goroutine 是 Go 最核心的特性。为什么它可以比多线程效率更高?底层的实现机制是怎样的?
进程、线程对 CPU 利用的瓶颈 —— 用户态内核态切换
进程是资源的单位,与其它进程相隔离,有独立的 IO、堆、栈,多个进程之间受操作系统调度。
线程是真正执行的单位,在同一个进程中多个线程共享文件、堆等进程资源,但是有独立的栈。在多 CPU 硬件下,每个 CPU 可以运行一个线程,如果存在多个线程,则由系统负责调度。
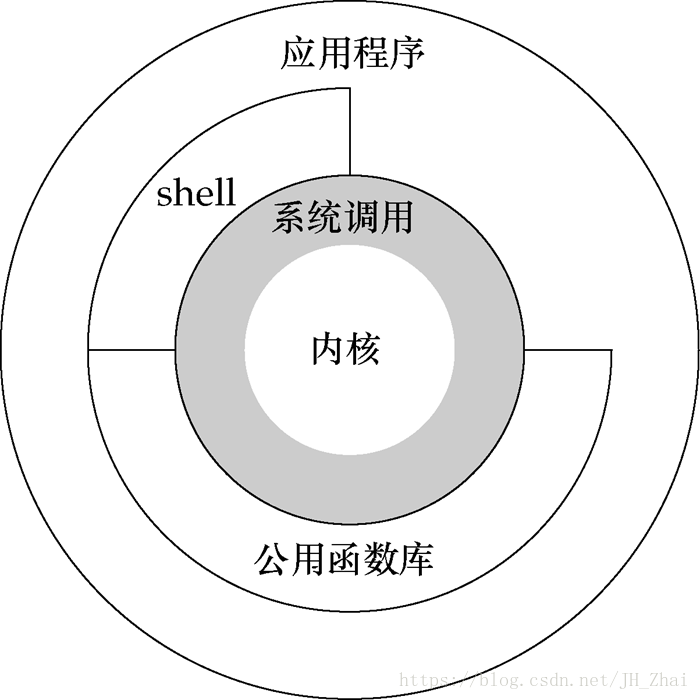 对于任何一个进程,都有两个栈,一个用户态栈、一个内核态栈,其中用户态栈是我们的代码运行的空间,但是只凭我们的代码很多操作无法执行。
对于任何一个进程,都有两个栈,一个用户态栈、一个内核态栈,其中用户态栈是我们的代码运行的空间,但是只凭我们的代码很多操作无法执行。
操作系统内核为我们提供了存储、IO、硬件中断、软中断等功能。当我们进行系统调用时,就会进行用户态和内核态的切换。这个切换过程主要是对用户态的寄存器进行保存,另外由于内核态的 CPU 权限较高也会进行额外的安全检查。在内核态执行完毕后,再进行切换,转为用户态。
上面的切换过程,就会导致 CPU 效率的下降。另外,由于系统调度,运行了一段时间的线程会被主动切换成另一线程,这个过程并没有增加总的 CPU 使用率,反而降低了总效率,只是看起来单个线程没有死掉。
协程的改进点
协程是协作式调度而不是抢占式调度。
在线程进行耗时操作时(如 IO 操作),就会发生上下文切换,当前线程被挂起。等待 IO 操作返回后,当前线程进入 Ready 状态等待调度启动。
协程是在线程基础上实现的,也面临相同的问题,在进行 IO、channel 等耗时操作时,也需要进行状态切换进入等待状态。但是为了避免发生用户态和内核态的耗时切换,在 Go 的 Runtime 支持下,goroutine 可以主动放弃当前的线程占用给 gorutine 调度器,同时进入 IO 返回等待状态,等返回之后,再进入队列等待调度。
由于这种主动的切换寄存器、缓存的 context 的容量成本非常低,goroutine 是 4K 而线程大于 1M(200 多倍),所以切换损耗特别小,能够充分的利用 CPU。
规律:进程、线程、携程,切换时维护的栈容量越来越小、距离用户态越来越近。
服务器的常见实现方式(Go 协程的演化)
多线程(进程)阻塞 IO
为每一个用户的连接创建一个线程,或使用线程池避免创建和销毁线程的开销。线程中进行网络 IO 操作时会发生阻塞,这时候线程 A 会切换进入内核态、线程 B 被内核态唤醒切换进入用户态然后执行、接着又可能发生阻塞切换…
这种方式的优点是逻辑简单,在线程函数内只要按照业务逻辑顺序考虑就可以。典型的就是 Tomcat 服务器,QPS 只能达到千级。
在并发量不大的情况下,这种由于 IO 阻塞引发的切换损耗并不明显。但是在高并发情况下,CPU 由于不断切换,性能会急剧下降。所以要想实现高并发,必须用无阻塞的方式实现。
单线程非阻塞 IO
使用单线程处理所有用户连接,对 IO 进行非阻塞的访问(如果无数据则立刻返回)。每个用户的不同阶段要注册对应的回调函数,在该用户的 IO 有数据的情况下就调用回调函数处理,然后再等待其他 IO 有数据的时候进行回调。
由于不存在阻塞,所以执行效率特别高。只有在所有 IO 都没有数据的情况下才会利用 epoll 进行等待,而这个效率也是很高的。这种方式可以应对较大的并发,典型的服务器有 Nginx、Redis、Libevent 库,QPS 能达到 10 万级。
但是这种方式有两个缺点:1.没有充分利用所有 CPU。2.逻辑较复杂,由回调函数和状态切换组成。
单线程协程
其实协程的概念很早就被提出,也有过很多实现,就是为了解决单线程非阻塞 IO 的逻辑复杂问题。
其实在上面的方案中对于每一个用户的请求,可以仍然使用一个函数执行,但是需要一个额外的数据结构保存函数运行的上下文(栈、寄存器),然后根据 IO 情况进行主动的切换调度,就可以同时满足非阻塞、高并发、逻辑简单。
但是这些协程实现普遍只利用了一个 CPU,没有充分利用资源。如果要利用多 CPU,需要自己启动多个进程进行协调。
Go 的 GPM 模型
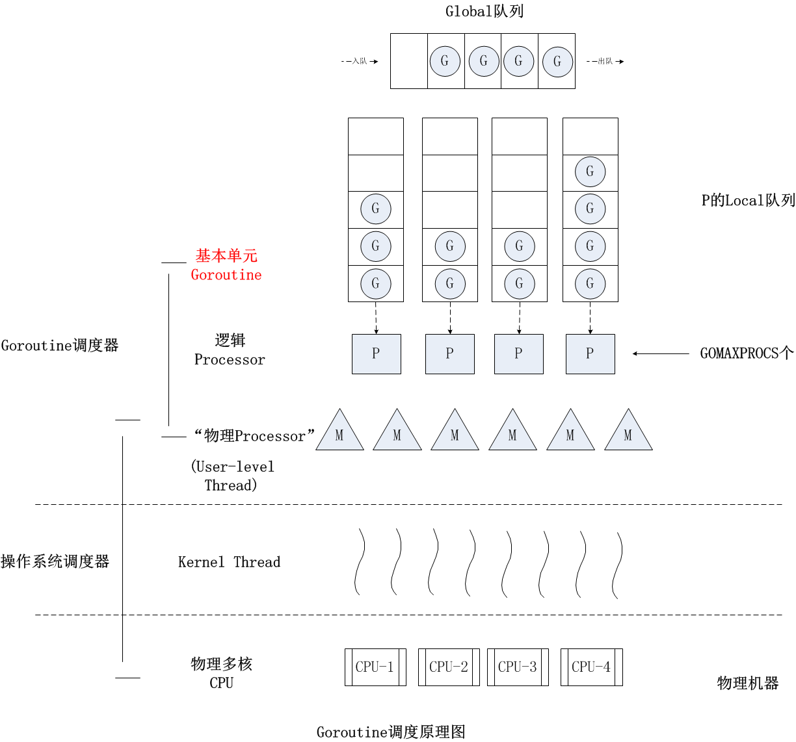 Go 的 GPM 模型,其实就是单线程协程的改进版,可以同时利用多个 CPU 实现协程调度。这样同时具有了 CPU 密集和 IO 密集的运算能力,同时逻辑实现也简单。
Go 的 GPM 模型,其实就是单线程协程的改进版,可以同时利用多个 CPU 实现协程调度。这样同时具有了 CPU 密集和 IO 密集的运算能力,同时逻辑实现也简单。
G(Goroutine) 是应用层代码开启的 goroutine
M(Machine) 是 Go Runtime 自动开启的线程,具体数量取决于 CPU 核数和 goroutine 数量,动态创建,实际数量往往要多于 CPU 数量(最大 10000),多个 M 构成线程池
P(Process) 是 M 上调度 G 运行的一个中间层,是 CPU 的抽象,所以一般 P 的数量与 CPU 核数一致,可以调用 runtime.GOMAXPROCS(num)执行,程序运行后不再改变
RQ(RunQueue) 最上面有一个总的队列
在每一个 P 上,对应着一个 G 的队列。
M 是真正的执行线程,P 在执行时会唤醒一个 M,然后拿所属的一个 G 来执行。
在遇到等待时(IO 无数据),M 对应的上下文(栈、寄存器 SP、PC 等)会保存到 G。如果此时 G 没有执行完,会被重新放到 P 的任务队列中等待下次被调度,然后通过 P 寻找其他可执行的 G,通过 G 中保存的数据恢复上下文然后继续执行。
如果 M 被阻塞,P 会与 M 分离(handoffp),G 继续与 M 绑定。P 会去唤醒或创建其他的 M 继续执行其他的 G。等 M 阻塞结束后,绑定的 G 会被重新放入总队列。这种情况会发生用户态内核态切换,并且可能要创建新的线程,所以代价也会较大。在使用时应考虑到,避免大量并发阻塞导致线程数暴增。
- 不会阻塞 M 的操作: _ 网络 IO _ 锁 _ channel _ time.sleep
- 会阻塞 M 的操作: _ 本地 IO 调用 _ 基于底层系统同步调用的 Syscall * CGo 方式调用 C 语言动态库中的调用 IO 或其它阻塞
Goroutine 的早期演化
-
初期的 Goroutine 调度器相较于之前的线程(或携程),有如下优化:
- 栈占用优化,初始只有 2KB
- 灵活调度,切换成本低
-
以前版本(Go1.0)的模型中是没有 P 的,垂直队列直接与 M 绑定,没有全局队列。 这样的缺点是如果 M 上运行的 G 阻塞了,那么后边的 G 都要等待,虽然存在”偷取”机制,但是还是会浪费一些时间。
调度器的设计策略
-
每个 M 创建的时候会绑定一个G0,这个 G0 是专用于调度的,不会用来执行可执行函数。在调度时,会先切到 G0 来调度。
- 对应的线程函数是
schedule。 - G0 的栈是直接分配在 M 上的,这样足够大,以便调用一些特殊函数
- 对应的线程函数是
-
进程启动是
main goroutine会启动一个监控线程sysmon,它是一个非工作线程,不参与 GPM 模型。 它根据监控情况自己调整休眠时间,通常每 10ms 会检查一次。- 监控任务有:
- (超时的)timer 执行
- (为降低网络延迟)netpoll
- 调度运行时间超过 10ms 的 G
- 为因为 M 阻塞而空出的 P 创建新的 M 执行
- 强制执行 GC
- 调度运行时间超过 10ms 的 G 的原理,向对应线程发一个 signal 触发
schedule
- 监控任务有:
-
Working Stealing机制 当本线程无可运行的 G 时,总队列也没有 G,会尝试从其他线程绑定的 P 偷取 G,而不是销毁线程
-
Hand Off机制 当本线程因为系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行
-
如何解决网络阻塞造成的用户态内核态切换? Go 的 netpoll 模块实现了这个功能。利用 epoll,在 send 和 receive 时利用非阻塞进行前置检查, 如果发现没有数据,则通过 CAS 机制设置一个 epoll 等待,将 goroutine 挂起,然后执行其他 goroutine。 为了避免误过 epoll 通知,G0 每 10ms 会轮询一次。
timer 的设计
每个 P 都有个最小堆,存储要触发的 timer 的时间戳。
当有 G 调用 sleep 时被挂起,当到时间时 P 将 G 状态改为 runable 并放入 run queue。
每次执行调度函数schedule时,都会检查一下是否有 timer 到期。
如果所有 M 都忙,可能会导致 timer 偏差较大,所以 G0 还有个职责,就是检查 timer 到期,调整线程执行,确保 timer 被及时执行。
调度协调
Go 1.14 增加了一种异步调度机制,避免 G 中有 for 循环(其中无可调度机会)导致卡死的问题:
为了防止一个 G 始终占用 CPU,每过 10ms sysmon 会调度一次,判断 P 中记录的当前执行 G 的执行时间,如果超过 10ms 则向该线程发送一个特定 SIG,之后就会触发调度。
- 具体流程:
- M 注册一个 SIGURG 信号的处理函数:sighandler。
- sysmon 线程检测到执行时间过长的 goroutine、GC stw 时,会向相应的 M(或者说线程,每个线程对应一个 M)发送 SIGURG 信号。
- 收到信号后,内核执行 sighandler 函数,通过 pushCall 插入 asyncPreempt 函数调用。
- 回到当前 goroutine 执行 asyncPreempt 函数,通过 mcall 切到 g0 栈执行 gopreempt_m。
- 将当前 goroutine 插入到全局可运行队列,M 则继续寻找其他 goroutine 来运行。
- 被抢占的 goroutine 再次调度过来执行时,会继续原来的执行流。
一些设计点
-
当 goroutine 较多时,Runtime 会创建很多线程 M。当这些 G 执行完毕后,线程仍然不会释放,等待以后的执行。
-
当 P 对应的队列处理完后,就会从总队列取 G。如果总队列没有,则会去其他的 P 对应的队列中”偷取”,一般会偷一半过来执行。这样避免出现线程空闲。
-
新创建的 G 会优先放在当前 P 的本地队列中(本地队列最大排队 256 个 G),如果满了则放到全局队列
-
在有些情况下,程序段会一直占用 CPU 而不进入内核调用(纯计算),会导致 G 一直占用 CPU,妨碍了调度。可以主动添加
runtime.Gosched()增加调度机会。 -
Go 新增了一种主动协调调度机制,就是在 goroutine 的栈扩容时(2KB~1GB),检查一下自己的 flag,判断是否要主动让出执行权。
-
由于 goroutine 的栈容量只有 2KB,所以在数量级可控的情况下,可以启动大量 groutine 降低逻辑复杂度。不过要注意,多线程可能造成逻辑复杂,所以增加数量的同时要控制携程内的复杂度。
-
为什么 Go 可以实现栈扩容而其他语言不行? 因为指针,这些指针指向的栈上的地址是固定的,如果要实现动态扩容,就需要追踪所有指向栈上的指针,所以需要一个 Runtime。理论上 Go、C#、Java 都是可以的。
其他
- 可以利用 trace 工具用可视化的方式查看 G P M 的执行 trace,其中的 G 是有内部编号的。
-
在启动时利用命令
GODEBUG=schedtrace=1000 ./xxx可以打印 goroutine trace 信息到 console,其中1000表示快照间隔毫秒数 - 关于是否使用携程的思考:
“多线程 NIO”的性能其实比”多线程携程”更高一点,由于两者在阻塞时都需要切换环境,”多线程 NIO”切换处理状态、”多线程携程”切换调用栈,
而”多线程 NIO”更直接一点,所以效率更高。但是由于逻辑被分散写在多处,容易出错,大大提高了编码门槛;而”携程”只用一个顺序逻辑就能写成,
逻辑相对简单,维护的状态少也不容易出错。
- 对于效率要求更高而逻辑相对较低的项目,适合”多线程 NIO”
- 对于项目规模较大逻辑复杂的项目,适合”多线程携程”
PS:
协程并不是Go的专属,并且存在多种实现版本,Lua等语言都实现了协程,golang team成员之一的Russ cox在加入golang team之前用C实现过协程。
源码,中文注释版本
(转)漫画:什么是协程?
(转)C 语言实现协程