单机缓存的缺点问题
- 单个 Redis 服务器会发生单点故障(与高可用相反),一旦主机发生问题,整个系统无法提供服务
- 在读取、写入较多的情况下,一台服务器压力过大
- 单个服务器容量有限,一般来说单台 Redis 服务器最大使用内存不要超过 20G
分布式带来的好处
- 高可用。某些机器宕机,仍然可以使用服务。
- 高并发。对于网络服务普遍具有”读多写少”的特点,分布式可以同时并行处理很多读的请求。高并发的一些指标: _ 响应时间(Response Time)。例如 Tomcat,针对先到的用户先服务,例如 500 个,后边的就会等待(没有响应)。 _ 吞吐量(Throughout)单位时间成功传输的数据量 _ 每秒查询率(Query Per Second,QPS) _ 每秒事务率(Transaction Per Second,TPS),重点是完成的有效事务,比 QPS 小。 * 同时并发用户数
分布式的扩展方式
- 垂直扩展(Scale Up) _ 提升单机硬件处理能力,CPU、内存、SSD 硬盘 _ 提升单机架构性能,通过 Cache 减少 IO 次数、使用异步来增加服务吞吐率、使用无锁方式加快响应速度
垂直扩展部署简单、单机利用效率高,但是存在单点问题、造价高、维护成本高。当访问量达到一定程度时,就无法提供足够的服务性能。
- 水平扩展(Scale Out) * 增加主机
水平扩展没有单点问题,但是通信存在各种问题、管理复杂、没有统一的时钟,存在各种需要应对的挑战。
主从复制(Master-Slave)模式
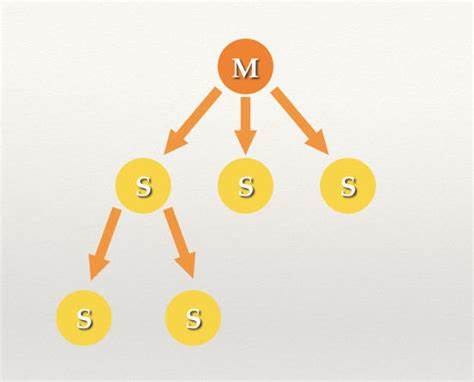 一个 Master 负责写、读,多个 Slave 与 Master 保持同步,负责读。Slave 可以作为别的 Slave 的 Master,形成链式结构。
一个 Master 负责写、读,多个 Slave 与 Master 保持同步,负责读。Slave 可以作为别的 Slave 的 Master,形成链式结构。
对于横向扩展(一个 Master 多个 Slave)的模式,随着 Slave 数量增加、Master 的读压力会增加,无法线性增加性能,优点是距离 Master 层级少、延迟小。
对于纵向扩展(一个 Master 多层 Slave)的模式,可以随机器增加线性增加并发性能,但是缺点是层级多、延迟大。
这种主从复制模式可以降低主的读压力,但是仍然存在单点问题。
哨兵(Sentinel)模式
哨兵是在主从复制基础上,增加了自动故障转移能力。
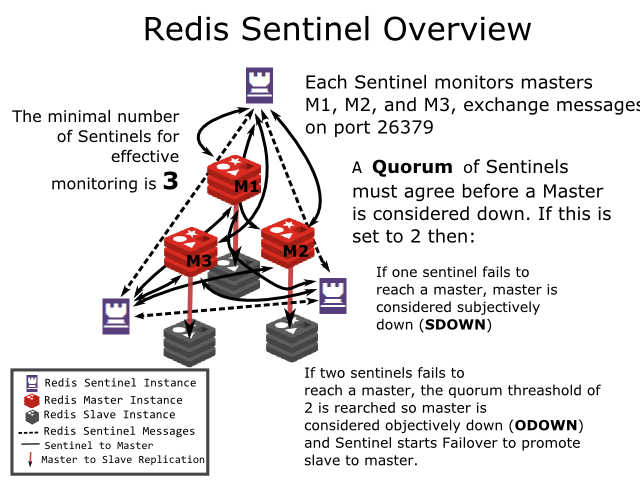 在 Redis3.0 之前,由于 Redis 没有集群模式,所以用哨兵模式应对 Master 宕机的情况。
在 Redis3.0 之前,由于 Redis 没有集群模式,所以用哨兵模式应对 Master 宕机的情况。
有一个 Master 和多个 Slave 和奇数个 Sentinel。当 Master 故障后,Sentinel 会进行投票(主观下线、客观下线),选择一个 Slave 做为 Master 继续提供服务。
这种做的好处是没有了单点问题,缺点是无法水平扩展。
集群模式(Cluster)
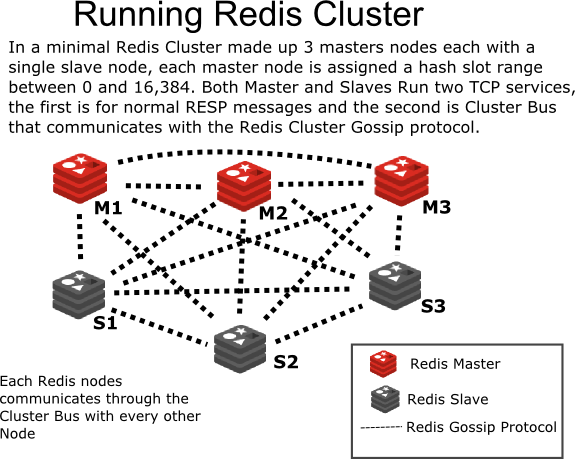 Redis3.0 版之后,提供了 Cluster 功能,可以进行水平扩展。Redis 的分布式模式较为先进,是无中心模式,每个节点都与其他节点连接、保存数据(属于自己的一部分)、保存整个集群的状态。
Redis3.0 版之后,提供了 Cluster 功能,可以进行水平扩展。Redis 的分布式模式较为先进,是无中心模式,每个节点都与其他节点连接、保存数据(属于自己的一部分)、保存整个集群的状态。
Redis 集群特点
- 所有节点彼此互联,内部以二进制协议优化传输速度和带宽
- 当集群中超过半数节点检测失败时才集群 fail
- 客户端不需要中间代理层,只需要连接任何一个可用节点即可,如果对应的 Key 不在直接连接的结点,该请求会被转发到对应的结点执行
- Redis-Cluster 把所有物理节点映射到[0~16383]个 slot(Hash 槽)上(不一定是平均分配),由 Cluster 负责维护
- Redis-Cluster 预分配好 16384 个哈希槽,当需要在 Redis 集群中放置一个 Key-Value 时, 会先对这个 Key 使用 CRC16 计算出一个数,然后对 16384 取余计算出哈希槽位置,然后将这个 Key-Value 放置到对应的节点上
集群容错
- 如果某个 Master 无法访问,则开始投票,投票过程是由集群中所有 Master 参与, 如果半数以上 Master 节点与某 Master 节点通信超时(cluster-node-timeout),认为当前 Master 节点挂掉。该 Master 的某个 Slave 将被选举成为 Master
- 如果任意 Master 挂掉而没有 Slave,则集群进入 fail 状态(因为 Hash-Slot 已经不完整了); 如果集群中超过半数以上 Master 挂掉,无论是否有 Slave,集群都进入 fail 状态
集群节点分配
起始三个节点的话,Hash-Slot 是平均分配的。当增加第四个节点时,会从每一个节点前面拿取一部分 Slot 到新节点。
- 新增或删除结点时,Hash-Slot 的迁移需要人工配置指定,然后涉及的 Key 会利用 pipeline 从旧主机逐个迁移到新主机,单个 Key 的迁移是原子的
如果迁移过程中有 Key 操作,则可能给客户端返回重定向
MOVED。
集群创建
Redis 官方提供了 redis-trib.rb 工具用于集群创建。至少需要 3 个 Master+3 个 Slave 共 6 个节点才能建立集群。
HashTag
集群模式的一个缺点是不同的 Key 分布在不同的主机,如果某个事务是由几个 Key 配合的就难以实现。
Redis Hash Tag提供了一个解决方案:在 Key 中加入{xxx}这样的形式,就可以先用 tag 做一次 Hash 决定主机,然后再执行剩下的 Hash。
这样就能保证 tag 相同的 Key 存储在同一个主机
- RedisHashTag 的基本规则是识别第一次出现的
{xxx}为 tag,比如000,{111},{222},{333},这里111被识别为 tag - 注意使用 tag 时,tag 不能影响第一次 hash 的离散度,比如
{type1:func1}:userId:123和type1:func1:{userId:123},后者就有更好的离散度,避免 HashSlide
分片模式
集群模式保证了高可用,在集群模式下,同时要考虑分片模式,分片模式的关键是容错性和扩展性。 分片模式的演化过程:简单 Hash -> 一致性 Hash -> Hash Slot(槽)
简单 Hash 算法
类似 HashTable 的实现,假设有三个节点对应的编号分别为 0 1 2。有任意整数 key,则所在节点编号 = key % 3。
- 缺点:
- 新增节点时由于 Key 的分布不均,会引起大量的缓存穿透,造成雪崩
一致性 Hash
整个哈希空间是一个虚拟圆环,现有节点经过计算,分布在圆环上。新增元素时,做一次 Hash 映射到圆环某点,然后顺时针找到最近的一个节点进行存储。
-
优点:
- 一个节点失效时,只会损失一部分元素
- 新增节点时,新增元素很容易找到新节点
-
缺点:
- 在节点较少的情况下,容易发生 Hash 倾斜(Hash Slide),多数元素被保存在同一个节点,导致这个节点成为整个系统的瓶颈
- 新增结点时,原先的数据可能分配在错误的结点上,需要按顺序访问两个结点才能找到 key,并且在迁移过程中不可以新增结点
-
方案:
- 对于 Hash Slide,可以在环上设置多个虚拟结点,虚拟结点再指向实际结点。类似 Hash Slot 方案。
-
实现:
- 可以用
数组+二分查找的方式实现 Hash 环结点查找 - 也可以用跳表/B+树实现,它们的共同特点是叶子结点有链表结构,可以向前后查询
- 其中 B+ 树内中间结点的查找可以用二分查找,进一步提高效率
- 可以用
Hash Slot(Hash 槽)
redis cluster 包含了 16384 个哈希槽,每个 key 通过第一次计算后都会落在具体一个槽位上,然后再计算第二次保存在槽位内的存储位置。 用户可以根据硬件的配置,设置 Redis 集群节点的槽位数。槽位的序号在每个节点并不是单纯的顺序,而是有一定的穿插分布,这样很好的避免了 Hash 倾斜问题。
不同模式 Redis 性能比较
并不是主机越多越好,要根据情况部署 Redis
- 同主机 和访问服务部署在同一个主机,根据主机性能不同,可以达到 10W~100W QPS
- 同物理局域网 4W QPS
-
云主机/NAT 100~1000 QPS
- 关于极端外部环境下的高可用和高并发: 即使是分布式 Redis,必须在一个物理数据中心部署,所以”网线挖断”、”地震”等问题,只能通过降级应对,无法同时满足高可用和高并发