
今天参加了”Intel AI Workshop - From Data Center to Edge – An optimized path using Intel Architecture”。
通过几位老师(Gu Jianjun、Cao Huiyan、Pei Fanjiang 和他们的老大Derek Fattibene)的教学,我把神经网络的数据整理、模型训练和模型推理走了一个完整的流程。正好借这个机会,记录一个卷积神经网络的实际案例,之后陆续把课程笔记写下来。
课程题目
太大的题目难以在一天的课程中完成,所以我们选择一个可能实现的挑战 —— 对车辆进行识别
题目背景:
识别全美最常被偷盗的车辆(美国国家保险犯罪调查局),可以应用于交通管理系统。
——图片识别问题,我们将通过图像识别(视频)对车辆的生产商、型号、生产年代进行识别
使用VMMRdb作为数据集
训练环境: Intel DevCloud + Tensor Flow
- 在网上注册可提供4周的练习环境
- 双核3.40GHz
- 192G RAM
- 200 GB硬盘
- 提供Python2.7、3.6,还有TensorFlow等工具
最终利用Intel OpenVINO平台对模型进行部署和推理
( 推理 就是指把模型部署到终端,对数据进行计算得出结论的过程,也就是模型的应用)
对数据探索分析
数据获取
数据处理中,大量数据标记是主要的工作量。
为了节省时间和资金成本,我们可以充分利用别人已经完成的标记成果。
我们选用VMMRdb(Vehicle Make and Model Recognition Dataset)作为数据集
数据范围
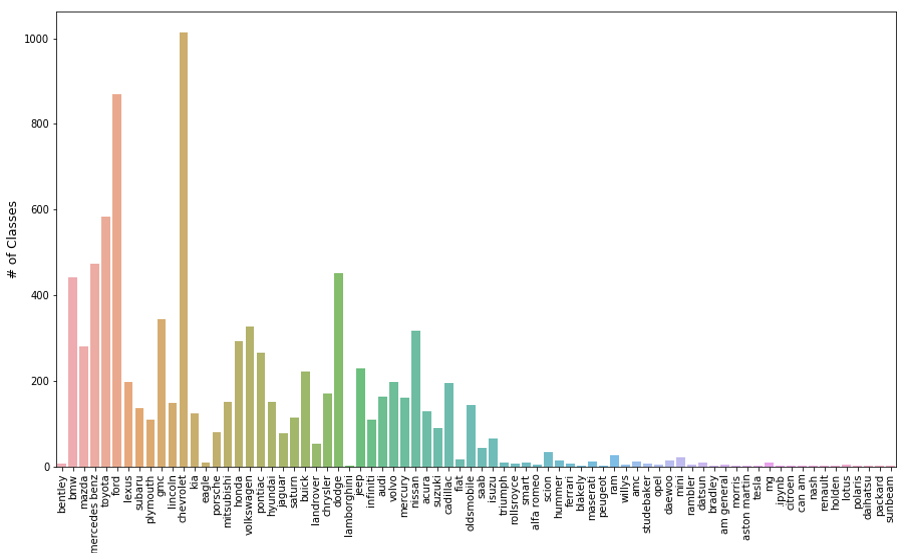 VMMRdb提供了9170个型号、76个厂家、291,752张图片…
VMMRdb提供了9170个型号、76个厂家、291,752张图片…
为了实验效果更好,我们要选定一个更小的实验范围,选定美国被盗的前十大车型作为数据集。
每个图片都有对应的标记:
1 |
|
※通常训练数据、验证数据、最终测试数据的比例为: 7:2:1
预处理和数据增强
因为 数据质量决定模型质量 ,所以要进行预处理,对明显的无效数据进行去除或修改:
1 |
|
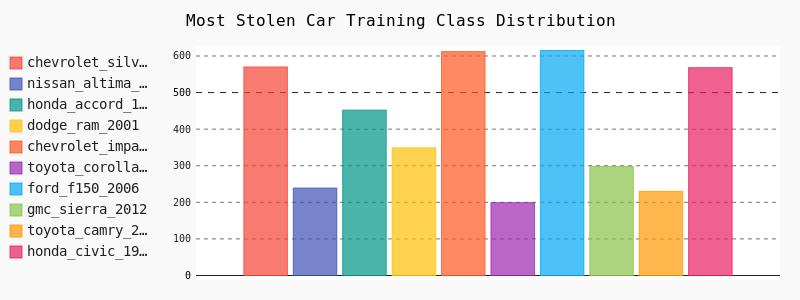 我们选定的十大被盗车型数据量
我们选定的十大被盗车型数据量
可以看出各车型的数据量差异较大,为了避免由于数据量不平衡造成的模型精度下降,我们可以通过一些方法创造更多数据:
1 |
|
※注意在图片平移、裁剪时控制一下范围,不要让主体被移出成为无效数据。
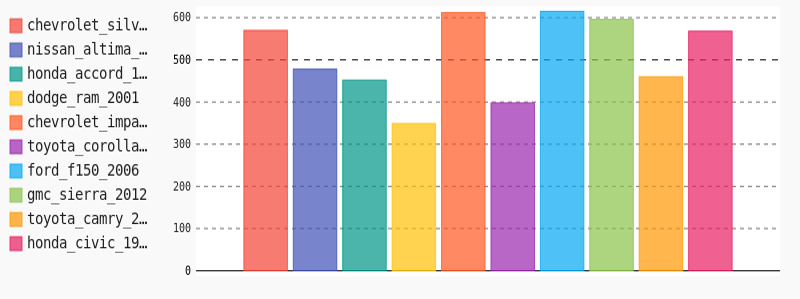 经过数据预处理和数据增强,各车型的数据量比较均衡了。
经过数据预处理和数据增强,各车型的数据量比较均衡了。
训练模型
选择框架
比较流行的框架有:TensorFlow(推荐)、Caffe(推荐)、PyTorch
我们选择TensorFlow框架,理由是:
- 开源,并且有很强的兼容性
- 对CPU有优化
- 推理平台多样(CPU/GPU/Movidius/FPGA)
- 图形可视化,Tensor Board的图形化能力很强
- 可以对网络进行局部Debug
- 更好的库管理,利用Keras可以很容易的迁移至TensorFlow2.0
 *PS:后来与现场的小伙伴们交流,Intel与Google有合作关系,所以Intel会优先推Google的TensorFlow。其实PyTorch现在发展势头很好,原因是门槛低,适合快速入门。并且TensorFlow新的版本已经开始借鉴PyTorch中一些比较好的设计了。
*PS:后来与现场的小伙伴们交流,Intel与Google有合作关系,所以Intel会优先推Google的TensorFlow。其实PyTorch现在发展势头很好,原因是门槛低,适合快速入门。并且TensorFlow新的版本已经开始借鉴PyTorch中一些比较好的设计了。
选择神经网络模型
训练和调参
导出模型
模型分析
边缘部署/推理
AI发展状况介绍,Intel提供哪些资源(广告较多,放在最后)
为什么要利用AI?
Data deluge(数据洪水)问题,每天产生的数据量:人产生25GB、智能汽车50GB、医院3TB、飞机40TB、智能工厂1PB…。这么多数据用人工只能达到很有限的广度和深度,最终只能靠AI。
什么是AI?
AI包含Machine Learning包含Deep Learning。一般都要经过训练(training)生成模型(model)最后进行推理(inference)。
hardware(硬广)
Intel提供CPU、集成GPU和计算棒或PCI计算卡。
绝大多数的业务使用CPU进行计算,但是随着计算量的增加,需要专用硬件进行计算。
软件
Intel提供一个工具集OpenVINO,可以将TensorFlow/Caffe2等框架计算好的模型进行部署,针对Intel的硬件生成优化代码,最终高效的进行推导。
社区
Intel提供一系列学习资源,支持AI社区的发展
https://software.intel.com/ai-academy
https://software.intel.com/ai/courses
https://software.intel.com/ai-academy/tools/devcloud
https://communities.intel.com/community/tech/intel-ai-academy
https://devmesh.intel.com
 会后讲师合影(左起:Derek Fattibene、Cao Huiyan、Pei Fanjiang、Gu Jianjun)
会后讲师合影(左起:Derek Fattibene、Cao Huiyan、Pei Fanjiang、Gu Jianjun)
 笔记还没有写完就收到了证书,惭愧呀!
笔记还没有写完就收到了证书,惭愧呀!![]() 一定要尽快完成总结!
一定要尽快完成总结!![]()