命令,以提高灵活性 使用 Composite 模式可以实现这种宏命令组件。
- 实现控制器组件
- 实现访问命令处理器的额外服务
- 实现命令处理器组件
变种
- 分散控制器功能。
- 组合使用模式 Interpreter
已知应用
- ET++,提供了一个命令处理器框架,支持无限步、有限步和单步撤销/重做。
- MacApp,使用设计模式 Command Processor 来提供可撤销的操作。
效果
- 优点
- 请求激活方式灵活 很容易重建用户输入到应用程序功能的映射。
- 请求的功能和数量灵活 除宏机制外,还可以预先编写组合命令,在不修改功能核心的情况下扩展应用程序。
- 与执行相关的服务易于编写 命令处理器可将命令写入日志或存储到文件中,供以后查看或重放;还可以将命令排队以及安排它们以后再执行。
- 应用程序级可测试性 将命令处理器执行的命令写入日志可对发生错误的情形进行分析,还可以用于回归测试。
- 并发性 Command Processor 允许在独立的控制线程中执行命令,有助于改善响应速度。然而,如果应用程序的全局变量被多个并行执行的命令访问,则需要同步。
- 缺点
- 影响效率
- 命令类可能太多,应对方法
- 根据抽象将命令编组
- 合并非常简单的命令类,并通过参数来传递提供者
- 编写依赖于多个低级命令的宏命令对象
- 获取命令参数的复杂性
参考
模式 Command Processor 建立在设计模式 Command 的基础上。这两个模式都阐述了将服务请求封装为命令对象的理念,但模式 Command Processor 更详细地诠释了如何处理命令对象。模式 Command Processor 的控制器相当于 Command 模式的客户端,它决定使用哪个命令执行用户请求,并创建一个新的命令对象。 然而,在模式 Command 中,客户端使用命令对象配置可用来响应多个用户请求的请求者(invoker)。在模式 Command Processor 中,命令处理器接收来自控制器的命令对象,并扮演请求者的角色——执行命令对象;控制器扮演着客户端角色;提供者对应于接收者,但不要求命令只能有一个接收者。
View Handler
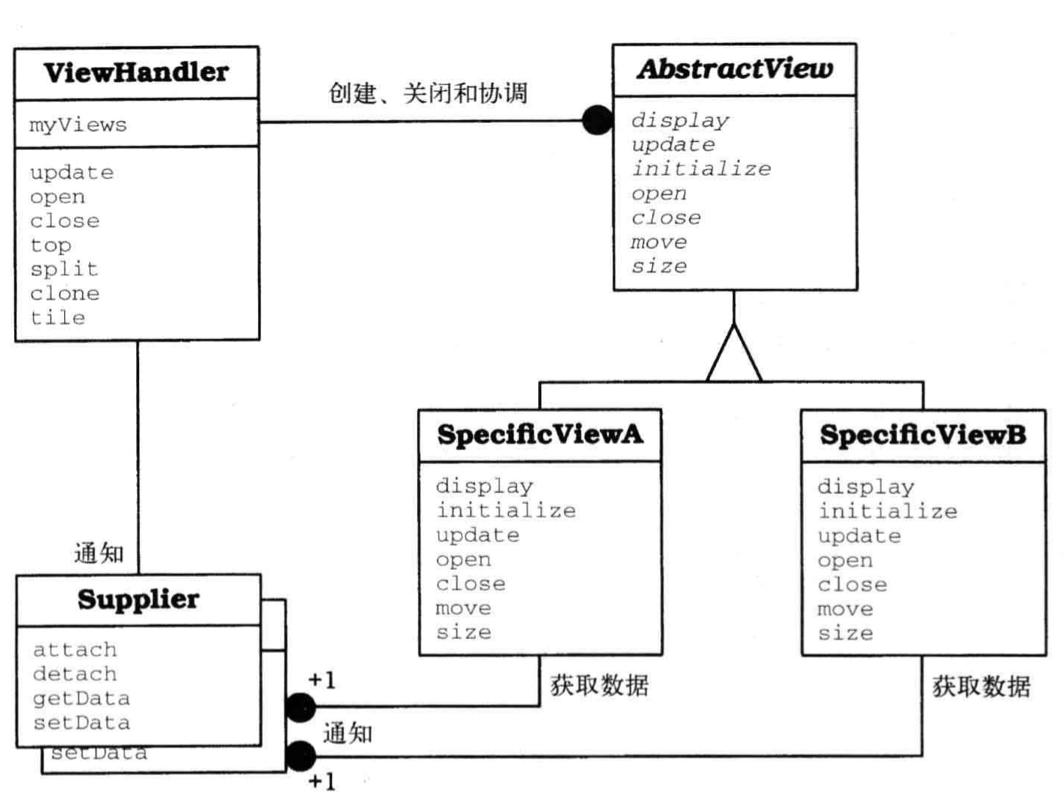 设计模式 View Handler 有助于管理软件系统提供的所有视图。视图管理者组件让客户端能够打开、操作和关闭视图,它还负责协调视图间依赖关系以及统筹视图更新。
设计模式 View Handler 有助于管理软件系统提供的所有视图。视图管理者组件让客户端能够打开、操作和关闭视图,它还负责协调视图间依赖关系以及统筹视图更新。
PS: 其实 TabView 就是用这个模式实现的
示例
在多文档编辑器中,用户可同时处理多个文档,其中每个文档都显示在不同的窗口中。 为有效地使用这种编辑器,用户需要窗口管理方面的支持。例如,用户可能想克隆窗口,以便使用同一个文档的多个视图;用户还常常让窗口一直打开,到要退出编辑器时才关闭。系统必须跟踪所有打开的文档并小心关闭它们。另外,一个窗口的变化可能影响其他窗口,因此需要一种高效地更新机制在窗口间传播变更。
背景
提供应用程序特定数据的多个视图或允许用户同时处理多个文档的软件系统。
问题
作用力:
- 无论是在用户还是系统的客户端组件看来,管理多个视图都轻而易举
- 各个视图的实现不能相互依赖,也不能与管理视图的代码混在一起
- 在系统的生命周期内,视图的实现可能发生变化,还可能添加新的视图类型
解决方案
将视图管理功能与显示和控制具体视图的代码分离
模式 View Handler 没有完全遵循 Model-View-Controller 提倡的将表示与核心功能分离的理念,它本身并没有提供完整的软件系统结构,而只是将管理所有视图及其相互依赖关系的职责从模型和视图组件中分离出来,并将这种职责交给视图管理者。例如,视图不需要管理子视图。因此,相比模式 Model-View-Controller,模式 View Handler 的粒度更细——帮助优化模型与相关联视图的关系。
可将视图管理者组件视为 Abstract Factory(抽象工厂)和 Mediator(调停者)。说它是抽象工厂是因为客户端不依赖于视图的创建方式;说它是调停者是因为客户端不依赖于协调视图的方式。
结构
- 类
- 视图管理者
- 职责
- 打开、操作和关闭软件系统的视图
- 协作者
- 具体视图
- 类
- 抽象视图
- 职责
- 定义一个接口,用于创建、初始化、协调和关闭具体视图
- 协作者
- 无
- 类
- 具体视图
- 职责
- 实现抽象视图的接口
- 协作者
- 供应者
- 类
- 供应者
- 职责
- 实现抽象视图的接口,每个视图一个类
- 协作者
- 具体视图
- 视图管理者
动态
- 情景 1 视图管理者新建视图
- 情景 2 视图管理者平铺视图
实现
这里假设供应者已准备就绪,且包含合适的变更传播机制。
- 确定所需的视图
- 定义所有视图通用的接口
- 实现视图
- 定义视图管理者
变种
- View Handler with Command objects(使用命令对象的视图管理者)。借助命令对象,这个变种能让视图管理者独立于视图接口。视图管理者不直接调用视图的功能,而是创建并执行合适的命令——命令本身知道如何操作视图。这样可以提供其他功能,如撤销已执行的命令。
已知应用
- Macintosh Window Manger
- Microsoft Word
效果
- 优点
- 以统一的方式管理视图
- 视图的可扩展性和可修改性
- 以应用程序特定的方式协调视图
- 缺点
- 适用范围有限
- 影响效率
参考
- Model-View-Controller
- Presentation-Abstraction-Control
6. 通信模式
Forwarder-Receiver
设计模式 Forwarder-Receiver 利用对等交互模型(Peer-to-Peer)让软件系统能够透明地进行进程间通信。它通过引入转发者和接收者将对等体与底层通信机制解耦。
示例
一种对等网络基础设施。
背景
对等通信
问题
作用力:
- 必须能够更换系统的通信机制
- 组件按对等模型协作,发送方只需知道接收方的名称
- 对等体之间的通信不应严重影响性能
解决方案
分布式对等体相互协作以解决特定问题。对等体可充当请求服务的客户端,也可充当提供服务的服务器,还可融这两种角色于一身。将系统特定的功能封装在独立组件中,从而向对等体隐藏用于首发消息的底层 IPC 机制的细节。这样的功能包括名称到物理位置的映射、通信信道的建立、消息的封送和解封送等。
结构
- 类
- 对等体
- 职责
- 提供应用程序服务
- 与其他对等体通信
- 协作者
- 转发者
- 接收者
- 类
- 转发者
- 职责
- 提供用于发送消息的通用接口
- 将消息封送并传输给远程接收者
- 将名称映射到物理地址
- 协作者
- 接收者
- 类
- 接收者
- 职责
- 提供用于接收消息的通用接口
- 接收并解封送来自远程转发者的消息
- 协作者
- 转发者
实现
- 定义名称到地址映射 名称可以对应于一组地址。对等体发送消息可以针对组发送。甚至可以采取层次结构,让一个编组为另一个编组的成员。
- 定义要在对等体和转发者之间使用的消息协议 需要考虑通常、超时、异常的情况。
- 选择通信机制 通常选择套接字效率就足够了,如果特别追求效率,可选择 TCP/IP 等低级机制。
- 实现转发者 将转发者的各项职责(如封送、消息传输和仓库,这些功能的实现取决于使用的 IPC 机制)分开大有裨益,可使用 Whole-Part 模式将每项职责封装到接收者的一个 Part 组件中。
- 实现接收者
- 实现应用程序的对等体 将对等体分为两组:服务器和客户端,两者可以有交集。
- 实现启动配置
变种
- 不包含名称——地址映射的 Forwarder-Receiver。
效果
- 优点
- 高效的进程间通信
- 封装了 IPC 机制
- 缺点
- 不能灵活地重新配置组件
参考
- Client-Dispatcher-Server 模式
Client-Dispatcher-Server
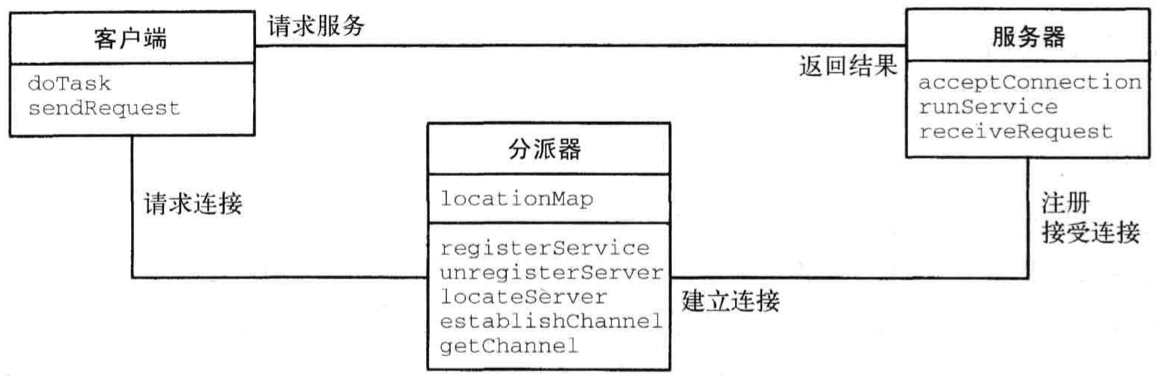 设计模式 Client-Dispatcher-Server 在客户端和服务器之间添加了一个中间层——分派器组件。它利用名称服务提供了位置透明性,并隐藏了在客户端和服务器之间建立通信连接的细节。
设计模式 Client-Dispatcher-Server 在客户端和服务器之间添加了一个中间层——分派器组件。它利用名称服务提供了位置透明性,并隐藏了在客户端和服务器之间建立通信连接的细节。
PS:看起来像 Nginx 的功能
示例
一个检索系统,信息提供方有些位于本地网络,其他的分布在世界各地。为访问信息提供方,必须指定其位置以及要执行的服务。收到客户端应用的请求后,信息提供方运行合适的服务,再将请求的信息返回给客户端。
背景
集成一组分布式服务器的软件系统,这些服务器位于本地或分布在网络中。
问题
作用力:
- 使用服务的组件不应依赖于服务提供方的位置
- 在服务的客户端,应将功能核心代码与用于连接到服务提供方的代码分开
解决方案
提供一个分派器组件,充当客户端和服务器之间的中间层。分派器实现了名称服务,让客户端能够使用名称而不是物理位置来引用服务器,从而提供了位置透明性。分派器还负责在客户端和服务器之间建立通信信道。 将服务器加入向其他组件提供服务的应用程序中。每个服务器都由其名称唯一标识,并通过分派器连接到客户端。 客户端依靠分派器来找到服务器并建立到服务器的通信链路。不同于传统的客户端——服务器模型,客户端和服务器可动态地变换角色。
结构
- 类
- 客户端
- 职责
- 执行系统的任务
- 请求分派器提供到服务器的连接
- 调用服务器提供的服务
- 协作者
- 分派器
- 服务器
- 类
- 服务器
- 职责
- 向客户端提供服务
- 向分派器注册
- 协作者
- 客户端
- 分派器
- 类
- 分派器
- 职责
- 在客户端和服务器之间建立通信信道
- 查找服务器
- 注册(注销)服务器
- 维护名称到位置的映射
- 协作者
- 客户端
- 服务器
实现
- 将应用程序组件分为服务器和客户端
- 确定需要哪些通信机制
- 确定组件间交互协议
- 决定如何给服务器命名
- 设计并实现分派器
- 根据制定的解决方案及有关分派器接口方面的决策实现客户端和服务器组件
变种
- Distributed Dispatchers(分布式分派器),在考虑使用这个变种前,应考虑使用架构模式 Broker。
- 通信由客户端管理的 Client-Dispatcher-Server
- 支持多种通信机制的 Client-Dispatcher-Server
- Client-Dispatcher-Service
已知应用
- Sun 的 RPC,遵循了 Client-Dispatcher-Server 的原则。
- OMG Corba 规范
效果
- 优点
- 服务器可更换
- 位置透明性
- 可重新配置
- 容错
- 缺点
- 间接性和显示建立连接降低了效率
- 对分派器接口变化敏感
Publisher-Subscriber
设计模式 Publisher-Subscriber 有助于让相互协作的组件的状态保持同步。为此,它实现了单向变更传播:发布者的状态发生变化时可通知任意数量的订阅者。
别名
Observer、Dependents
问题
作用力:
- 一个组件的状态发生变化时,必须通知其他组件
- 依赖组件的数量和身份预先并不知道或可能随时间推移而变化
- 让依赖组件显式地轮询不可行
- 引入变更传播机制时,不应让信息发布者和依赖于它的组件紧密耦合
解决方案
一个组件扮演发布者(《设计模式》中称为被观察者)角色,发布者信息变化将影响的所有组件都是订阅者(《设计模式》中成为观察者)。 发布者维护一个注册表,其中包含当前所有的订阅者组件。要成为订阅者,组件可使用发布者提供的订阅接口;组件还可以退订。 发布者修改状态后通知所有订阅者,订阅者再酌情获取修改后的数据。
推模型、拉模型,还有介于两者之间的模型,例如先推后拉。
变种
- Gatekeeper(看门人)模式。将 Publisher-Subscriber 用于分布式系统。在这个变种中,发布者通知位于另一个进程中的远程订阅者。发布者也可以分布在两个进程中:在一个进程中,一个组件向外发送消息;在接收进程中,一个”看门人”单例通过监视该进程的入口来分离消息。处理事件的订阅者注册的事件发生时,看门人将通知它们。
- Event Channel。这个变种将发布者和订阅者彻底解耦。例如,可以有多个发布者,订阅者只想知道发生了变化,而不想知道发布者的身份——不关心是哪个组件的数据发生了变化。同样,发布者也不关心哪些组件是订阅者。中间通过一个事件通道(event channel)隔离发布者和订阅者,而它自身即是原发布者的订阅者又是原订阅者的发布者。
- Producer-Consumer(生产者——消费者)模式。中间放置一个缓冲,将两者解耦。
第四章 成例
成例是编程语言特定的低层模式,阐述了如何使用特定语言实现组件的特定方面或组件之间的关系。 本章概述成例的用途,解释成例如何定义编程风格,并指出到哪里去寻找成例。
1. 导言
设计模式和成例之间的界线并不清晰。 编程风格指的是如何使用语言结构来实现解决方案,如使用的循环语句类型、程序元素命名惯例、源代码格式。上述每个方面的实现决策都可作为成例,而编程风格是由一系列这样的成例定义的。
PS: 感觉成例就是编码规范,里面蕴含了编码格式、避坑语法、惯例、最佳实践。
2. 成例的用途
单个成例可能有助于解决使用特定编程语言时反复遇到的问题,如内存管理、对象创建、方法命名、方便阅读的源代码格式、高效使用特定的库组件等。
3. 成例与风格
包含成例的风格指南效果更好。这种风格指南不仅给出了规则,还诠释了规则解决的问题。它们给成例指定了名称,以便方便交流。成例通常包含下面几项(举例):
- 名称 Indented Control Flow (缩进控制流程)
- 问题 如何缩进消息?
- 解决方案 对于参数少于两个的消息,将其与接收方放在同一行。 …一些代码示例
4. 到哪里去寻找成例
编码规范、编程风格、设计模式在语言的具体应用。
Counted Pointer 成例
在 C++中,成例 Counted Pointer 简化了动态分配的共享对象的内存管理。它在实体(body)类中引入一个由句柄(handle)对象更新的引用计数器。客户端只能通过句柄类重载的 operator->() 来访问实体对象。
PS: 后面 示例、背景、问题、解决方案、实现、变种、参考,就是按设计模式把计数指针描述一遍。
第五章 模式系统
模式系统将模式联系起来,阐述了模式之间的关系、模式的实现方式及其对软件开发有何帮助。模式系统是描绘和打造软件架构的利器。
1. 模式系统是什么
软件架构模式系统包含一系列软件架构模式,并提供了如何在软件开发中实现、组合和使用这些模式的指南。
模式系统必须符合如下条件:
- 包含的模式足够多
- 以统一的方式描述所有模式
- 揭示模式之间的各种关系
- 对模式进行组织
- 能够帮助打造软件系统
- 能够不断发展
2. 模式分类
模式类别:
- 架构模式
- 设计模式
- 成例
将《设计模式》中的模式融合到本书的模式体系中后,新的模式分类:
|问题类别|架构模式|设计模式|成例|
|—|—|—|—|
|从混沌到有序|Layers
Pipes and Filters
Blackboard
|interpreter||
|分布式系统|Broker
Pipes and Filters
Microkernel|||
|交互式系统|MVC
PAC|||
|可适应系统|Microkernel
Reflection|||
|创建||Abstract Factory
Prototype
Builder|Singleton
Factory Method|
|结构分解||Whole-Part
Composite||
|工作组织||Master-Slave
Chain of Responsibility
Command
Mediator||
|访问控制||Proxy
Facade
Iterator||
|服务变更||Bridge
Strategy
State|Template Method|
|服务扩展||Decorator
Visitor||
|管理||Command Processor
View Handler
Memento||
|适配||Adapter||
|通信||Publisher-Subscriber
Forwarder-Receiver
Client-Dispatcher-Server||
|资源管理||Flyweight|Counted Pointer|
- GoF 的组织方案不太好,因为结构模式和行为模式之间的界限太模糊,不如直接用问题类别更具表达力。
3. 选择模式
- 明确问题
- 问题是什么?
- 作用力有哪些?
- 根据设计活动选择模式类别
- 根据设计问题的基本特性选择问题类别
- 比较问题描述
- 比较优点和缺点
- 选择为设计问题提供了最佳解决方案的变种
- 选择替代问题类别
4. 作为实现指南的模式系统
- 使用你喜欢的任意方法定义软件开发总体流程以及每个开发阶段需要执行的详细任务。
- 以合适的模式系统为知道,设计并实现具体问题的解决方案。
- 在这个模式系统中,如果找不到能解决你的设计问题的模式,尝试在其他地方寻找合适的模式。
- 如果没有合适的模式,求助于你采用的分析于设计方法中的指南,这些指南至少能为你解决手头的设计问题提供些许帮助。
5. 模式系统的演化
- 模式描述的演化
- 创意写作工坊式审阅
- 模式发掘
- 添加新模式
- 删除过时的模式
- 扩展组织方案
6 总结
为充分发挥一组模式的威力,需要将它们组织成模式系统。模式系统为管理数量庞大的模式提供了方便的途径:它以统一的方式描述所有模式;通过分类让用户对其中的模式有大致认识;提供了合适的查找策略,可帮助用户选择模式;提供了使用模式开发软件系统的指南;还可不断发展演化。
第六章 模式与软件架构
1. 导言
为了理清软件架构领域的认识,先给出下列术语的定义:
- 软件架构 软件架构描述了软件系统的子系统和组件以及它们之间的关系。通常使用不同的视图来说明子系统和组件,以展示软件系统的功能特征和非功能特征。系统的软件架构是人工制品,是软件设计活动的结果。
- 组件
组件是被封装起来的软件系统的一部分,包含一个接口。组件是用于打造系统的构件。在编程语言层面,组件可能由模块、类、对象或一组相关的函数表示。
请注意,组件的性质可能有天壤之别。可能是链接库,也可能是独立进程。
组件分类方式1,分为三类:
- 处理元素
- 数据元素
- 连接元素 面向对象编程范式的另一种分类方式:
- 控制组件
- 协调组件
- 接口组件
- 服务提供组件
- 信息存储组件
- 组织组件
- 关系 关系描述了组件之间的联系,可能是静态的,也可能是动态的。静态关系会在源代码中直接显现出来,它们指出了架构中组件的布局; 动态关系指出了组件之间的临时联系和动态交互,可能不容易通过源代码的静态结构看出来。 三种静态关系:聚合、继承、组合
- 视图
视图呈现软件架构的某个方面,展示软件系统的某些具体特征。
[SNH95]建议从下面四个角度描绘软件架构:
- 概念架构:组件、关系等
- 模块架构:子系统、模块、导出、导入等
- 代码架构:文件、目录、库等
- 执行架构:任务、线程、进程等 [Kru95]采取的视图:
- 逻辑视图:设计方案的对象模型或通信模型,如实体关系图
- 流程视图:并发性和同步方面
- 物理视图:软件与硬件对应关系以及分布性方面
- 开发视图:软件在开发环境中的静态组织结构
- 功能特性和非功能特性
功能特征描述了系统功能的特定方面,通常与特定的功能需求相关。功能特性可能表现为应用程序用户能够看到的特定功能,也可能描述了实现的特定方面,如用于实现功能的需求。
肺功能特征描绘了功能特征未涵盖的软件特征,通常阐述了与软件系统的可靠性、兼容性、成本、易用性、维护或开发相关的方面。
非功能特征:
- 可修改性
- 互操作性
- 效率
- 可靠性
- 可测试性
- 可重用性
- 软件设计 软件设计指的是软件开发人员根据给定的功能和非功能特征,确定软件系统的组件以及组件间关系的活动,其成果为系统的软件架构。 传统上,将系统高级结构分解称为”软件架构(设计)”或”粗粒度设计”,而将更详细的规划称为”(详细)设计”。前面说过,我们将开发软件系统的整个活动称为”软件设计”,并将这种活动的成果称为”软件架构”。 当前,很多开发人员喜欢将设计活动得到的所有成果称为”软件架构”,而不是”软件设计方案”。它们这样做旨在指出这样一个事实,即它们所做的不是将系统功能分解为一组相互协作的组件,而是打造一个软件架构。他们想表明,他们致力于以合适的方式打造软件系统的组件,还有这些组件的职责、功能、接口和内部结构以及组件间的各种关系和协作方式,所有这一些都必须考虑可修改性和可移植性等非功能特征。对于高级设计决策可独立于低级决策的说法,他们不再苟同。
2. 软件架构中的模式
-
开发方法 一条比较准确的经验法则是,开发方法的价值与其通用程度呈反比。适用于解决所有问题的方法对解决具体问题毫无用处。
-
开发流程
-
架构风格 架构风格从组织结构的角度定义了一个软件系统族,描绘了组件及其关系、使用这些组件时应满足的约束条件,以及创建这些组件时应遵循的组合和设计规则。
-
框架 框架是一个有待实例化的软件(子)系统半成品。它为一个(子)系统族定义了架构,并提供了创建它们的构件。框架还指出了需要调整哪些地方的具体功能。在面向对象环境中,框架由抽象类和具体类组成。
3. 软件架构支持技术
- 抽象 抽象是人类用来应对复杂性的基本原则之一。Grady Booch这样定义抽象:抽象是将一个对象与其他各种对象区分开来的基本特征,让观察者能够看到清晰而明确的概念边界。抽象存在多种形式,如实体抽象、行为抽象、虚拟机抽象和偶然抽象。 例如:Layers、Abstract Factory。
- 封装 封装指的是将决定抽象的结构和行为的元素编组,并将不同的抽象分离。封装在抽象之间提供了清晰的界限。封装可改善可修改性和可重用性等非功能特征。 例如:Forwarder-Receiver
- 信息隐藏 信息隐藏是一种最基本、最重要的软件工程原则。信息隐藏指的是对客户端(调用者)隐藏组件的实现细节,以更好地应对系统复杂性,最大限度地降低组件之间的耦合度。 例如:Whole-Part 反射概念没有完全遵循信息隐藏原则。为提高可适应性和可修改性,Reflection模式以特定方式暴露了软件系统或组件的实现。
- 模块化 模块化指的是有目的地将软件系统分解成子系统和组件,其主要任务是决定如何对构成应用程序逻辑结构的实体进行包装。模块化的主要目标是,通过在程序中引入清晰的边界来应对系统的复杂性。模块是应用程序功能或职责的物理容器。模块化与封装原则关系紧密。 例如:Layers、Pipes and Filters、Whole-Part
- 分离关注点 在软件系统中,应将不同或不相关的职责分开,如将这些职责分配给不同组件。对于致力于解决特定任务且相互协作的组件,应将他们同参与完成其他任务的组件分开。如果同一个组件在不同情形下扮演者不同的角色,这些角色应相互独立,并在组件中将它们分离。 例如:Model-View-Controller模式分离了如下关注点:内部模型、向用户显示信息和输入处理
- 耦合与内聚 耦合专注于模块之间的关系,而内聚凸显的是模块内部的特征。 耦合指的是模块之间的连接建立的关联程强度。强耦合导致系统更复杂,因为与其他模块紧密相关的模块更难理解、修改和修复。设计系统时,让模块之间弱耦合可降低复杂度。 内聚指的是模块内的功能和元素之间的相关度。有多种形式的内聚,最可取的形式是功能内聚,它指的是模块或组件中的所有元素协同合作,以提供某种明确的行为。最糟糕的形式是偶然内聚,即将所有相关的抽象都放在同一个模块中。其他类型的内聚:逻辑内聚、临时内聚、过程内聚、通信内聚、顺序内聚和随意内聚。 例如:Client-Dispatcher-Server、Publisher-Subscriber
- 充分、完整、简单 软件系统的每个组件都应该充分、完整、简单。充分(sufficient)的意思是组件具备所有必要的抽象特征,以便能够与它进行意味深长而又高效的交互;完整指的是组件应该具备其抽象的所有特征;简单指的是组件可执行的所有操作都容易实现。每个模式的主要目标都是为给定问题提供充分而完整的解决方案,而很多模式实现起来还相对简单和容易。如Strategy
- 策略与实现分离
软件系统的特定组件要么处理策略,要么处理实现,而不能兼顾。
- 策略组件负责上下文相关决策、解读信息的语义和含义、将众多不同结果合并或选择参数值。
- 实现组件负责执行定义完整的算法,不需要作出与上下文相关的决策。上下文和解释通常是外部的,通常由传递组件的参数提供。 纯粹的实现组件不依赖于上下文,因此更容易重用和维护;而策略组件通常随应用程序而异,因此经常需要修改。 如果无法将策略和实现放在不同组件中,至少应确保组件中的策略和实现之间有清晰的界限。如Stratege模式专注于实现这个原则。
- 接口与实现分离
任何组件都应包含两部分。
- 接口部分:定义了组件提供的功能以及如何使用该组件。组件的客户端可以访问该接口。导出接口通常由函数特征(signature)组成。
- 实现部分:包含实现组件提供的功能的实际代码,还可能包含仅供组件内部使用的函数和数据结构。组件的客户端不能访问其实现部分。 这条原则的主要目标是对组件的客户端隐藏实现细节,只向客户端提供组件的接口规范和使用指南。 接口与实现分离还有助于改善可修改性——组件的接口与实现分离后,修改起来将容易得多。这种分离避免了修改直接影响到客户端。这条原则尤其可简化修改组件行为或表示方式的工作——这种修改可能旨在提高性能,不会导致必须对组件的接口进行修改。诸如Bridge等模式致力于遵循接口与实现分离原则。
- 单个引用点 软件系统中的任何元素都应只声明和定义一次,这条原则旨在避免不一致性问题。 然而,鉴于设计原则和实现,诸如C++等很多编程语言要求只有一个定义点,但允许甚至要求有多个声明点。就C++而言,这主要是由传统编译器和链接器技术的局限性导致的。对程序员来说,这增加了他们手工维护一致性的负担。 PS: Go就很好的解决了这个问题,同时提高了编译速度、降低了依赖复杂度。
- 分而治之 这是一条著名的原则,自上而下的设计将任务或组件划分为可分别设计的部分。模式Microkernel将原本是一整块的代码进行分解。分而治之还提供了一种实现关注点分离的途径。
- 小结 需要指出的是,并非所有通用原则都是互补的,有些原则相互矛盾,如接口与实现分离原则和单个引用点原则。使用传统技术水岸接口与实现分离原则时,每个函数至少需要两个引用点,一个位于组件的接口部分,另一个位于实现部分。这违背严格意义上的单个引用点原则。当然,一种解决方案是根据实现来生成接口,较新的方法就采用了这种解决方案。 还有一些原则紧密相关,如抽象和封装。要对软件系统中的实体进行合理抽象,必须将组成其结构的所有元素封装在一个组件或模块中。
4. 软件架构的非功能特征
非功能特征对软件系统的开发和维护工作、总体可操作性以及消耗的计算机资源有重大影响。除影响应用程序的质量和架构外,非功能特征还会影响系统的功能特征。软件系统的规模越大、复杂度越高、生命周期越长,非功能特征就越重要。软件架构模式无疑考虑了这些非功能特征。
1. 可修改性
正如[Par94]描绘的,软件老化的后果是:越来越难以通过引入新功能来跟上市场的步伐,性能越来越低,可靠性越来越差。为避免这些情况发生,可提供准确的文档,修改时保留原来的结构,认真审核,当然还有在最初设计时就为修改做好准备。 可修改性包括下面四个方面:
- 可维护性:这主要指的是修复问题,即出现错误后对软件系统进行”修理”。如果软件架构为维护做好了充分准备,通常只需做局部修改,且可最大限度地降低修改给其他组件带来的副作用。
- 可扩展性:这主要指的是给软件系统添加新功能,将组件替换为改进后的版本以及删除多余或不必要的功能和组件。为提高可扩展性,软件系统的组件必须松耦合。目标是打造出让你更换组件时不会影响其客户端的结构,并支持在既有架构中添加新组件。
- 重组:这指的是重新组织软件系统的组件以及它们之间的关系,如调整组件的位置,将其移到另一个子系统中。为支持软件系统重组,必须仔细设计组件之间的关系。理想情况下,应该能够灵活地配置组件,而不影响其实现的主要部分。
- 可移植性:这指的是对软件系统进行修改,使其支持各种硬件平台、用户界面、操作系统、编程语言或编译器。为提供可移植性,需要这样组织软件系统:找出依赖于硬件、其他软件系统和环境的部分,将其放在系统库和用户界面库等特殊组件中。
最后,随着模式的使用日益广泛,我们发现有滥用模式的趋势。灵活性是要付出代价的。灵活的软件通常间接程度更高或占用的存储空间更多,因此消耗的资源更多。编写这种软件的代码时,还必须更深入地思考,工作量也更大。因此,优秀的设计人员力图预先确定软件的哪些部分必须高度灵活(以应对可预见的变化),哪些部分可能固定不变。即便结果表明他们判断错了,也可增加额外的灵活性,方法是仔细地重组系统的各个部分或使用支持修改的模式。相比一开始就提供全面的可修改性,这种方法更经济实惠。
2. 互操作性
系统中的软件并非孤立,经常需要与其他系统或环境交互。为提高互操作性,设计软件架构时,对于那些外部可见的功能和数据结构,必须提供明确的访问途径。互操作性的另一个方面是程序与使用其他编程语言编写的软件系统的交互,这也会影响应用程序的软件架构。Broker可能是最典型的致力于提高互操作性的模式。
3. 效率
很多模式都为解决问题增加了间接程度,这可能降低而不是提高了效率。
4. 可靠性
可靠性指的是,无论应用程序或系统发生错误,还是用户以意外或错误的方式使用,软件系统都能继续运行。可靠性分为两个方面:
- 容错:其目标是在发生错误时确保行为正确并自行修复,如分布软件系统在到远程组件的连接断开时重新建立连接。修复这种错误后,软件系统应继续或重新执行错误发生时正在执行的操作。
- 健壮性:指的是对应用程序进行保护,以抵御错误的使用方式和无效输入,确保它在发生意外错误时处于指定的状态。请注意,不同于容错,健壮性并不一定意味着软件能够在发生错误时继续运行,也可能只保证软件以指定方式终止。
Master-Slave演示了模式如何改善可靠性的特定方面。
5. 可测试性
6. 可重用性
- 通过重用开发软件
- 开发软件时考虑重用
5. 总结
第七章 模式界
1. 起源
2. 领军人物及其成果
3. 模式界
PLoP(Pattern Languages of Programming,编程模式语言会议)