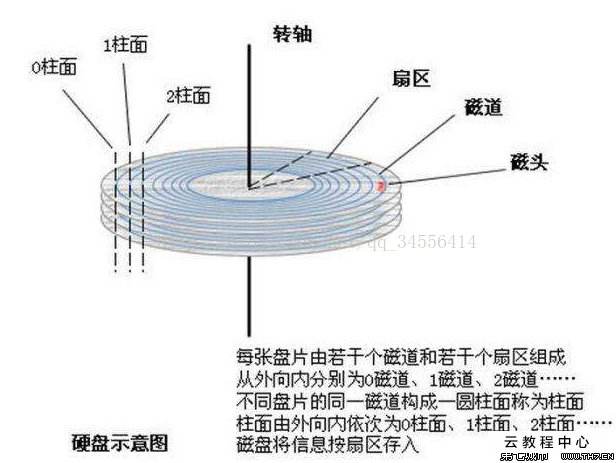
 MySQL 的数据是存储在硬盘上的,由于硬盘的机械结构,每次读写要等到磁盘的扇区旋转到合适的位置时才能进行,所以速度相比内存(纯电子电路)慢两个数量级(100 倍以上)。
MySQL 的数据是存储在硬盘上的,由于硬盘的机械结构,每次读写要等到磁盘的扇区旋转到合适的位置时才能进行,所以速度相比内存(纯电子电路)慢两个数量级(100 倍以上)。
基于这种速度差异,在设计数据库时就要遵守一个原则——尽量少的进行硬盘操作,而主键的设计正好符合这个原则。下面以 InnoDB 为引擎,解释主键的作用。
MySQL 数据库主键
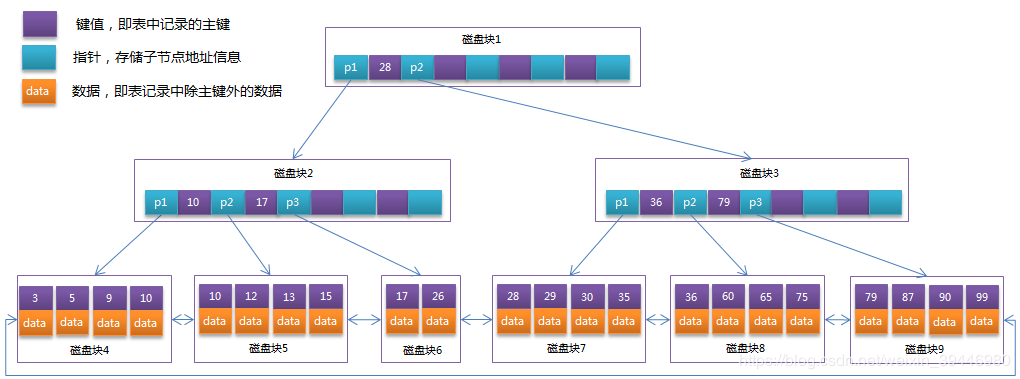
- 聚集索引 也叫”聚簇”索引,既存储了索引 key 又存储了行值,物理地址的逻辑顺序和表存储的顺序一致,并且 key 是唯一的。这时,由于页是连续的,可以发挥磁盘连续页查询优势。
- 非聚集索引 只存储了索引 key 及数据的物理地址,找到 key 后再通过物理地址查找行值,key 的顺序与数据的物理地址没有强一致性。
- 密集索引 所有索引值都在索引中出现,需要存储容量较大。例如 MySQL 的非主键,是非聚集索引,无需绑定数据,同是必须是密集索引。
- 稀疏索引 索引值有序保存,所以索引值可以不全部出现,比如 String 类型的索引,只以前两个字母做索引元素,其他内容顺序或二分遍历即可。 MySQL 的主键是聚集索引,可以选择以密集或稀疏方式存储。
- 回表查询 查询时先按索引查询,再按物理地址查找行值(
explain->extra->using where)。聚集索引无需回表,非聚集索引需要回表。
InnoDB 需要主键(或主键替代者)来作为数据存储的聚集索引,主键本身也是一个索引(unique not null increase),所以也采用 B+树,具体 B+树的结构在索引章节讲解。
由于硬盘每次的读取容量是一个固定值(4K 8K 16K),也就是在连续的硬盘上读取 1K 或 15K 都是一次操作,耗费的时间相同。所以 InnoDB 中的数据是以页(page)为单位存储的,不同页中的数据在硬盘上可能是无序的(根据聚集类型不同),而同一个页内的数据是有序的。
查看页大小
1 | |
如果我们定义了主键(PRIMARY KEY),那么 InnoDB 会将主键作为聚集索引;如果没有显示定义主键,InnoDB 会自动找一个 unique not null 索引作为主键;如果没有找到,InnoDB 会为该表内置一个 6 字节的自增 ROWID 作为隐含的聚集索引。
可以看出,无论如何数据库都需要一个主键,所以最好我们最好自己定义,避免默认创建的主键引起其他问题。
主键使用的一些注意点
在一个页中,数据是有序的,当向页中间插入数据时,就会进行数据移动;如果数据量超过页的容量,则会创建一个新页存储,这就是页分裂。
如果频繁对已经存在的页进行插入、删除记录,就会发生很多移动、分裂,形成大量的碎片。原本设计每个页 16K 是为了减少 IO,而大量碎片的出现会导致 IO 效率降低。
例如上一节的说明中,如果没有自定义主键,但是找到一个”unique not null index”,那么新数据的插入位置是随机的,使用中就会形成碎片。所以我们最好自己定义一个自增主键。
最佳实践:自增 ID 做主键
通常我们都会在表中设一个自增 ID 主键,它可以带来如下好处:
- ID 只增不减,所以每写满 16K 的数据块,就可以开辟新块,不会发生插入数据导致页分裂
- 主键本身也是一个索引,索引就要占据硬盘和内存空间,所以在不影响使用的情况下容量越小越好。默认 int 型主键,容量足够小。
- 对于长期维护的复杂业务,表中有一个自增 ID 对于后期进行数据库迁移、数据库结构变更等操作更为方便,主键可以提供顺序、ID 标识。
PS:
关于自增主键的一个潜在问题,当数值达到最大值后,每一次新增数据都会引起错误。所以自增主键范围要估计好或及时扩容。
关于自增主键的特性
以下特性基于 InnoDB 引擎
- 当前占用最大 ID 的数据被删后,下一个 ID 是什么?
- 下一个 ID 是被删前 max(ID) + 1,因为 MySQL 有个变量始终记录之前的最大 ID,而删除最大 ID 时没有更新这个变量
- MySQL 重启后自增 ID 从哪儿开始
- 自增后会重新计算已存在的最大 ID,所以如果曾经删除过最大 ID 的数据,则重启后之前那个 ID 还是会被重用
- 手动插入 ID 后,下次插入时自增值是多少
- 手动插入 ID 时,会自动更新历史最大 ID 变量,所以下一个自增 ID 是
手动插入ID+1
- 手动插入 ID 时,会自动更新历史最大 ID 变量,所以下一个自增 ID 是
- 自增 ID 用完后怎么办?
- 无符号 int 的最大值为 4294967295,自增值达到此值后,就不变了,新插入记录时就会报错:
Duplicate entry '4294967295' for key 'PRIMARY' - 如果表记录经常插入、删除,即使表内记录总量不是很大,ID 也可能快速用完,这种情况可以需要使用 bigint。 无符号 bigint 最大值为 18446744073709551615,完全够用了
- 无符号 int 的最大值为 4294967295,自增值达到此值后,就不变了,新插入记录时就会报错:
最佳实践:
CREATE TABLE your_table (
id INT PRIMARY KEY AUTO_INCREMENT,
data VARCHAR(255),
ctime TIMESTAMP DEFAULT CURRENT_TIMESTAMP, // 创建时间
mtime TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, // 变更时间
is_delete TINY_INT DEFAULT 0, // 软删除标记,0-未删除;1-已删除
);
-
is_delete 软删除标记
- 如果删除某个元素,会导致对应的索引存储位置形成空洞。由于 MySQL 要保证索引的高效,这时可能引发文件连锁整理,造成性能急剧下降。
可以设立一个
is_delete字段,tiny_int型即可,默认为 0 表示不删除,删除时设置为 1。这样就可以避免由于删除导致的重排。 - 当数据积累较多时,再考虑重新整理、删除旧数据。
is_delete要设索引,这样可以在查询中快速过滤掉无效值。例如某些场景下,未删除的实际占少数,这样就可以快速缩小查询范围,提高效率。
- 如果删除某个元素,会导致对应的索引存储位置形成空洞。由于 MySQL 要保证索引的高效,这时可能引发文件连锁整理,造成性能急剧下降。
可以设立一个
-
ctime/mtime 数据创建、变更时间记录
- 这两个字段有助于后期维护,可方便判断关键时点
- 在对软删除记录清理时,可以结合 mtime 和 is_delete 判断是否可以批量删掉