 今天参加了由北京 GDG(Google Developer Group)推动的 TFUG(Tensor Flow User Group)线下活动。
今天参加了由北京 GDG(Google Developer Group)推动的 TFUG(Tensor Flow User Group)线下活动。
由 Christopher Dossman 和 Eliyar Eziz 介绍 Tensor Flow 的基本概念和快速上手方法,并且讲了下最近很火的换脸 GAN 的基本原理和训练方法。
(两位帅哥都是 Google Machine Learning Expert,目前供职于同一家 AI 公司 Wonder Technology。)
Tensor Flow 介绍
 TensorFlow 是一个比较流行的机器学习(ML–Machine Learning)框架,由谷歌大脑团队开发维护,2015 年 11 月开源。
TensorFlow 是一个比较流行的机器学习(ML–Machine Learning)框架,由谷歌大脑团队开发维护,2015 年 11 月开源。
主要用 Python 开发,集合了 CNN、RNN、DNN 等各种神经网络算法及辅助工具,可以运行于 CPU、GPU 和各种操作系统。新推出的 TensorFlowLite 可以运行于 Android 或 Chorme 浏览器中,兼顾了性能和耗电。
Build a Machine Learning product demo in half a day(Christopher)
Why Wechat?
如果你有一个 AI 服务,那么最好的 UI 就是用微信,因为微信在中国普及度极高而且有现成的开源接口可用,你的 AI 产品很容易实现和推广。
Why TensorFlow?
TensorFlow 简单易用、社区活跃,很容易找到各种学习资源。并且他是面向工业级的框架,同时具有很好的渐进伸缩性,当你的项目越来越大时也不必担心要切换平台。
实现步骤:
前置条件: Python3 + Docker
- 1
docker pull xxx这个镜像中已经包含了训练好的基于 TensorFlow 图像识别模型,在网上就可以找到很多这种 docker 镜像。可以直接运行起来提供图片识别服务。 - 2
pip install WechatBot一个开源适配接口,可以与微信进行交互。 - 3
pip install ProtoBuf一个二进制通信协议,用于 WechatBot 和图片识别 Server 间的通信。 - 4 写一段 34 行(包括注释)的 Python 代码,用于将微信群中的图片转发给图像识别 Server,以及结果的返回。
- 5 启动图片识别服务、WechatBot 程序、微信扫描二维码验证登录 Bot、创建微信群。
 Christopher 现场执行了最后的启动操作,然后大家就可以进群发送图片了,稍等几秒就能收到识别结果,而这一切都是在他的笔记本上运行的,的确很方便。
Christopher 现场执行了最后的启动操作,然后大家就可以进群发送图片了,稍等几秒就能收到识别结果,而这一切都是在他的笔记本上运行的,的确很方便。

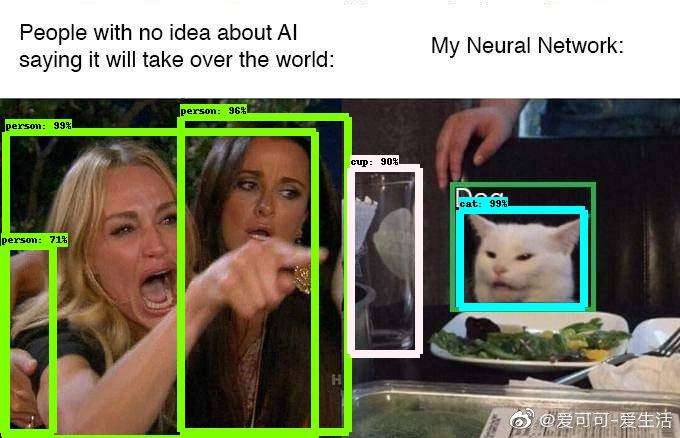
结果图片中每个识别框边缘写着物体类型、识别可信度,可以同时识别多个物体。
 最后他总结:”所有上面这些操作,只要两小时就可以完成。So, Try it out!”
最后他总结:”所有上面这些操作,只要两小时就可以完成。So, Try it out!”
Implementing GAN using TF 2.0(艾力)
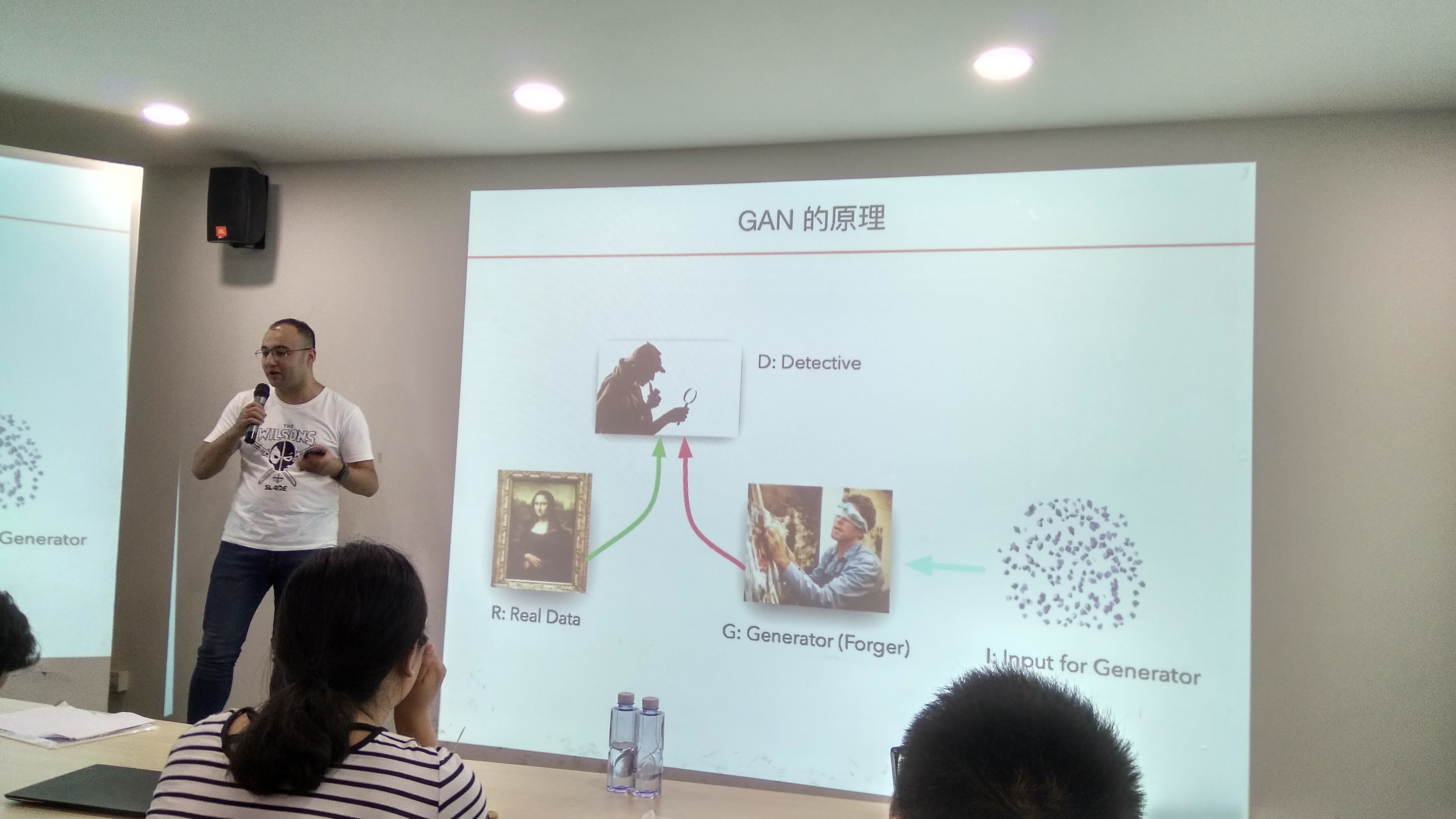
生成式对抗网络(GAN, Generative Adversarial Networks)
Discriminative(判别模型)
- 学习类别之间的差异/分界
- 参数数量较少,易于训练
- 只能用于分类,不能用于数据生成
Generative(生成模型)
- 学习类别特征的概率分布
- 学习到特征的概率分布,可以用于生成
- 参数数量很多,需要大量的数据样本
生成器(Generator):接受一个随机向量噪音 x 作为输入,生成一个张量 G(x)。
判别器(Discriminator):接受一个张量作为输入,输出其真实性。
- 简单来说,判别器就是我们常见的分类,而生成器就是从随机噪音生成一个可被判别器接受的输入值。
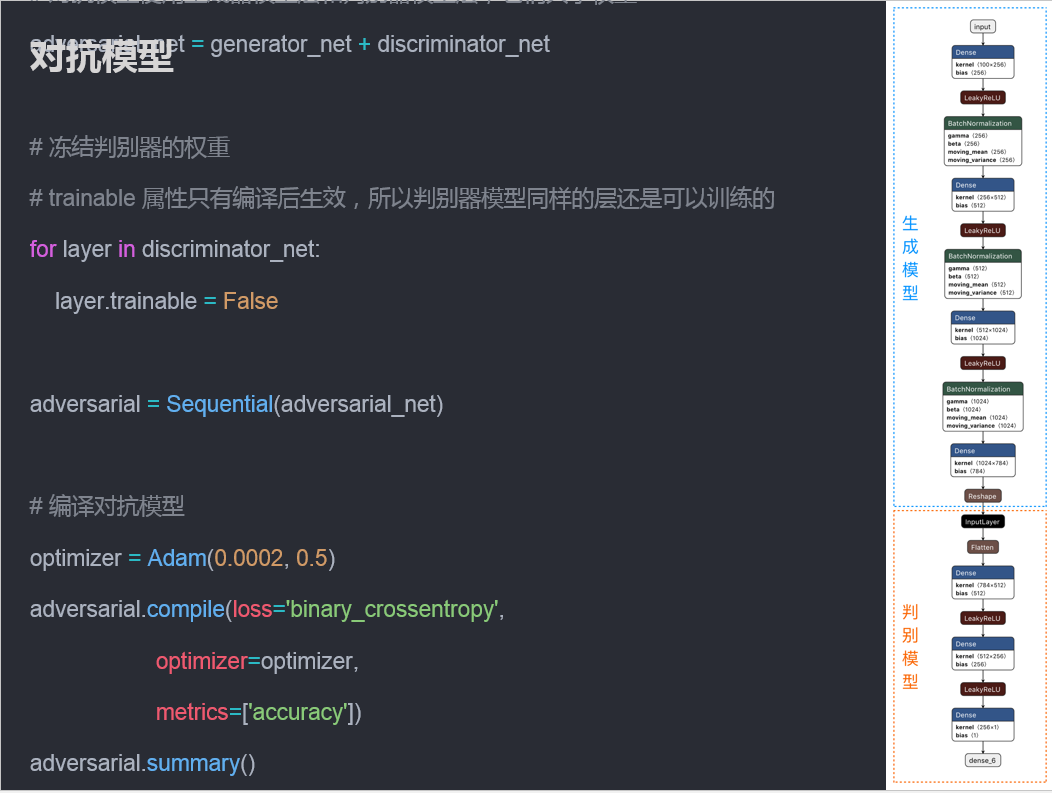
训练过程
- 定义生成器模型。生成器接受随机输入,输出一个生成图像张量。
- 定义判别器模型。判别器接受一张图像输入,输出一个代表图像真伪的张量。
- 定义一个对抗模型。对抗模型接受随机输入,输出一个代表图像真伪的张量。对抗模型的网络层由生成器模型层和判别器模型层组成,其中判别器的层需要冻结。
- 将一批随机噪音输入到生成器模型,生成一批图像。
- 使用生成的图像和真实图像训练判别器。
- 再使用新的随机输入训练对抗模型中的生成器,使其造假越来越逼真。
- 重复步骤 4-7。
 可以利用各种 lab 平台做练习,在平台上可以直接选择机器配置和环境,运行很方便。</br>
艾力现场使用 openbayes 作为测试平台,通过 2000 多次的训练,生成了上面的对抗网络。
可以利用各种 lab 平台做练习,在平台上可以直接选择机器配置和环境,运行很方便。</br>
艾力现场使用 openbayes 作为测试平台,通过 2000 多次的训练,生成了上面的对抗网络。
训练要点
现场有人提问:为什么判别器和生成器要一同训练?不能先把判别器训练好再训练生成器?
答:判别器就好比老师、生成器就好比学生,我们要的结果是学生做出的东西以假乱真,让别人无法识别出是老师还是学生做出的东西。
如果学生的老师的差距过大,比如幼儿园的学生与大学教授,那么学生的几乎任何产出都会老师被判定为假,那么学生就无法进步了。
同样的道理,生成器如果任何输出都被判别无效(为假),那么生成器就无法被训练出来了,这就是所谓的掉入了”黑坑”(黑洞级的坑)。
- PS:与这种问题相对应的,退火算法需要添加随机性避免陷入局部最优解,而现在的问题是随机性过大,无法在有限时间内获得可接受的解。
 最后他总结:在自己尝试训练 GAN 时,最好先找现有的已经成功的例子,逐步尝试、增加难度,否则很容易遇到过不去的问题。比如一个很简单的,设置某层网络参数是否可变的设置项,如果在编译后再设置,可以设置成功、可以正常读取,但是其实这个设置项是没有起作用的,这个简单的问题花了一个星期才找到。
最后他总结:在自己尝试训练 GAN 时,最好先找现有的已经成功的例子,逐步尝试、增加难度,否则很容易遇到过不去的问题。比如一个很简单的,设置某层网络参数是否可变的设置项,如果在编译后再设置,可以设置成功、可以正常读取,但是其实这个设置项是没有起作用的,这个简单的问题花了一个星期才找到。
PS: 现场讨论、感受
应用领域
生成对抗网络,现在还没有太有价值的应用,目前的方向是做一些有创造性的算法,这样可以符合某种大的分类但是可以骗过人的眼睛。比如最近比较火的换脸 App。
现在有一个应用方向,比如建筑行业可以利用生成对抗网络在自动生成 3D 模型时同时生成虚拟的环境,而这种环境的内容是随机的但是让人觉得很自然。
进入门槛、docker
Christopher 之所以能在两小时内完成这个功能强大的软件,其实主要利用了 Python 和 Docker 的易用性。如果没有 Docker 事先训练或搭建好的环境,对于一个外行想搭建一个神经网络训练环境难度肯定不会低。
因为环境的搭建要用到 Docker,现场他提问:”在座有多少使用过 Docker 的?”,现场 50 人只有 5 人举手,说明现在 Docker 普及度还不高。
会议规模对比
这次的会议国模较小,不到 50 人。相比之前 Intel 的千人高端会议,硬件条件差一些,演讲者准备时间也有限,没有机会让大家都手动实现一下小项目。
但是正因为人少,大家都比较放的开,提问比较积极。现场与几位专家交流,可以快速获得一些总结性的经验,沟通效率很高。