
基本用法
- 在 shell 中执行
man cmdName可以查看帮助手册(如果有的话) -
同样,用
cmdName --help也可以查看帮助信息 cmdName -xyz --name- 可以用上面两种方式加 flag,有些 flag 后面可以跟参数
- 这种双
--符号后必须跟完整 flag 名--后如果有参数,可以以两种形式设置:- 等号
--output=yaml - 空格
--output yaml
- 等号
- 这种单
-符号表示缩写,后面每个字母表示一个 flag,如上面表示-x -y -z-后如果有参数,可以以三种形式设置:- 直接跟参数
-oyaml,前提是后面的yaml不包含其它 flag,不会引起歧义 - 等号
-o=yaml - 空格
-o yaml
- 直接跟参数
命令
进程相关操作
Ctrl+C
关闭程序(发送 SIGINT)
Ctrl+Z
暂停进程(发送 SIGTSTP)
Ctrl+D
输入 EOF
jobs
查看后台(运行/暂停)的进程
fg %###
将后台进程加载到前台运行
bg %###
在后台继续运行暂停的进程。如果要退出 terminal 时仍然运行后台进程,进程的输出要重定向,例如 xxx »tmp.log
硬件相关
fdisk
管理磁盘,进行分区、格式化等操作
fdisk -l
列出外围设备的分区表情况
mount
将磁盘分区挂载到 Linux 的一个文件夹下
mount -t vfat /dev/hdb5 /mnt/folder
将磁盘分区/dev/hdb5以vfat格式挂载到/mnt/folder文件夹
-tformat 指定格式
df
disk file system,查看磁盘和文件系统的信息,磁盘容量、挂载文件夹位置等
df -h
显示磁盘信息
-hhuman,以人类易读的方式显示磁盘容量
显示相关
history [n]
查看历史命令
[n]number,打印最近的 n 条命令-cclear,清空当前历史命令缓冲区-wwrite,将当前历史命令缓冲区写入文件。如果当前命令缓冲区为空则删除文件中所有历史命令-rread,将文件中历史命令读入当前历史命令缓冲区-aappend,将当前历史命令缓冲区续写入文件CTRL+R进入搜索模式,输入部分命令可以在历史中搜索
1 | |
clear
清空屏幕显示
xxx|more
通过命令行滚动查看执行结果。b 向前翻页,空格向后翻页
系统信息
whoami
查看当前使用的用户名
uname -a
查看所有操作系统信息
uname -m
显示架构信息
cat /etc/issue
查看 CentOS 系统版本
cat /proc/meminfo
查看内存信息
cat /proc/cpuinfo
查看 CPU 信息
切换为 root 用户权限 su // 相当于 su root su - root // 切换时,同时保持环境变量 在”/etc/passwd”中可以查看已经存在的用户及用户组
权限控制
chmod +x xxx/xxx
赋予文件可执行权限
chmod 755 ./xxx
改变文件权限为可执行可修改
chown username filefoldername
将某文件或文件夹授权给某用户
sudo xxx
以 root 权限执行命令
-u以指定的身份(默认 root)作为新的用户身份,保持 root 权限执行以后的命令。
touch ./xxx
更新一下文件的最新修改时间,如果文件不存在则创建一个文件
mkdir
mkdir xxx
创建一个文件夹
-p如果路径中的某些文件夹不存在,则自动创建
insmod 将文件安装到内核 通常是驱动。
md5
生成 md5 字符串,用于文件校验
md5 filename生成文件的 md5 字符串
date
date +"%Y-%m-%d %H:%M:%S"
打印当前时间
echo
将后边的文字显示在标准输出
echo -e "\a"
-e显示特殊字符"\a"报错声音”嘟嘟”声
ls
列出文件名
-a列出所有文件,包含以.开头的隐藏文件-l以列的方式显示,列出详细信息(权限、修改时间、软连接信息)-i显示 Inode Index 序列号-t按时间排序-v反向排序
ls xxx*
linux 很多命令输入文件名时都可以用通配符*,默认以字符串顺序排列
ll
相当于ls -l
du –apparent-size 显示当前文件夹空间以及各子文件夹空间
pwd 当前目录
反向显示列表内容 ll -t | tac
当前路径打开终端 ctrl+shift+t
复制 ctrl+insert 粘贴 shift+insert
查询命令帮助 man xxx
1 | |
find
查找文件
find root_path -name "abc*"
在 root_path 下按名字查找文件,其中*为通配符
-type d查找文件夹-newer xyz查找比 xyz 文件修改时间更新的文件
touch
更新文件时间,如果不存在则创建文件。
touch xxx
更新 xxx 的修改时间为当前时间
-t 201407201710.00更新到一个特定时间,如2014 年 07 月 20 日 17 点 10 分 00 秒
全盘定位文件 locate xxx locate -r xxx 正则查找
sudo updatedb
更新 locate 数据库
cat
concatenate 将文本连接并输出到标准输出
-n加行号
cat xxx1 xx2
查看文件文本内容,多个文件则顺序输出
cat > file1
将后面的用户输入写入文件中,以ctl+c结束
tac
和cat命令名正好反向,可以倒序显示文件的每行,行中的内容是正序的,只是多行之前倒序。
cat -n xxx.txt|tac|grep -m "error"
查找 log 中最新的 5 个 error 发生的行号
dig
查询域名相关信息
dig @ns1.google.com www.google.com
从指定的 DNS 服务器ns1.google.com查询域名www.google.com,其中 DNS 服务器可以填 IP 地址。
zcat
与 cat 类似,处理压缩文件
zcat xxx.gz
将压缩包解压后输出文本
more
more 功能类似 cat, cat 命令是整个文件的内容从上到下显示在屏幕上。 more 会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示, 按 b 键就会往回(back)一页显示,而且还有搜寻字串的功能。more 命令从前向后读取文件,因此在启动时就加载整个文件。
- more 的缺点是无法向前翻
less
以较小的缓存区读取文件,不需要全部扫描文件后再打开问文件,适合查看容量较大的 log。less 的最小操作单位和 grep 一样,以行为单位。
- 操作类似 vim
less xxx/xxx
打开文件查看
xxx |less
用 less 查看某个命令的执行结果,通常用于结果很长的情况
连续执行命令 xxx;xxx
管道,前面命令结果作为后面命令参数 xxxx | xxxx
whereis xxx 查找命令路径
which xxx 返回路径,同时可以判断 xxx 的类型,是 bin、函数还是 gems 等
cat xxx | grep error 查找某文件中包含 error 字符串的行
cat /etc/issue 查看操作系统版本
nohup
no hang up(不挂起),将当前命令的输出改为当前目录的 nohup.out 文件,避免在终端退出时程序中断
nohup Command [ Arg … ] [ & ]
在后台执行某个命令,重定向输出到 nohup.out
&通常要用这个参数使进程后台运行
ifconfig
查看 IP 信息
ifconfig en0
查看本地 IP
wall 广播一段文字消息,以 Ctrl+D 输入 EOF 结束符。
ln
link 创建一个文件或文件夹的链接,这样可以在修改一处时影响多处。
ln source target
创建一个硬链接,相当于不同文件名对应同一个文件。
-s创建软连接,相当于快捷方式
sleep
线程休眠一段时间
sleep 1 sleep 1s
休眠 1 秒
sleep 1m
休眠 1 分钟
sleep 1h
休眠 1 小时
command
执行一个命令或显示相关信息
command -v zsh判断当前命令安装位置(是否已安装)
ps
(process status)查看进程
-A/-e(All)显示全部用户的进程,默认只显示当前用户-f(full)显示全部字段信息a显示现行终端机下的所有程序,包括其他用户的程序u以用户为主的格式来显示程序状况。x显示所有程序,不以终端机来区分c列出程序时,显示每个程序真正的指令名称,而不包含路径、参数或常驻服务的标示
ps -ef|grep xxxx
查看特定进程
ps aux
查看进程内存使用情况
- Header 意义
- USER 进程的 Owner
- PID (process id)进程 id
- PPID (parent process id)父进程 id
- %CPU 占用 CPU 百分比
- %MEM 占用内存百分比
- NI 进程的 NICE 值,数值大,表示较少占用 CPU 时间
- VSZ (Virtual Memory Size)进程使用的虚拟內存量(KB),表示进程能访问的内存,包括 swap、动态库、已分配实际内存(包括未使用)
- RSS (Resident Set Size)进程使用的常驻内存容量(KB),表示进程占用的物理内存,包括 栈、堆、已加载到物理内存的动态库,不包含 swap
- TTY (Teletypewriter)该进程在哪个终端上运行,如果终端无关则显示
?,如果显示pts/0表示由网络连接启动 - STAT (state)进程状态,可能显示两位,后面表示附加子状态。
- I (Idle) 已 sleep 超过 20 秒
- R (Runnable) 可运行
- S (Sleeping) sleep 小于 20 秒
- T (sToped) 已停止的进程
- Z (Zombie) 僵尸进程,等待父进程回收 exit 值
- s (session leader)
- WCHAN (Wait Channel)进程正在阻塞等待的内存地址 event,如果正在运行(无阻塞)则显示
- - START 进程启动时间
- TIME 进程实际使用 CPU 时间
- COMMAND 命令和参数
ps -eo pid,lstart,cmd
查看进程准确启动时间
netstat -ntlp
查看进程端口使用情况,只显示端口号和进程 ID,需要结合ps aux命令查找进程名
- 注意,如果权限不足,不会显示进程 ID 及进程名称,需要 sudo 执行
lsof
查看 fd 占用情况
-p pid指定进程号
lsof -i :8080
list open files
查看指定的端口是什么程序占用
lsof -i tcp:8080
指定端口协议
lsof -i -P|grep pid根据 pid 查看端口连接情况
查看<系统设定>最大连接数
ulimit -n
内存总容量查询 free
运行某个”.sh”文件
1 | |
df
display free disk space
df -h查看磁盘剩余空间(Disk File)
du
disk use 查看磁盘使用情况
du -sh *
查看当前文件夹下各文件和文件夹的容量
du -s /usr/* |sort -nr
查看指定文件夹下各文件和文件夹容量高,并按从大到小排列,单位(KB)
env
查看环境变量
-v打印详细信息
sort
对多行内容排序
-
-uunique, 去重 -
-k2,1key, 每行为多个词组(以空白符分割)的情况下,先按第二列排序、再按第一列排序 -
-rreverse, 逆序排序 -
-nnumber, 把 key 作为数字来比较
top
查看排序后的进程使用情况,进入交互模式
交互模式命令:
qquit 退出s改变画面更新频率l关闭或开启第一部分第一行 top 信息的表示t关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示m关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示N以 PID 的大小的顺序排列表示进程列表P以 CPU 占用率大小的顺序排列进程列表M以内存占用率大小的顺序排列进程列表h显示帮助n设置在进程列表所显示进程的数量
启动开关:
-d num设置刷新间隔,单位秒-n num设置刷新采样 num 次后退出
top 命令显示的字段详解:
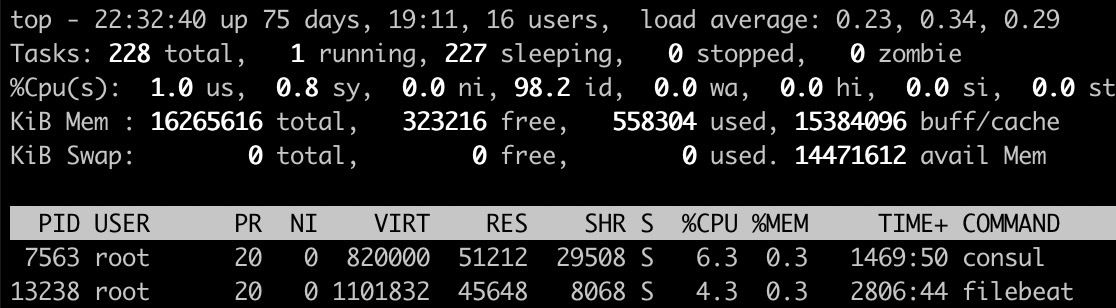
- 第一行(时间和负载)
22:32:40当前系统时间up 75 days, 19:11启动到现在已经有 75 天 19 小时 11 分钟(期间没有关机)16 users当前有 16 个用户登录系统load average: 0.23, 0.34, 0.29三个数分别是 1 分钟、5 分钟、15 分钟的 CPU 负载情况(总的等待进程队列长度)
- 第二行(任务)
- 任务的总数、运行中(running)的任务、休眠(sleeping)中的任务、停止(stopped)的任务、僵尸状态(zombie)的任务
- 第三行(CPU 耗时分配百分比,总和为 100%)
ususer: 运行(未调整优先级的) 用户进程的 CPU 时间sysystem: 运行内核进程的 CPU 时间niniced:运行已调整优先级的用户进程的 CPU 时间ididle:空闲时间waIO wait: 用于等待 IO 完成的 CPU 时间hi处理硬件中断的 CPU 时间si处理软件中断的 CPU 时间st这个虚拟机被 hypervisor 偷去的 CPU 时间
- 第四行(内存)
- 全部可用内存、空闲内存、已使用内存、缓冲内存
- 第五行(swap)
- 全部、空闲、已使用、可用交换区总量
- 第七行(各进程监控)
PID进程 IDUSER进程所有者名PR进程优先级NInice 值。负值表示高优先级,正值表示低优先级VIRTvirtual memory usage 进程的虚拟内存总量(包含未实际使用的容量),单位 kb。VIRT=SWAP+RESRESresident memory usage 常驻内存,驻留内存大小。驻留内存是任务使用的非交换物理内存大小。进程使用的、未被换出的物理内存大小,单位 kb。RES=CODE+DATA- 进程当前使用的内存大小,但不包括 swap out
- 包含其他进程的共享
- 只包含实际使用的内存容量
- 关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHRshared memory 共享内存- 除了自身进程的共享内存,也包括其他进程的共享内存
- 虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
- 计算某个进程所占的物理内存大小公式:RES – SHR
- swap out 后,它将会降下来
S这个是进程的状态D不可中断的睡眠态R运行态S睡眠态T被跟踪或已停止Z僵尸态
%CPU自从上一次更新时到现在任务所使用的 CPU 时间百分比。由于一个进程可能占用多核,所以可能大于 100。%MEM进程使用的可用物理内存百分比TIME+任务启动后到现在所使用的全部 CPU 时间,精确到百分之一秒COMMAND运行进程所使用的命令。进程名称(命令名/命令行)
stat
stat [文件或目录]
以文字的格式来显示 inode 的内容。可以查看文件的精确时间。
readlink
读取文件信息
readlink -f ./xx显示文件的绝对路径
reboot
重启系统,一般不轻易使用,需要有 root 权限。
重启等价于shutdown -r now
shutdown
关机
shutdown -h now
dirname
从路径字符串中提取最末的文件夹路径
把执行结果重定向到文件
cmd > file // 覆盖原有文件
cmd >> file // 追加到原文件后面
cmd 1> file // 只重定向 stdout
cmd 2> file // 只重定向 stderr
cmd 1,2> file // 同时重定向 stdout 和 stderr
cmd &> /dev/null // 抛弃所有的 log
cmd < file // 将后面文件作为前面命令的输入
cmd << endChar // 将终端输入作为前面命令的输入,直到终端输入指定的结束符endChar后结束
cmd <<<"test" // 将后面的字符串作为前面命令的输入
$? -eq 0 // 判断前面执行的命令是否成功,一般成功返回 0,失败返回 1
修改密码 passwd //修改当前用户密码 passwd name //修改 name 用户的密码
dpkg -i xxx.deb 安装.deb 包。
apt-get update //更新最新的软件版本列表 apt-get upgrade //将所有软件更新到最新版本,系统也可能升级 apt-get install xxx //安装某个软件
- 在
/etc/apt/sources.list存放着软件源,可以根据网络情况更新
zip/unzip
zip -r target.zip srcFolder
把源文件夹压缩到目标 zip 文件
unzip target.zip
解压文件到当前目录
poweroff 关机
date
查看系统时间
clock –show 查看硬件时间 clock –hctosys 将硬件时间应用到系统时间
timedatectl
查看设置时区
timedatectl | grep "Time zone"查看时区timedatectl list-timezones查看所有可用时区timedatectl set-timezone UTC设置时区为 UTC
tr
translate,转换或删除子字符串
tr 'str1' 'str2'把字符串中的 str1 替换为 str2
cp
cp -Rf /home/user1/* /root/temp/
将 /home/user1 目录下的所有东西拷到/root/temp/下而不拷贝 user1 目录本身。
即格式为:cp -Rf 原路径/ 目的路径/
- 有时
cp -f xxx仍然会出现覆盖提示,这是因为cp命令被重命名了,可以执行\cp强制执行原始命令
last -10 查看最后 10 次登录情况
iptables -nv -L 查看网络访问控制情况
kill
kill [-signalSeq] processId
向进程发送信号。在不设定信号序号时默认发送SIGTERM。
kill -l
显示可发送信号列表。共有 64 种信号可供使用。
- 常用信号:
-KILL/-9SIGKILL,强制杀死进程-HUP/-1SIGHUP,重新加载进程-TERM/-15SIGTERM,正常停止进程
pkill
与 kill 类似,可直接以进程名称为参数
pkill procname
pstree
以树状形式显示进程及其子进程,如果没有指定进程 ID 则显示所有进程
pstree
变量操作
set
设置环境变量
-e一旦脚本中发生返回值非 0 的情况,立刻停止脚本执行-x执行命令时,会先显示指令及其参数
export VALUE_NAME=${VALUE_NAME:-default}
${VAR_NAME}引用变量VALUE_NAME = ${VALUE_NAME:-$default}表示如果变量不存在,则用:-后面的默认值替代,如果存在则不作替换。这里 default 是另一个变量;如果没有$则是字符串
echo $VALUE_NAME/echo ${VALUE_NAME}
输出(环境)变量的值
unset VALUE_NAME
删除环境变量
xxx=111 yyy=222 cmd args运行命令时带临时环境变量
export
设置全局环境变量,即当前命令结束后,当前 session 仍然保持环境变量。
-
export查看现有的所有环境变量 -
export VALUE_NAME="value"设置环境变量,值可以放在双引号中;也可以不放在双引号中,但是不能有空格 -
export name1=value1 name2=value2一次性设置多个变量
命令相关操作
history
查看历史命令。
- 这些命令都被写到了
~/.bash_history中,可以用环境变量HISTSIZE设置保存的命令数。 - 按’上/下’按键可以查看历史命令
CTRL+R可以进入命令搜索状态,可以搜索历史命令- 在搜索过程中,再次按
CTRL+R可以在备选项间切换
- 在搜索过程中,再次按
文本操作
grep
Globally search a Regular Expression and Print 在文本、文件中查找符合通配符模式的文本行。
cat aaa | grep bbb
在 cat 命令结果的字符串中查找 bbb
grep -e "test.*" xxx.xx
在 xxx.xx 文件中查匹配test.*正则表达式的行,其中 xxx.xxx 文件名也可以使用通配符*
grep -vFf tmp1.txt tmp2.txt
在 tmp2.txt 中查找 tmp1.txt 的每一行,输出没有找到的部分。
-vinvert-match,查找没有出现目标文本的内容-h在结果中不添加文件名-o–only-matching,只输出完全匹配模式的部分-A nadd,增加匹配行后 n 行的显示-B nbefore,增加匹配行前 n 行的显示-C ncontext,增加匹配行前后 n 行的显示-ccount,只输出匹配的总行数-eregexp, 匹配正则表达式-Eextended-regexp,匹配扩展的正则表达式-mmax-count,控制输出的最大行数-n同时输出行号-ddirectory,以文件夹为目标进行搜索-rrecursive,递归搜索自文件夹-l只列出匹配的文件,不显示具体行-ffile pattern, 将文件中每行作为一个 pattern 用来做后续比较-Ffixed strings, 将 pattern 理解为固定字符串--color=auto搜索到的文字高亮显示
正则表达式
- 字符匹配:
- []: 指定范围内的任意单个字符
- [0-9], [[:digit:]] 数字
- [a-z], [[:lower:]] 小写字母
- [A-Z], [[:upper:]] 大写字母
- [[:alpha:]] 字母
- [[:alnum:]] 字母和数字
- [[:space:]] 空格
- [[:punct:]] 标点符号
[0-9]*0-9 的数字出现 0 次到多次\..出现一次[a-zA-Z0-9]多种分段的组合[123]匹配 1 或 2 或 3,只能匹配一个字符[^1]反向选择,匹配没有 1 的[^a-zA-Z]反向选择,没有字母的
- 次数匹配: 指定前面的字符出现次数
*任意次+1 ~ 多次.*任意字符出现任意次?0 次或 1 次\{m\}匹配其前面字符 m 次\{m,n\}匹配其前面字符至少 m 次,最多 n 次\{m,\}匹配其前面字符至少 m 次,最多不限\{0,n\}匹配其前面字符最多 n 次
- 位置锚定:用于指定字符出现的位置
"^test"定位行首为 test 的行"test$"定位行尾为 test 的行^$空白行\<char,\bchar词首为 charchar\>,char\b词尾为 char
egrep
相当于grep -e
egrep -e '(xxx|yyy)'
查询的两个内容为或的关系
awk
awk 可以遍历文件或标准输入的每一行,进行处理,功能强大。这里只列出与 grep 配合取出指定位置值的功能。
awk 'BEGIN{ print "start" } pattern{ commands } END{ print "end" }' file
一个 awk 脚本通常由:BEGIN 语句块、能够使用模式匹配的通用语句块、END 语句块 3 部分组成,这三个部分是可选的。
任意一个部分都可以不出现在脚本中,脚本通常是被 单引号 或 双引号 中。
-F "xxx"指定处理一行数据时的分割符,默认为" "- 分割符是正则表达式,可以用
-F "[, ]",同时把,和
- 分割符是正则表达式,可以用
-
分割之后,可以用
$1、$2…取得被分割后的每个子串,$0表示输入的整行内容 - 假设有
test.log文件内容如下:
xxx,id:123,xxx
xxx,id:456,xxx
- 执行命令
grep "id:" test.log|awk -F "id:" '{print $2}'|awk -F "," '{print $1}'可以得到输出:'{print $2}',表示取第一个"id:"分割符分割后的右半边'{print $1}',表示取第一个","分符分割后的左半边
123
456
全局变量
$1, $2表示第几个参数$0表示一行所有的传入数据NRnumber of record 行数NFnumber of field 多少个参数FNRfile number of record 当前文件的行数记录。如果多个文件,NR 记录所有文件行数。FSField seperator 列分割符 默认是” “(空白符)RSRcoerd seperator 行分割符: 默认是”\n”OFSOutput Field seperater 输出分隔符。默认是”\n”
print 子命令
print($1, " ", $2)在两个字符串中增加空格
if else 功能
在三个逻辑块中都可以使用 if 判断
awk -F " " '{ if ($1==1) print "A"; else if ($1==2) print "B"; else print "C" }'根据分割后的第一个子串打印不同内容,注意每个 if 语句以;结尾。其中else if是可选的,并且可以有多个。
变量
变量无需声明,直接使用。
- 如果为数,默认为 0
- 如果为字符串,默认为””
awk '{a += 1; print a}'
array/map 操作
awk 中的数组是关联数组(Associative Array),本质是一个默认顺序的 hashtable,其中 key 可以为 string 也可以为 int
-
awk -F " " '{ map[$1]=$3 } END { for (ele in map) { print (map[ele]);} }'用 map 做统计 -
{ delete array }删除数组 -
for (key in array) delete array[key];删除数组元素
利用 ++ 进行累加运算
awk '{ if ($1=1) a++; } END { print a; }'
xargs
可以捕获一个命令的输出(管道/stdin),然后传递给另外一个命令。 对前面的输出,xargs 可以将其分成多段传给新命令,避免新命令参数数量溢出;也可以将多行组合成一个命令的参数。
some command |xargs command
-I {}Interchange(替换),将输入替换后面的替换符,如|xargs -I {} grep "{}_xx" file,将传入的内容替换到后面{}位置-
-lline,将多行内容中间添加空格作为命令输入,如|xargs -l2两行内容合并作一行 docker images|grep "xxx.xxx.xxx"|awk -F " " '{print $3}'|xargs docker rmi删除指定 repo 下的所有 docker 镜像
wc
word, line, character, and byte count
wc -l filePath
统计文件的行数
cat tmp.log|wc -l
统计输入的文本的行数
-lline 统计输入的行数-ccharacter 统计字节数-mmultibyte characters 如果系统本地化支持多字节字符集,则统计字符数,否则退化为-cwword 统计单词数
head
截取文件最前面一段
head xx.file
-n count设定显示行数
head -c 2000 xxx.log
截取前 2000 行
tail
截取文件最后一段
tail 200 xxx.log
从 200 行开始显示,显示 200 行以后的
tail -n 200
显示最后 200 行
-
tail -20f xxx.log截取最后 20 行 -
tail -f xxx.log对最后的 log 内容保持监控
sed
stream editor,用脚本编辑文本文件。
sed -n '100,200p' filename截取文件第 100 行到 200 行
1 | |
- 批量替换指定文件夹下的所有文件内容,递归所有子文件夹
-i后的第一个字符串可以指定备份文件的名称,如果不想备份,可以指定为""
split
将文件拆分
-
split -b 100M filename "target_prefix_"拆分文件为 100MB 上限的多个文件,以字母aa/ab/ac作为后缀 -
cat target_prefix_* > filename将上面分割的文件合并为目标文件,由于后缀符合字母顺序,会自动按顺序合并
tailf
与 tail 功能相同,会从文件开头读起,并对末尾保持观察。
- 对于较大的文件 tailf 开始时候会较慢,因为 tail 会从末尾反向读取
- tailf 对文件没有增长的文件不会去读取,所以会较省电一点
tailf -20 xxx.log
从最后 20 行开始观察文件
tar
压缩文件夹 tar -zcvf /home/xahot.tar.gz /xahot –exclude=xxx tar -zcvf 打包后生成的文件名全路径 要打包的目录 要排除的目录名 tar –xvf file.tar 解压 tar 包 tar -xzvf file.tar.gz 解压 tar.gz tar -xjvf file.tar.bz2 解压 tar.bz2 tar –xZvf file.tar.Z 解压 tar.Z
diff
查看文件差异
diff file1 file2
显示两个文件的差异
远程通信
ping
-
ping domain/ipAddress以ipv4协议 ping 目标 ip 或域名,如果 ping 域名,则会自动域名解析 -
ping6 ipv6Address
curl
进行网络访问,可以支持各种协议、代理
curl http://www.baidu.com
访问网址,可以指定协议、ip 地址、端口号
--proxy socks5://localhost:9050通过代理访问--output/-o fileName输出 body 到指定文件--output -输出 body 到 console-D -输出 header 到 console
wget
拉取网页到文件
wget http://example.com/index.html
将在本地生成index.html文件
ssh
scp
基于 ssh 协议传输文件,会要求输入密码
scp [-r] source target
从源拷贝到目标
- 本地路径可以用绝对或相对路径表示
- 目标路径用
username@servername:/path表示 -r表示以文件夹形式传输
alias
设置/查看命令别名
alias查看有哪些命令被改写过alias l="ls -lah"给命令设置别名,简化操作
uniq
过滤整理文件中的重复行
uniq -ccount, 统计每行的出现次数,统计结果为行内容 出现次数-drepeated, 重复项只输出一次-uunique,是输出出现过一次的内容
bash 语法
顺序执行
xxx \<回车>
可以实现多行命令一起执行
grep "test" $( upstream command )
将$()内的执行结果替换到原位置
xxx1 | xxx2 | xxx3
|piepline(管道),表示左边(前边)执行的命令结果作为右边命令的参数传入,可以连续使用。
xxx1 & xxx2 & xxx3 ; wait
&符号左边的命令后台执行(多进程),一般最后要加一个wait,让 shell 主进程等待子进程执行完毕再退出,避免主进程过早结束导致子进程意外结束。
xxx1 || xxx2
或关系,表示上一条命令执行失败后才执行下一条命令。
xxx1 ; xxx2 ; xxx3
顺序执行多条命令。不管前面一条是否成功,都继续执行。
xxx1 && xxx2 && xxx3
与关系,表示上一条命令执行成功后才执行下一条命令。
xxx1 || xxx2 || xxx3
上一条命令执行失败后才执行下一条命令。
注释
1 | |
变量赋值
VALUE_NAME=value
给变量赋值,右边直接写值,字符串也可以直接写
VALUE_NAME=$(grep test testFile)
将命令执行结果作为值赋值给变量
1 | |
字符串
shell 中的字符串与脚本命令之间不像 C++那样”隔绝”,往往可以自由的切换使用,所以需要搞清什么时候是字符串、什么时候是执行的命令。
- 字符串常量表示方法:
'单引号,用于保留字符的字面含义,特殊字符不做转换,例如* $ \- 单引号字符串中不能再使用单引号,如果要使用,需要在外层单引号前加上
$,然后再对里面的单引号进行\'转义
- 单引号字符串中不能再使用单引号,如果要使用,需要在外层单引号前加上
"双引号,比较宽松,其中的`、$、\三个字符会被 Bash 自动扩展。$用于引用变量;`用于执行子命令;\反斜杠用于转义;
`反引号,调用命令或者将命令的输出赋予变量,则必须使用反引号包含命令,这样命令才会执行。- 反引号的作用和
$(命令)是一样的
- 反引号的作用和
调用参数
在命令行调用脚本文件时,可以在后面传参,例如./my.sh p1 p2,然后在脚本中可以用一些符号表示参数。
$#
表示参数个数
$0
被执行的脚本本身的文件路径
$1
传入的第一个参数。$2、$3…表示后面的参数
条件判断
1 | |
- 注意,在字符串比较时,
=或==都可以判断相等,但是两边的字符串值一定要与=间有空格,否则会被识别为赋值,永远为真 - 在字符串比较时,往往需要字符串变量相比较,这时候最好变量外边加上
",以免字符串内容是空格隔开的多段字符,会报[: too many arguments错误 - 复杂条件:
if [[ condition1 && condition2 ]] || [[ condition3 ]]
如果文件存在,则删除该文件。
1 | |
循环
数字循环
1 | |
每行文本内容循环
for do done
1 | |
数组
array_name=(ele1 ele2 ele3 ... elen)
数组元素类型不确定,下标从 0 开始
nums[6]=88
为某个下标元素赋值
echo ${nums[3]}
输出一个数组元素
echo ${nums[*]}或echo ${nums[@]}
输出所有数组元素
数组元素循环:
1 | |
特殊变量
$?最后一条命令的 exitCode,正常退出是 0,130 使用ctrl+c退出的
应用场景
查找特定时间之后创建或修改的文件
1 | |
查找某 log 中 2000 行之后的匹配项
tail 2000 xxx.log|grep "test"
查看某进程的限制信息
cat /proc/<pid>/limits | grep 'Max open files'
常见错误
执行自己的脚本bash xxx.sh时报错Bad Substitution
- 手动执行命令正常,以脚本运行时报错
-
如果查看底层文件,发现
bash只是dash的软连接,而dash解释器有些操作是不支持的 chmod +x xxx.sh&& ./xxx.sh就可以解决