什么是缓存穿透
为了提高热点数据的查询效率,我们将热点数据从 Mysql 数据库加载(预热)到 Redis 缓存中,以便快速查询。但是少数情况,在缓存中查询不到,还是要到数据库中查询,效率非常低。
这种情况如果能从数据库查询出还算好,但是如果是大量无效数据,每一个一定会去数据库找一圈,会导致查询性能急剧下降甚至崩溃。这就是缓存穿透问题。
导致缓存穿透的原因
- 恶意攻击。通过程序寻找本来不存在的 ID 值,损耗服务性能。
- 用户输入错误,比如错误的邮箱号。
- 未来的及预热就发生了查询。
解决思路
- 主要方法
- 对一些无效 ID,在缓存内保留,但是只保留 ID 而值为空,这样也可以防止热点错误 ID 导致的穿透。在这种情况下,要设定合理的有效时间,避免过多积累,导致内存被占满。另外要有根据内存情况的主动删除机制,避免恶意攻击导致的内存占满。
- 把所有 ID 都加载到内存里,放在 HashTable 中进行存在检测。但是这种需要容量较大,有更好的方案——布隆过滤器。
- 辅助方法
- 识别热点数据,服务器启动时尽快预热,加载到 Redis 缓存中。
- 规范 ID 名,在前台进行正则过滤,比如 ID 如果是正整数,那么前台可以过滤掉负数。
- 在后台有统一的查询和写入的入口,再次进行正则过滤,避免恶意攻击,前台没有过滤到。
- 进行是否存在的查询时,要进行同步操作,避免命中并加载到缓存中的 ID 在并发下引起数据库查询。(穿透+击穿)
服务端增强方案 Bloom Filter(布隆过滤器)
布隆过滤器可以对较大数量的 ID 进行过滤,能够识别该 ID 在集合中是否 一定没出现过 。
原理
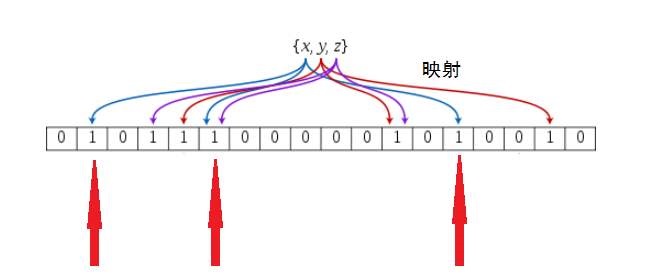
布隆过滤器 = 一个 bool 类型的数组 + 多个不同的 Hash 函数
布隆过滤器使用过程:
- 首先要用集合的每个元素(x y z)执行所有 Hash 函数,在校验数组中留下自己对应的散列痕迹。
- 当一个未知的元素(a)需要校验时,同样执行所有 Hash 函数,然后判断每个函数的散列结果是否在数组中已存在。
- 如果所有散列点都存在,那么认为基本命中,可以进行跟深一步的校验(例如到 Redis、Mysql 进行查找)。
- 如果有某一个散列点不存在,那就说明这个元素在集合中不存在。
特点
- 建立校验数组过程比较慢,需要把所有集合中的元素对所有 Hash 函数执行一遍
- 这个创建过程不可逆,不可以删除集合元素
- 存在误判情况,存在一个误判率 FP(碰撞率)
- 校验数组可能占用较大空间
设计点
增加数组容量、增加 Hash 函数种类都可以降低碰撞率,但是这之间要有权衡,如何达到最优化而不是盲目追求 0 碰撞率(那样就成了 HashTable 了)。
- 根据具体数据类型,选择合适的 Hash 函数,可以降低 FP
- 根据自己的业务特点,只要将 FP 降低到一定程度,就可以满足需求
最佳实践
- 对于 java,可以使用 Google 提供的 guava 包,里面提供了很好的布隆过滤器的实现,可以直接调节 FP(错误率)。
- Go,可以使用willf/bloom,其中 FP 的控制需要自己调节参数实现。
改进
-
新增 key 在向数据库添加一个新的 key 后,要向 Bloom Filter 添加相应地 key,这样过滤器能持续起作用。如果没有及时添加,那这个 key 就会被认为是不存在,在查询时不能及时查到。
-
删除 key 布隆过滤器一般用于 ID 只增不减的情况,因为删除比较麻烦,从数据库删除后没有从过滤器中删除,这时在二次读取缓存后可以判断是否存在。 如果 key 值存在删除的情况,那么 Bloom Filter 中无效的 key 会越来越多,主要问题是占用容量,次要问题是造成不必要的多余查询。 如果需要删除集合中的 ID 该怎么做呢?可以给 bool 数组绑定一个同样元素数量的用于计数的数组,根据情况,比如 short 型。 在生成校验数组同时,维护每一个校验位对应的次数统计。这样删除 ID 时,就可以在对应的计数数组中减 1,如果减到 0,则校验数组对应位置置 0(false)。 显然的,这样会增加容量,但是特定业务可能需要这样做。
-
定期新构建 对于没有实现删除功能的 Bloom Filter,可以定期重新构建,这样可以避免逻辑复杂、多占容量。这种情况下,要设定好重建时机、重建频率。