记录 Go 与 C++等语言的差异语法点
类型转换
- Go 的类型要求非常严格,类型转换必须显式执行。在 C++中一些常用的默认转换在 Go 中要注意转换
num := 0 // int 型
num = int('9' - '0') // 这里要将 rune 型显示转换为 int
char := rune(num) // int 可以转换为 rune
指针
- Go 中指针是强类型,如果 B 内嵌了 A,那么 A 的指针不可以指向 B。只能利用 interface 进行指向
值类型和引用类型
这种分类只是一种粗略的方法,实际底层都是数据的拷贝,只是拷贝指针和拷贝对象的差异。 这里的关注点是对指针进行拷贝的效率较高,对对象拷贝的效率较低。
- 值类型:变量直接存储,内存通常在栈中分配(特殊情况也可以在堆上)
- 基本数据类型 int、float、bool、string 以及数组和 struct
- 引用类型:变量存储的是一个地址,这个地址存储最终的值。(大容量部分的)内存通常在堆上分配。通过 GC 回收
- 引用类型:指针、interface、slice、map、chan
- 指针不是一般的数据类型,其内的值不能直接以地址值修改
- slice 传参时,本质是对象复制,所以变更 len、扩容,都会导致函数内外对象不一致
- 指针、interface 和 slice 一样,都是按值传参,只不过本身有指针性质
- map、chan 与上面不同,其底层类型是指针型,Go 为其自动增加了
*操作,相当于 C++中的引用类型。所以函数内外,对 map 和 chan 变量除了赋值操作外都可以保持对象的一致性。
++/–
Go 为了避免语法上过于复杂,不允许++/--运算有”副作用”,x++/x--是语句而不是表达式,并且符号只允许放在变量右边。
// C++ 代码
int i = 0
int j = 0
j = --i
上面的j = --i在 Go 里表达为:
i--
j = i
内置函数
1 | |
string
-
string 直接取下标时和 byte(uint8) 数组是等价的
- 例如
b1 := s[2],byte类型 - 例如
s1 := s[2:3],string类型
- 例如
-
利用 range 遍历 string 时,value 类型是 rune(int32)
literal
- string 的字面表示一般用
"content",其中可以使用转义符如'\n',还可以用下面方法表示 unicode 字符:'\u65e5''\U00101234''\xFF'表示一个字节字符0xFF=255'\377'用三个数字表示一个 unicode
- 也可以用’`‘进行 raw 表示,可以跨行、会忽略其中的转义符
表示多行字符串
// 用英文反引号
x := `
这是一行文本
这是一行文本
这是一行文本
`
- 注意,这种方式定义的字符串中无法包’`‘,因为这个字符不允许 escape
- 可以用多行相加的方式在”“里包含’`’
range
- 对 string 进行 for range 可以得到每个字符的起始字节下标和字符 rune 值
s := "你,好啊!"
for pos, char := range s {
// pos是字符下标、char是rune值、s[pos]也可以取得rune值
}
修改 string 中的字符
string是常量字符串,无法修改其中的值,只能通过[]byte作为中间过程
s := "hello"
// s[0] = 'x' 直接这样赋值将编译不通过
s1 := []byte(s) // 这里实际上发生了数据拷贝,因为string类型是只读的
s1[0] = 'x'
s2 := string(s1)
fmt.Println(string(s2))
-
string 是常量的好处
- 方便内存共享,只有一份对象即可
- 字符串的 hash 只需要一份
-
如果 string 中存储的是中文,那么用
[]byte作为中间类型操作会导致乱码,可以用[]rune作为中间类型解决
关于线程安全
string 的结构体如下:
type string struct {
array unsafe.Pointer // 元素指针
len int // 长度
}
可以看到底层由两个变量组成,所以在读取、写入同时发生时,是线程不安全的,有可能发生只读到一部分最新值的情况
逻辑选择
for
- for 循环中 break、continue 都可以加 label,直接跳转到某层 for(停止/继续)。跳转的目的 label 必须在某个 for 的外面,形成包围(enclosing)的形式。
- 注意 label 必须在 for 之前声明,详情见 label 语法
OuterLoop:
for i = 0; i < n; i++ {
for j = 0; j < m; j++ {
switch a[i][j] {
case nil:
state = Error
break OuterLoop
case item:
state = Found
break OuterLoop
}
}
}
- for 与 range 结合时,注意临时对象在当作右值时不要传地址,否则很可能发生逻辑错误
- for 与 range 结合时,如果数组元素的类型是对象而不是指针,注意使用下标修改元素内容,否则只作用于临时对象,修改无效
for _, obj := range objectArray {
// 这里将导致 leftArray 中的元素地址全部是临时对象地址
leftArray = append(leftArray, &obj)
obj.A = 1 // 如果 obj 是对象而不是指针,那么成员赋值也不起作用,只会修改临时对象
}
- 上面循环共享变量的问题在
1.22版本修正,从此每次循环都将使用新变量,避免出现误解
switch
- Go 中 switch 的每个 case 后会自动添加 break,所以会独立执行。如果想要连续执行,可以使用 fallthrough 语句。
- switch 中 每个 case 可以有多个或者关系的匹配项,用
,隔开,如:
switch value {
case 1, 2, 3:
// xxx
case 4:
// xxx
}
- Go 中类型要求很严格,switch 比较时会同时比较类型,所以类型一定要完全匹配。
const caseValue1 = 20
obj := int64(20)
switch obj {
case caseValue1:
// 不会走这里,caseValue1 默认为 int 型
default:
// 会走这里,因为类型不完全匹配
}
- switch 紧跟的目标变量/表达式如果忽略,则表示 true,只要后面的 case 表达式为条件表达式即可,顺序执行比较
switch {
case x < y: f1()
case x < z: f2()
case x == 4: f3()
}
- switch 和 for 类似,第一行可以加初始化语句
switch x := f(); x {
case 5: return -x
default: return x
}
select
select 相当于在线程阻塞方面的 switch,以往由操作系统提供,现在直接在语言层面实现
- select 其中的 case 可以是从 channel 读取也可以是向 chennel 写入,多个 case 之间如果同时可发生则随机选择一个
- 有 default 的情况下,并不会阻塞,没有会继续执行
select {}表示永久阻塞- select 会隐含自动使用 break 语句,所以在其中使用 break 语句会被 select”吸收”而不会传到到外层的 for 循环,需要用 break label 解决
label
label 声明后可用于goto/break/continue语句后边
- goto 语句后边表示当前执行跳转到指定行
- label 用于 break 和 continue 表示 break、continue 所作用的逻辑循环
for/switch/select,所以 label 声明所在位置应在想起作用的循环范围外 - label 要在 break 和 continue 起作用时,要放在
for/switch/select前面,并且中间不能有其他语句,否则会发生”label 未定义”的编译错误;在goto时,label 可以定义在任何位置。
loop:
for {
for {
break loop
}
}
channel
- 双向 channel
chan int;只写 channelchan<- int;只读 channel<-chan int;”双向”可转换为任意”单向” - 以 channel 作为 channel 传递的内容,也就是以 channel 作为 channel 的类型,如:
chan<- <-chan int等价于chan<- (<-chan int) - 已经 close 之后的 chan 无论是写入还是再执行 close,都会发生 panic
- 已经 close 之后的 chan,读取时会立即返回默认 0 值,第二个参数为 false(表示已 close)
- 给一个 nil chan 发送数据,会永久阻塞
-
从一个 nil chan 读取数据,会永久阻塞
-
len()、cap()作用于 chan 时,可以取得已经缓存的消息数量和 buffer 容量。
- 使用 range 语法取出 chan 的值时可以自动监听 close 状态并退出循环
关于 chan 的传参
chan 的初始化底层实现:func makechan(t *chantype, size int) *hchan,它和 map 一样,都是引用型(指针类型,自动前面加*)。
for x := range ch {
// use x
}
// ch is closed
- 利用 nil channel 可以进行一些线程设计
func add(c chan int) {
sum := 0
t := time.After(1 * time.Second)
for {
select {
case val := <-c:
sum = sum + val
case <-t:
c = nil // 从此之后阻断 c 的读取
fmt.Println(sum)
}
}
}
channel 底层实现原理
如果我们创建一个带 buffer 的 channel,底层的数据模型如下图:
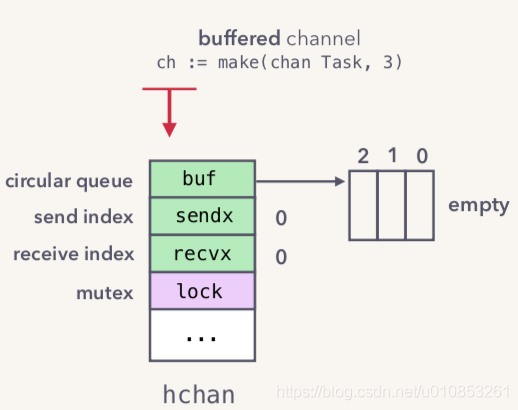
- 写入、读取数据时,都会用到右边的 circular queue(环形队列)
- channel 的读写过程,都是基于 mutex 的
- 在读取、写入时,都会进行数据的拷贝,share memory by communication
- 当发生阻塞时,会主动调用 scheduler 进行调度,把 M 与 G 分离,将 G 放入等待队列
- 写入、读取如果被阻塞,会有一个队列,用来存放被阻塞的 G,之后从队列中唤醒
- close 时,所有读/写等待队列的 goroutine 会被唤醒
- close 后再次 close 写会发起 panic
短声明(short declaration)符号:=
- := 短声明符号,(非 if/for 声明位置)在左边的变量已经存在的情况下,会做一些兼容操作:
- 如果左边的多个变量,在本域中有没声名的也有已声明的,那么对已经声明的只做赋值运算
- 如果左边的多个变量,其中有在外域中声明的,则创建一个新的变量
- 如果变量都是当前作用域已声明的,会报错,要求使用
=符号
- 注意对于 if 和 for 语句开头的短声明,所有外部变量都会被覆盖为新变量,这种被覆盖的变量编译器难以察觉,叫做”阴影中的变量”(shadowing variable)。 可以用下面工具检测代码中是否存在 shadowing variable。
1 | |
具名返回值
- 可以提前给返回值命名,在函数中作为局部变量使用。如果一个具名,那么所有返回值都要具名
- return 时可以直接 return,这样之前返回值变量是什么值就是什么值
- return 时也可以重新覆盖一遍返回值
func test() (x int, err error) {
x = 1
if err!= nil {
return
} else {
return 2, nil
}
}
array
go 中 array 只能用常量初始化(创建),不可以直接在代码中通过变量创建动态长度的数组。通常使用 slice 代替 array。
- 在 Go 中,允许使用数组指针时无需加
*,例如var p &[3]int // 定义指针 (*p)[1] = 2 // 正常用法 p[1] = 2 // 省略'*'这种行为类似 struct 无需加
*
slice
slice 对象有三个字段:数组指针、length、capacity。
- 通过一个 slice 可以创建一个新的 slice
sl2 := sl1[1:2],那么两个 slice 的数组指针指向同一个数组 - 此时如果通过下标赋值,两个 slice 可以相互影响
- 如果新的 slice 不断 append 导致数组重新申请,则数组指针会指向不同数组
- 所以在使用 slice 作为参数时,不能指望通过副作用改变原有 slice。可以直接返回新 slice 或传入
*[]int
s := []int{1, 2}
s = append(s, 4, 5, 6)
// 这时 len == 5, cap == 6,并不是 2^n
- slice 只能通过 append 函数添加元素,该函数返回一个更新后的 slice,编译器不允许不使用 append 的返回值,否则编译出错
- append 的第一个参数是可能被改变的,如果容量允许,则会在第一个参数 slice 的基础上追加
- append 的第二个参数是只读的
- slice 扩容过程:在 1024 个元素之前,每次扩容翻倍;在 1024 个元素后,每次以 1.25 倍扩容
- 上面的扩容过程并不准确,实际上扩容受 append 元素数量的影响;另外,超过 1024 个元素后,申请的新容量会对指针 size 进行字节对齐处理,所以并不一定是 1.25 倍,往往更大一些
- slice 还可能发生缩容,如果一直向后执行
[x:]操作,底层数组指针会指向新的地址同时容量缩小;之前的数组如果没有引用了,会被释放。
s1 := []int{0,1,2,3,4,5}
s2 := s1[1:3] // {1, 2} = [1,3) 取左闭右开区间
-
用 append 给数组或 slice 添加元素:
sli = append(sli, element),添加整个 slice 的元素时sli = append(sli, sli1...) - 数组清空时,可以用
a = a[:0],这样可以复用原有空间实现清空 -
删除中间元素(第 k 个元素):
a = append(a[:k], a[k+1:]...) - 可以创建多维数组或 slice
threeDSlice := [][][]int{ { {1} } } // 为了 jekyll 正确生成,这里把'{'间增加了空格
- slice 的值为 nil 是有效的,一般要用
len(sli)来判断切片是否为空,不要用sli == nil。 - slice 为 nil 时,有可能是 len 为 0 的 slice 已经创建好了,也可能是没有创建好
- map[string][]string,对未初始化的 Key 读取时,取得的是真的 nil,进行赋值动作时,会自动创建 len 为 0 的 slice
testSli := []int{2:2, 3, 0:7, 8}
- 用字面值初始化 slice 时,可以指定下标
- 如果中间有没有指定下标的元素,下标是前面元素下标+1
sli1 := make([]int, 5, 10) // make 返回被初始化好的 slice,len 为 5, cap 为 10
sli2 := make([]int, 2) // 创建一个 len 为 2,cap 为 2 的 slice
- 使用 make 初始化 slice 时,至少要传一个 size 参数,表示 len
slice 完整表达式
a[low : high : max]
array 或 slice 都可以用上面表达式,返回一个新的 slice,取值范围:0 <= low <= high <= max <= cap(a)
- 其实我们平时使用的
sli2 := sli1[0:5]就是上面表达式的一部分,cap 被默认填写了,而high的范围可以超过len(sli1) - 使用完整表达式时,各个参数要合法,否则会引起 panic
a := [5]int{1, 2, 3, 4, 5}
t := a[1:3:5]
fmt.Println(t, len(t), cap(t)) // [2,3] 2 4
slice 字面量定义
由于 Go 编译时会根据最后一个符号判断是否换行编译,所以下面这种定义方式会无法编译通过:
x := []int{
1, 2, 3,
4, 5, 6 // 这里缺少','或'}'
}
正确的方式应该是下面两种:
x := []int{
1, 2, 3,
4, 5, 6, // 多余的','会被自动忽略,不影响编译
}
x := []int{
1, 2, 3,
4, 5, 6} // 有'}'被识别为列举结束
copy
内置函数 copy 可以在 slice 间拷贝元素,相当于 for 循环把源 slice 全部元素拷贝到目标 slice,覆盖目标 slice 从第一个元素开始的元素。
copy 函数会拷贝min(len(dst), len(src))的长度,并将拷贝长度返回
copy(dst, src []T) int
copy(dst []byte, src string) int
Perfect Copy
copy在具体执行时,有下面两种方式:
// 方式 1
b = make([]T, len(a))
copy(b, a)
// 方式 2
b = append([]T(nil), a...)
- 方式 1,如果 a 本身是 nil,则会创建一个 sliceEmpty 对象,有多余性能消耗
- 方式 2,如果 a 本身有很多元素,而目标是个 nil,在逐个 copy 的过程中逐步扩容,造成不必要的性能消耗
如果考虑上面因素,可以这样创建:
var b []T
if len(a) != 0 {
b = make([]T, len(a))
copy(b, a)
}
其实用下面方式可以实现Perfect Copy
b = append(a[:0:0], a...)
这里[:0:0]是官方支持的语法糖,表示根据 a 的情况自动申请 slice 空间。如果 a 为 nil 则不申请,反之则申请。
这样只需 1 行就可以简洁的实现上面 5 行相同的功能。
可变参数
函数的最后一个参数可以是可变参数类型,其本质是一个特定类型的 slice
func appendInt(x []int, y ...int) {
// y can be used as []int type
}
a, b, c []int
b = appendInt(a, 1, 2, 3)
c = appendInt(a, b...)
const
Go 中的 const 并不表示此变量之后不允许修改,而是真的表示”这是个常量”
func f(arr []int) {
const N = len(arr) // 编译报错,必须填写常量
}
- Go 中无法定义常量数组、常量指针
- 利用 iota 可以方便的定义枚举常量
type ByteSize float64
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 1 << (10*7)
YB // 1 << (10*8)
)
-
iota 过程中如果遇到自定义常量则暂停 iota 但继续计数, 打断时的常量为 A,则后面的常量都会被设置为 A,直到新的 iota 后继续 iota
-
const 定义时可以带类型也可以不带
const Pi float64 = 3.14159265358979323846
const zero = 0.0
- const 常量的初始化只能用字面量初始化,不可以是执行某个函数后初始化
未确定类型常量
const s = "Go101.org"
var a byte = 1 << len(s) / 128
var b byte = 1 << len(s[:]) / 128
func main() {
println(a, b) // 4 0
}
- const 类型在编译期会保持字面量而不确定类型,这时实际的类型会足够大,不会损失信息,比如保存 Pai 值
- a 所在行,由于 s 是未确定类型,
len(s)可以在编译期确定值为9,所以右边表示常量1 << 9 / 128,最终表示为 byte 值为4 - b 所在行,由于
len(s[:])要在运行时确定值,所以无法在编译期运算。根据左边的b先确定了1是byte类型,1 << 9已经溢出,再执行/128仍然为 0
struct
tag
- struct 可以对字段加 tag,以便通过反射进行序列化和反序列化操作,基本格式:
json:"name" - struct 做序列化时,可以同时设置多种 tag(空格分割) 以便对不同数据源序列化
type TestStruct struct{
Name string `json:"name" yaml:"name"`
Age int `json:"age" yaml:"age"`
}
func main(){
t := TestStruct{Name:"test", Age:10}
// 序列化时会根据 tag 序列化
json.Marshal(t)
}
UnkeyedLiterals
在初始化时,可以直接传入参数而不用指定成员名称,如x := TestStruct{param1, param2},literal 数量、参数与成员必须完全一致。
-
这种 literal 初始化方法有三个隐患:
- 如果 struct 定义中成员顺序改变,会导致初始化代码逻辑错误,而且无法发现
- 如果新增成员,会导致初始化代码编译不过(数量不足)
- 没有写明,也会导致可读性变差
-
为了让 literal 初始化时强制带 key,可以参考 Protobuf 的 NoUnkeyedLiterals 实现方式:
type User struct{ _ struct{} Age int Address string } func main(){ _ = &User{21, "beijing"} // 编译不过 }- 由于参数数量不足,编译不过
- 由于成员名为
_不会导出,所以无法用{struct{}{}, 21, "beijing"}的方式初始化
匿名 struct
- 匿名 struct 用于只用一次的结构体类型
- 匿名 struct 可以用嵌套结构
func main() {
S := struct {
A int
B string
C {
D int
E string
}
} { A: 10, B:"aa"
C: {
D: 11
E: "bb"
}
}
}
Receiver
- Receiver 的本质是给函数增加一个隐形的第一个参数
type test struct{
name string
}
func (t test) TestValue() {
fmt.Printf("%p\n", &t)
}
func (t *test) TestPointer() {
fmt.Printf("%p\n", t)
}
func main(){
t := test{}
fmt.Printf("%p\n", &t) // 0xc42000e2c0
m := test.TestValue
m(t) // 0xc42000e2e0 与原地址不同
m1 := (*test).TestPointer
m1(&t) // 0xc42000e2c0
}
- 值类型的 Receiver 意味着按照拷贝传值,所以 Method 调用后可能不会修改对象本身
- slice 这种引用类型有可能会修改原值内容
type Test struct {
A int
}
func (t Test) Change() {
t.A = 5
}
test := Test{}
fmt.Printf("%v", test.A) // 0
test.Change()
fmt.Printf("%v", test.A) // 实际是 0,并不是 5
-
通常 Receiver 定义为指针类型,这样有三个好处:
- 避免值拷贝耗时
- 可以直接修改目标值,避免修改无效。(指针类型类似 C++ this 指针)
- 注意:Receiver 为指针类型时,nil 指针是可以调用 Method 的
- 通常不会对 Method 的指针 Receiver 参数做 nil 检查,如果依赖成员变量,则一定会 panic,这和 nil 指针直接调用 Method 时 panic 是一样的; 如果不依赖成员变量,则可以看作是 java 中的 static method,提供通用函数。
- 带类型的(非空) interface 被赋值时,要求变量的类型要与 receiver 的类型保持兼容性,否则编译不通过。
- receiver 的类型为 值类型 时,赋给 interface 的变量可以为值或指针。 由于是值类型,调用 method 时不会改变成员变量,所以编译期自动执行合适的调用,不会有问题。
- receiver 的类型为 指针型 时,赋给 interface 的变量只能为指针。 如果传值,从 method 理解应该可以改变成员变量,但实际上改变不了,所以干脆编译不通过,避免歧义。
type MyInterface1 interface {
Test1(i int)
}
type MyInterface2 interface {
Test2(i int)
}
type MyStruct1 struct {
A int
}
func (p MyStruct1) Test1(i int) {
p.A = i
}
func (p *MyStruct1) Test2(i int) {
p.A = i
}
func main() {
var a MyInterface1
var b MyInterface2
var d MyInterface1
c := MyStruct1{}
c.Test1(1)
log.Println("c", c)
a = c
a.Test1(2)
log.Println("a", a)
b = &c
b.Test2(3)
log.Println("b", b)
d = &c
d.Test1(4)
log.Println("d", d)
// 最终输出 c {0} a {0} b &{3} d &{3}
}
- 不论 Receiver 为值类型、指针类型,使用值、指针都可以调用,编译期会自动使用合适的调用方式
type MyInt int
// 这里 MyInt 或 *MyInt 都可以编译通过
func (a *MyInt) Test(){
fmt.Println(*a)
}
// 下面两种方法都是合法的,在编译期自动决定传入合适的 Receiver 实参
var a MyInt
var pa = &a
a.Test()
pa.Test()
由 Interface 进行调用,会自动转换,兼容各种类型:
type MyInterface interface {
Test()
}
type MyInt int
func (a MyInt) Test(){
fmt.Println(a)
}
var a MyInt
var i MyInterface = &a
i.Test() // 自动进行各种类型转换,怎么调用都可以
interface
interface是 Go 中特有的数据类型,它由两部分组成:类型+数据,用法类似 C++中的对象指针,可以由父类指针指向子类对象。
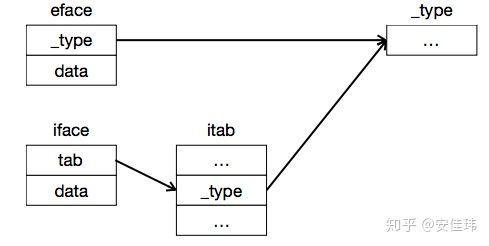
- interface 在底层有两种可能的数据结构 eface(empty interface) 和 iface,其中 eface 表示
interface{},iface 表示至少带有一个函数的 interface,由编译器决定使用哪种数据类型 - _type 指针指向实际类型描述
- data 表示数据指针
- tab 指向 itab 结构
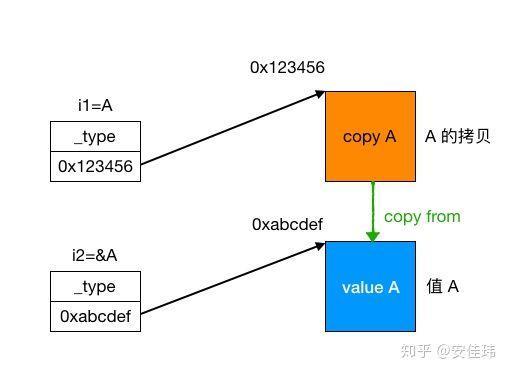
- 如果实际类型是一个值,interface 会在堆上为这个值分配一块内存、复制,然后用 data 指向它
- 如果实际类型是一个指针,那么 interface 会把指针的值(也就是对象的地址)保存在 data
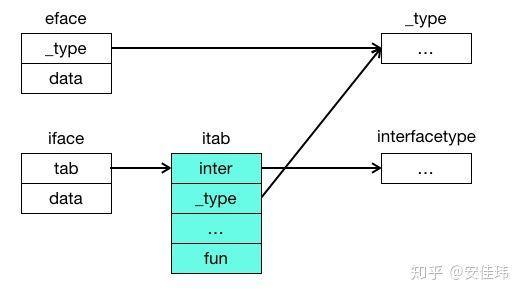 itab 表示 interface 和 实际类型的转换信息。对于每个 interface 和实际类型,只要在代码中存在引用关系, go 就会在运行时为这一对具体的
itab 表示 interface 和 实际类型的转换信息。对于每个 interface 和实际类型,只要在代码中存在引用关系, go 就会在运行时为这一对具体的 <Interface, Type> 生成 itab 信息。
- inter 指向对应的 interface 的类型信息
- type 和 eface 中的一样,指向的是实际类型的描述信息 _type
- fun 为函数列表,表示对于该特定的实际类型而言,interface 中所有函数的地址
-
由于 fun 是运行时生成的,所以假设 interface 有 m 个函数、struct 有 n 个函数,那么构建过程的双重遍历时间复杂度为 O(m*n)。由于编译器在编译期对函数名进行了排序,所以实际时间复杂度是 O(m+n)
interface{}是一种特殊的 interface, 它的==比较会根据实际类型执行。 如果interface{}的实际类型是指针类型,则会比较 data 指针;如果interface{}的类型是对象类型,则会对 data 指针指向的对象做比较;
interface 特性
interface{}类型的变量被真实类型赋值时,本质是赋值了指针,所以对原变量值的修改后,interface{}中的值也会变更- interface 变量之间比较时,type、data 都相等时才相等
interface 强转
- 强制类型转换是否可以成功,需要在运行时才能决定,无法在编译期判断
- 可以用
value, ok = i.(int)尝试强制转换,如果转换失败则ok == false、value为默认值 - 可以直接用
i.(int) == 5这种形式转为目标类型,这里没有转换错误判断,所以一旦类型错误将抛出 panic - 如果转换目标类型为结构体指针,如
i.(*MyStruct),这种形式也叫对象类型查询,用来判断接口指向的实例是否为*MyStruct类型或内嵌了MyStruct的指针类型 - 如果转换目标类型为 Interface 类型,如
i.(MyInterface),这种形式也叫接口查询,用来判断接口指向的实例是否符合MyInterface接口
// 用下面形式可以进行对象类型查询或接口查询
var i interface{}
// i = xxx
switch val := i.(type) {
case int:
val += 1 // 类型已经确定,可以做运算
fmt.Println("int", val)
case MyInterface:
fmt.Println("MyInterface", val.GetValue())
default:
fmt.Println("can not found type of %v %T", val, i)
}
interface{} 和 any
any 是 G1.19 版本引入泛型时同时引入的别名。它比原来的interface{}更容易被理解,应尽量使用 any。
method set(方法集)
官方说明:method set
| 变量类型 | 方法集包含的 receiver 类型 |
|---|---|
T |
(t T) |
*T |
(t T) + (t *T) |
只有一个变量的类型的方法集完全涵盖了 interface 的方法集后,这个类型才会被认为是 interface 的实现类型。
-
确定当前编辑的 struct 已实现指定接口的小技巧: 在定义某个 struct 时,可以在结构体下方、实现方法集函数前进行类型校验:
var _ error = TestStruct{} var _ error = (*TestStruct)(nil)
embedded field(嵌入字段)
可以通过嵌入字段的方式实现”组合”
struct {
T1 // field name is T1
*T2 // field name is T2
P.T3 // field name is T3
*P.T4 // field name is T4
x, y int // field names are x and y
}
-
字段的类型要符合原类型的 Receiver 类型,否则在对象拷贝过程中可能发生未知的错误(例如
*list.List) -
多层嵌入情况下,在调用时,只要字段名、函数名不冲突,可以用多种方式调用
type minHeap struct {
sort.IntSlice
}
func (p *minHeap) Push(x interface{}) {
p.IntSlice = append(p.IntSlice, x.(int))
}
func (p *minHeap) Pop() interface{} {
ret, p.IntSlice := p.IntSlice[len(p.IntSlice)-1], p.IntSlice[:len(p.IntSlice)-1]
return ret
}
type maxHeap struct {
minHeap
}
func (p *maxHeap) Less(a, b int) bool {
return p.IntSlice[a] > p.IntSlice[b]
}
func main() {
maxH := &minHeap{}
// 下面的调用都是合法的:
fmt.Println(maxH.Pop())
fmt.Println(maxH.minHeap.Pop())
fmt.Println(maxH.Len())
fmt.Println(maxH.minHeap.Len())
fmt.Println(maxH.minHeap.IntSlice.Len())
fmt.Println(maxH.IntSlice.Len())
}
- 大坑如果多层结构体嵌套(无论是否为
*类型),如果有字段名冲突,则在json.Mushal()时会无法导出字段,而且不会报任何错误…
selector
obj.A中的.就是 selector
- Go 的一个语法糖:使用 selector 调用时,会自动根据 receiver 类型进行取址/取值操作
init
在包中可以添加init函数,用于对包环境进行初始化。利用import _ "xxx/xxx"语句可以强制导入包进行初始化,但不调用。
type
- 可以利用 type 可以对原类型重新声明,原类型可以是已经重新声明过的,重定义时
=可以省略
type myTypeA string
type myTypeB myTypeA
type myTypeC = myTypeB
- 重新类型声明不会继承原类型的函数,如果想继承成员的同时继承函数,可以使用”匿名嵌入”
1 | |
数字的字面表示前缀(number literal prefixes)
Go 1.13 增加了一些常用的不同进制字面表示方法:
// 0b 或 0B 表示二进制
0b0101
// 0 或 0o 表示8进制
0o720
// 0x 或 0X 表示16进制
0xAA
^符号的两个用法
- 通常
^表示按位异或运算 - 在 Golang 中,如果作为一元运算符出现,表示
按位取反。(在其他语言中通常以~表示)
&^按位清零运算符
这种运算可以用于将组合标志位变量的某个标志位清零。
// 下面以单个位来演示
0 &^ 0 => 0
1 &^ 0 => 1
0 &^ 1 => 0
1 &^ 1 => 0
// 右边为1时,会将左边的操作数清零;
// 右边为0时,不处理。
x := 0b1111 // 111
x = x &^ (1 << 1) // x => 0b1101
用==比较数组/struct
- 相同类型、元素数量一致的数组才能比较
- 每个元素用
==比较都相同时结果才是 true - struct 也可以比较,只要其中的成员都是可比较的就可以
- 虽然 struct 中的成员是可比较的,但是一定要搞清有哪些类型的成员。比如 time.Time 有专门的 Equals 比较函数,这时用 == 比较时就可能出错。
参考:
http://docs.golang.com/doc/effective_go.html
container
make
make 是 Go 内置的初始化函数,可以初始化 slice、map、channel
// 函数声明,第二个参数用来控制"容量"相关
func make(t Type, size ...IntegerType) Type
- 对于 slice,至少要传两个参数,第二个参数表示长度,第三个参数表示容量。如果只传第二个参数,则同时表示长度和容量。
- 对于 map,至少传一个参数,初始化时会分配一定的容量,如果设定第二个参数,则会初始化一个接近的容量。
-
对于 chan,可以只传一个参数,第二个参数表示缓冲区容量
- make 和 new 的区别
- make
- 能够分配并初始化类型所需的内存空间和结构,返回引用类型的本身。
- 具有使用范围的局限性,仅支持 channel、map、slice 三种类型。
- 具有独特的优势,make 函数会对三种类型的内部数据结构(长度、容量等)赋值。
- new
- 能够分配类型所需的内存空间,返回指针引用(指向内存的指针)。
- 可被替代,能够通过字面值快速初始化。
- new 返回的指针指向的内存在堆上还是栈上要由”逃逸分析”决定
- 一般可以通过 new 创建对象指针(同时创建对象)
- 例如 sync.WaitGroup/sync.Mutex 其成员有计数功能,用指针可以避免成员变量发生拷贝
- make
map
- 未初始化(make)的 map 是一个 nil map,可以进行读取、range 遍历、delete、len 等只读操作,但是如果执行写入动作则会引起 panic。
- map 没有 clear 函数,可以直接重新 make 一个;Go 1.11 版本后,遍历 map 并 delete 所有元素的代码会被自动编译为了内置函数 mapclear 效率很高。
- 遍历 map 时,顺序是随机的。原本 map 在自动扩容前顺序是固定的,但是设计者为了避免调用者依赖这种脆弱的固定性,故意增加了随机性。
- map 创建时可以指定容量。可以通过 len 查询 map 的有效元素数量,用 cap 时会编译出错,因为 hash 的 cap 没有意义。
- 引用一个不存在的 key 的 value 会得到一个默认值,这与 C++容器的用法一致
- 在遍历 map 过程中,可以 delete 或修改当前元素,是安全的,并且可以正确执行,不会有错误影响
- map 的初始化方法:
map[string]string{}和make(map[string]string)是等价的 - map 的 key 可以是比较复杂的类型,只要这个类型是
可等于比较即可,比如Struct、Array都可以。例如:map[[256]int]int
关于 map 的传参
map 的初始化底层实现:func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap
本质上 map 的类型是*hmap,是一个指针,所以函数内外指向的是同一对象,set、扩容,都不会不一致。相当于 Go 语言在编译期在函数内部自动加上了*以使用指针。
这种用法相当于 C++中的引用。在函数内部直接对 map 参数赋值,只是改变指针指向,并不会修改函数外的指针(由于引用的只读性,前面不再自动加*)。
关于 map 自动添加*的处理,Ian Taylor 的回答是
In the very early days what we call maps now were written as pointers, so you wrote *map[int]int. We moved away from that when we realized that no one ever wrote map without writing *map.
func main() {
outMap := make(map[int]int) // 创建 map 对象 1
outMap[1] = 0
func(innerMap map[int]int) {
innerMap[1] = 1 // 修改 map 对象 1
innerMap = make(map[int]int) // 创建 map 对象 2,但并不影响 map 对象 1
}(outMap)
log.Println(outMap[1]) // 输出 1
}
下面以*hmap类型的视角解释上面发生的过程
func main() {
var outMap *hmap
outMap = make(map[int]int) // 创建 map 对象 1
func(innerMap *hmap) {
(*innerMap)[1] = 1 // 在前面自动加 *
innerMap = make(map[int]int) // 只是修改了函数内的参数指针值,并不影响函数外结果
}(outMap)
log.Println((*outMap)[1]) // 在前面自动加 *
}
map 元素无法取址
下面的使用将报错:
m := make(map[int][3]int)
m[0] = [3]int{}
x0 := m[0][0]
fmt.Println(x0)
// m[0][0]++ // 编译错误:cannot assign to m[0][0]
m1 := make(map[int]*[3]int)
m1[0] = &[3]int{}
m1[0][0]++ // 利用了数组自动加'*',可以直接赋值
type T1 struct {
a int
b string
}
m2 := make(map[int]T1)
m2[0] = T1{}
// m2[0].a++ // 编译错误:cannot assign to struct field m2[0].a in map
m3 := make(map[int]*T1)
m3[0] = &T1{}
m3[0].a++
map 元素是无法取址的,也就说可以得到m[0][0], 但是无法对其进行修改。
赋值符号=的左边必须是可取址的,map 内的元素可以被赋值,但元素本身是无法取址的,
所以m[0][0]+和m2[0].a++这种通过取址取得 field 的方式是不允许的。
因为 map 的扩容过程可能导致元素的地址发生变动,上面进行间接取址时候可能同时会发生对象地址变动,导致没赋值到目标对象上。
set
Go 中可以用这种方式实现 Set:
m1 := make(map[string]struct{})
m2 := map[string]struct{} {
"a": struct{}{},
"b": {} // 与 struct{}{} 等价
}
这样 Value 占用的空间为 0
struct{}表示存储空间为 0 的一种类型,用unsafe.Sizeof(xType)检查结果为0struct{}{}表示构造一个这种占用空间为 0 的对象,可以简写为{}-
其实在 Go 进程中全局只有一个这个类型的对象,这些对象应该只占用一个共同的空间,所以实例占用空间为 0
- 推荐上面
struct{}的 value 类型虽然节省容量,但是做存在判断时总要这样的语句if _, ok := m[key]; ok {...}, 如果用bool的 value 类型要更简单,并且可以放在更复杂的组合判断中,如if condition1 && m[key] {...}, 所以,如果不是对容量特别在意的,用bool的 value 类型实现更好
defer
- defer 作用于 groutine 的调用栈
- defer 在函数返回时开始执行,执行发生在 return 语句之后
- 多个 defer 以栈的形式执行,先进后出(先 defer 后被执行)
- defer 后边必须是一个函数调用,函数的参数是在 defer 语句入栈前就决定了值,如果参数中有函数调用,则在入栈前就会执行这个函数并把执行结果入栈
- 如果函数中调用 os.Exit(0) 这种方式退出程序,则 defer 将不被执行,因为没有按调用栈返回到 main 函数。
panic
panic 是一种异常机制,可能由空指针、下标越界、除0、interface单参数强转失败、主动调用func panic(interface{})函数触发。
panic 触发后,会作用于调用栈,持续向上层返回,期间调用 defer,直到遇到 defer 中的 recover 结束或直到该携程退出,进而整个程序退出。
- panic 只会作用于自己的 gorutine 栈,但是当自己的 gorutine 最终退出后,会导致整个程序 exit。其他携程就没有 defer 或 recover 机会了。
- panic 如果没有处理抛到 runtime 时,会打印下面信息:
- panic 的原因,比如空指针等
- 发生问题的 goroutine 编号
- 调用栈(从上到下打印,栈顶为发生问题点),包含了函数信息、代码行数
recover
在 defer 调用中执行func recover() interface{}可以终止一个 panic,其返回值就是最初 panic 时传入的参数。
- recover 同样作用于 goroutine 调用栈,所以不能 recover 其他 goroutine
- 由于 recover 作用域调用栈,所以必须放在 defer 后面的函数中执行
function
函数变量
函数是 Go 语言的”一等公民”,也是一种类型,所以可以定义一个函数变量,用来指向一个函数的实现,相当于 C++中的函数指针。
anonymous function(匿名函数)
在 Golang 函数中,可以随时定义匿名函数。
- 匿名函数的内部会形成闭包(Closure)结构,将其中用到的外部变量引用保留下来以备未来使用。
- 匿名函数可以直接赋值给一个函数类型的变量,以后通过这个变量调用,这样匿名函数就变成了有名函数。
匿名函数递归:
func test() {
reFunc := func(i int) {
if i > 0 {
fmt.Println(i)
return reFunc(i - 1)
}
return
}
}
上面的代码编译报错:”reFunc not declared”。
由于:=右边要先编译出来再赋值给左边,所以reFunc在右边函数定义中是未定义的。
可以用下面的函数变量(相当于 C++函数指针)的方法实现:
func test() {
var reFunc func(int) // 提前定义变量
reFunc = func(i int) {
if i > 0 {
fmt.Println(i)
return reFunc(i - 1)
}
return
}
}
函数参数的执行顺序
Go 的函数参数如果是函数,则按从左向右的方向顺序执行。 (C++是按照从右向左入栈)
func1 := func() int {
fmt.Println("func1")
return 1
}
func2 := func() int {
fmt.Println("func2")
return 2
}
func3 := func(a, b int) {
fmt.Println(a, b)
}
func3(func1(), func2())
/* 输出
func1
func2
1 2
*/
函数多返回值做参数
如果 A 函数返回值的类型、个数与 B 函数的入参一致,则可以有如下调用:
func A() (int32, float32) {
//...
}
func B(a int32, b float32) {
//...
}
B(A())
package
- 同级文件的包名不允许有多个
- 一般同级文件包名和所在文件夹一致,但也有例外,比如项目根文件夹下 main.go 中一般包名为 main
Package initialization
func init() {
// ...
}
- init 函数用于对包的初始化处理
- 一个包中可以有多个 init 函数,按照文件名先后执行 init 方法
- 一个
.go文件中可以重复定义 init 函数,执行时按照编写的先后顺序执行 - 在编译期决定,先执行导入包的 init 函数,再执行本包内的函数
- 一个包的 init 被执行过之后,在此程序中不会再被执行
- init 函数是一个特殊的函数,在编译期会用到其中的执行代码但并不会定义 init 这个函数名,所以无法被其他函数调用
- init 函数不论在什么位置定义,都可以调用全局变量,因为全局变量是在所有 init 函数之前初始化的
- 进程中 init 的执行都是在主携程完成的,涉及到哪些包依赖就会顺序执行。在 init 执行过程中,如果耗时较长,那主携程会一直处理完这个 init 函数再继续执行。
import
-
module 的版本号分三段
x.y.z,x 表示不兼容修改、y 表示兼容修改、z 表示 bug 修复等。- 注意当 module 的大版本号
x >= 2时,要在 import 时明确的在包结尾加上/vx以提醒使用者有大的版本兼容变化
- 注意当 module 的大版本号
-
module 名和版本号写在
go.mod文件中,可以被其它代码 import 使用- 不过 module 末尾是一个文件夹名,并不一定其中代码定义的 package 一致,所以可能发生这种情况:
import "github.com/ClickHouse/clickhouse-go/v2" // module 的末尾文件夹是clickhouse-go,v2是版本号 clickhouse.WithQueryID // 这里的 clickhouse 是 package 名
- 不过 module 末尾是一个文件夹名,并不一定其中代码定义的 package 一致,所以可能发生这种情况:
// import 的几种形式
import "lib/math" // 导入包名 math,用法 math.Sin
import m "lib/math" // 重命名包名 m,用法 m.Sin
import . "lib/math" // 全局导入包名,用法 Sin
import _ "lib/math" // 只导入包,执行 init 函数,不调用包的内容
import ( // 省略多个 import 关键字
"fmt"
"lib/math"
)
// 多版本导入
// 导入指定的版本,在使用时可以直接用 yaml.UnMarshal()
// 这里"gopkg.in"是一个网络文件夹,yaml是包名
// 从包名后缀可以看出,这是一个基于 go module 的版本导入方法
import "gopkg.in/yaml.v2"
// 这里的命名可以看出是使用 go module 前的导入方法
// 新版本要单独搞一个文件夹(package) "v2"
import "gopkg.in/yaml/v2"